Ceph:ceph被称为面向未来的存储还是一个分布式的存储系统,非常灵活,如果需要扩容,只要向ceph集中增加服务器即可。ceph存储数据时采用多副本的方式进行存储,生产环境下,一个文件至少要存三份,ceph默认也是三副本存储。
可以实现的 存储方式:
块存储:提供像普通硬盘一样的存储,为使用者提供“硬盘”。
文件系统存储:类似于NFS的共享方式,为使用者提供共享文件夹。
对象存储:像百度云盘一样,需要使用单独的客户端。需要编写代码。
Ceph存储集群至少需要一个Ceph监视器、Ceph管理器和Ceph OSD(对象存储守护程序)。运行Ceph文件系统客户端时需要Ceph元数据服务器。
Ceph Monitor(ceph-mon)监视器:Ceph Mon维护Ceph存储集群映射的主副本和Ceph存储集群的当前状态,监控器需要高度一致性,确保对Ceph存储集群状态达成一致。维护着展示集群状态的各种图表,包括监视器图、OSD图、归置组图、和CRUSH图。少数服从多数,至少一半以上
Ceph OSD 守护进程:Ceph OSD用于存储数据。此外Ceph OSD利用Ceph节点的CPU、内存和网络来执行数据复制、纠错代码、重新平衡、恢复、监控和报告功能。存储节点有几块硬盘用于存储,该节点就会有几个osd进程。
MDS:Ceph元数据服务器(MDS)为Ceph文件系统存储元数据。
RGW:对象存储网关。主要为访问Ceph的软件提供API接口。
搭建ceph集群:
node1:eth0->192.168.88.11
node2:eth0->192.168.88.12
node3:eth0->192.168.88.13
client1:eth0->192.168.88.10
为node1-3添加额外2块20GB的硬盘

在192.168.88.240的主机上配置Ceph镜像的yum源。通过vsftpd服务提供网络yum源。



创建ceph的ansible工作目录


配置ceph.repo


centos.repo


编写yum剧本


执行剧本
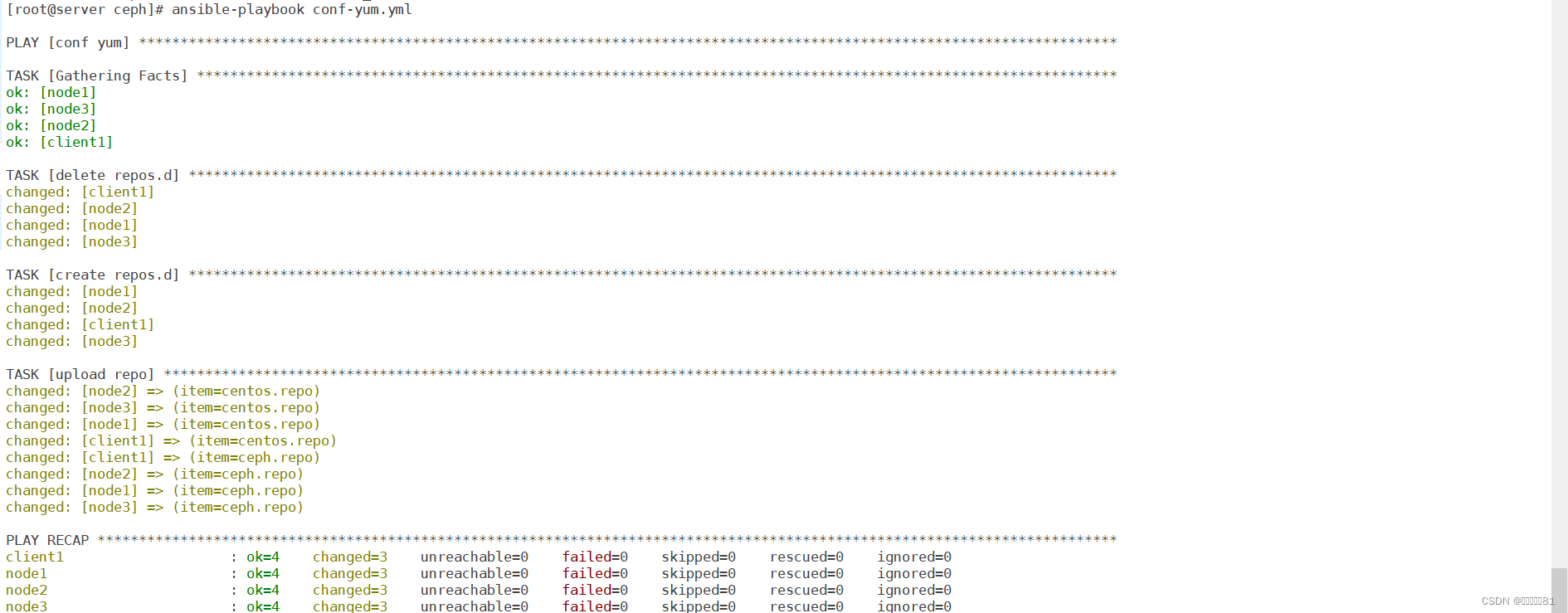
查看yum

关闭各个节点的防火墙和SELinux


ceph为我们提供了一个ceph-deploy工具,可以在某一节点上统一操作全部节点。将node1作为部署节点,将来的操作都在node1上进行,需要node1能够免密操作其他主机。


在所有的主机上配置名称解析。


blockinfile模块:几行字符串为一块出现在文件中。


执行剧本

查看hosts文件,所有节点都配置了名称解析


安装集群,在三个节点上安装软件包
可以在node1上通过ssh node{1..3} yum -y install ceph-mon ceph-osd ceph-mds ceph-radosgw
使用ansible剧本安装软件包


查看软件包

配置ntp服务器,让服务器时间同步

编辑/etc/chrony.conf文件

allow允许访问的主机

启动服务

让节点安装chrony

编辑chrony配置文件,把server开头的全部注释掉添加NTP服务器(Ctrl+v、I、编辑、ESC)

把该文件拷贝到其他节点

重启各个节点的时间服务器

查看是否配置成功

在node1节点安装ceph-deploy部署工具

查看使用帮助,ceph-deploy --help
创建目录ceph工作目录

创建一个新集群 ceph-deploy new node{1..3}
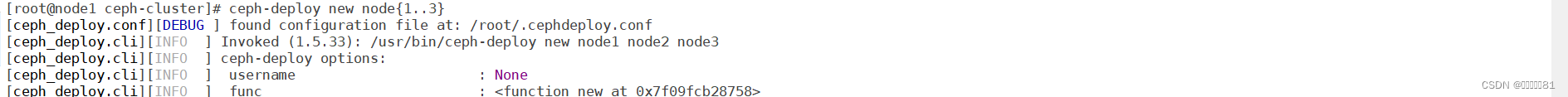
ceph.conf:集群配置文件
ceph-deploy-ceph.log:日志文件
ceph.mon.keyring:共享密钥

编辑集群配置文件,开启块存储的默认特性开启快照功能。rbd_default_features = 1


初始化Monitor。 ceph-deploy mon create-initial

如果安装错误可以清理数据重新安装:ceph-deploy purge node{1..3}
查看ceph-monitor服务

查看ceph集群状态。ceph -s 。因为还没有硬盘,所以状态是HEALTH_ERR

在执行ceph-deploy时要做ceph的工作目录中执行。查看disk命令

初始化各主机的硬盘。 ceph-deploy disk zap node1:sdb node1:sdc



查看osd命令
创建存储空间,ceph会将硬盘分为两个分区,一个分区大小为5GB,用于ceph的内部资源,另一个分区是剩余的全部空间。 ceph-deploy osd create node1:sd{b,c}




查看ceph的状态。
monmap:Monitor组件,只要有两个就表示正常。
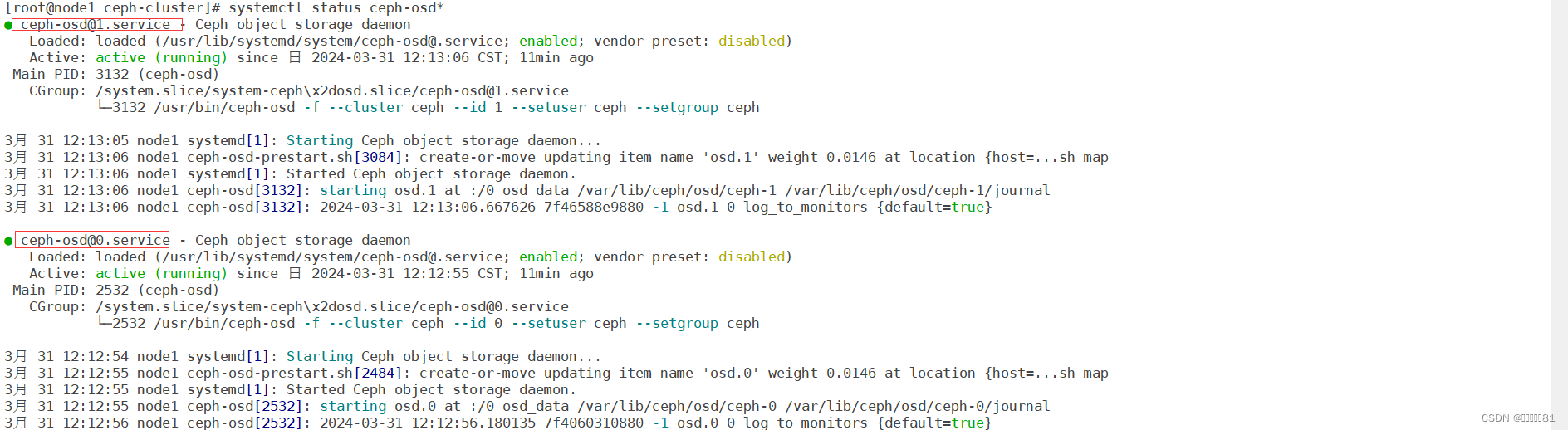
osdmap:硬盘组件。每一个硬盘osd就会开启一个守护进程。6块硬盘所以有6个osds。

node1上有两块硬盘所以有0、1进程,而node2/3则是2345进程
块设备存储数据时可以一次存取很多,字符设备只能是字符流。

使用rbd命令操作每个磁盘剩余的15GB内存,在node的每个节点都能操作该命令。
查看存储池。ceph osd lspools。rbd为存储池的名称

ceph df:查看详情,全局有90G而存储池只有30G,因为ceph存储文件要存储三个副本。

查看存储池的副本机制。ceph osd pool get rbd size

在node1上创建磁盘的使用空间(镜像)。rbd命令。

rbd create demo-image --size 10G

此时在node2和node3中也能看见该镜像。

查看镜像信息。 rbd info demo-image

修改改镜像大小。rbd resize --size 15G demo-image

此时该镜像已经变为15G

缩减时需要加上--allow-shrink
当创建100G的镜像时能够成功创建,但能够使用的内存容量只有30G,超过30G就会报错

删除镜像。 rbd rm img01

客户端使用快设备步骤:
1、要安装ceph的客户端软件才能使用。
2、ceph集群的位置,通过配置文件说明集群地址。
3、授权。让客户端能够访问该ceph集群。
安装ceph客户端软件。 yum -y install ceph-common

此时连接不了集群需要将配置文件和密钥keyring文件拷贝给客户端


此时client1就能使用rbd命令

此时在客户端也能创建镜像

客户端使用rbd命令操作的是ceph使用node1节点删除该镜像此时客户端上也没有了该镜像。


让镜像变成本地硬盘。rbd map demo-image:映射为本地硬盘,不能多次映射。


此时就能使用该硬盘格式化挂载使用。

查看映射的本地硬盘。rbd showmapped

卸载该使用的镜像

快照:可以保存某一时间点时的状态数据。希望回到以前的一个状态,可以恢复快照
创建img1镜像并映射为本地硬盘,然后格式化挂载


查看img1的快照。rbd snap ls img1

创建img1快照。rbd snap create img1 --snap img1-snap1

删除快照。rbd snap remove img1 --snap img1-snap1

取消挂载、取消映射的本地硬盘、删除镜像

快照实验:
创建镜像然后把该镜像挂载到客户端。


向/mnt中写入数据

创建快照

把/mnt中的数据删除

此时需要恢复快照就先停止映射本地硬盘,防止在恢复快照的时候有数据加入该硬盘

恢复快照,回滚img1到快照img1-snap1。rbd snap rollback img1 --snap img1-snap1

重新挂载,此时不需要格式化。查看目录,恢复到了被删除前、创建快照的状态。

保护快照误删除。rbd snap protect img1 --snap img1-snap1

此时就不能随便删除快照了

当多个节点同时挂载就会产生存储脑裂,数据发生混乱。
在client1创建myimg1镜像挂载写入数据

在node1映射myimg1镜像挂载写入数据

client和node分别写入数据


然后取消重新挂载,此时就发生了脑裂,hosts文件消失了,发生了数据混乱


快照克隆:不能将一个镜像同时挂载到多个节点,如果这样操作将会损坏数据。如果希望不同的节点,拥有完全相同的数据盘,克隆是基于快照的,不能直接对镜像克隆。快照必须是受保护的快照才能克隆。
克隆流程:镜像->快照->受保护的快照->克隆的镜像
创建镜像克隆
创建名为img2的镜像,大小10GB

向镜像中写入数据
卸载镜像

为img2创建名为img2-snap1的快照,并保护起来

克隆镜像。 rbd clone img2 --snap img2-snap1 img2-snap1-1

在客户端挂载该克隆镜像

而挂载另一个克隆镜像时就会报错

这是因为这两个克隆镜像,克隆的是同一个镜像,该UUID(全局唯一标识符)相同,无法挂载相同设备两次。

当在其他节点挂载另一个镜像时就没有问题,一个设备只能挂载一个唯一的UUID。

查询镜像和快照
rbd snap ls img2:列出该镜像所有快照

rbd info img2 --snap img2-snap1:查看该镜像的快照信息。protected:true受保护。

该img2-snap1-1的镜像的父亲是rbd池中的img2镜像的img2-snap1快照
 合并克隆镜像,将父镜像中的内容拷贝到克隆的镜像,然后和父镜像断开联系,独立为一个单独的镜像。
合并克隆镜像,将父镜像中的内容拷贝到克隆的镜像,然后和父镜像断开联系,独立为一个单独的镜像。
查看镜像内存。rbd du img2

合并镜像:rbd flatten img2-snap1-1。内存容量增加。

查看合并镜像信息,此时parent父镜像也消失 了

如果要删除img2镜像就需要先把克隆的镜像删除,然后再取消受保护的快照,并且删除快照,最后删除镜像。
1、只删除有快照或者克隆的镜像删除失败,提示有快照未删除。rbd rm img2

2、查看img2有那些快照: rbd snap ls img2

3、删除快照:rbd snap remove img2 --snap img2-snap1。提示快照受保护。

4、取消快照保护:rbd snap unprotect img2 --snap img2-snap1。提示有子镜像

5、查看有那些子镜像:rbd children img2 --snap img2-snap1

6、删除子镜像:rbd rm img2-snap1-2。提示子镜像正在被使用

7、查看子镜像正在被那个主机使用:rbd status img2-snap1-2

8、取消192.168.88.10主机上img2-snap1-2镜像的使用。查看该主机的映射本地硬盘,取消映射(如果有挂载先取消挂载)。

9、然后就能删除子镜像、取消受保护的快照、删除快照、删除镜像。

此时把img2主镜像删除了而之前的克隆镜像img2-snap1-1中还有数据能正常使用

ceph文件系统:文件系统相当于是组织数据存储的方式,格式化时就是在为存储创建文件系统。Linux对ceph有很好是支持,可以把ceph文件系统直接挂载到本地。要想实现文件系统的数据存储方式,需要有MDS组件(元数据服务器)。
数据相当于文件的内容(如cat查看文件),元数据相当于文件的属性(stat查看文件)。

在node3节点安装MDS:yum -y install ceph-mds

在node1的ceph-cluster目录通过ceph-deploy命令配置node3主机的MDS服务:
ceph-deploy mds create node3

查看node3的MDS服务

元数据就是描述数据的属性。如属主、属组、权限等。ceph文件系统中数据和元数据是分开存储的。
新建存储池:归置组PG:存储池包含PG,PG是一个容器,用于存储数据。为了管理方便,将数量众多的数据放到不同的PG中管理,而不是直接把所有数据扁平化存放。通常一个存储池中创建100个PG。
创建ceph文件系统:
1、创建一个名为data1的存储池,用来存储数据,有100个PG:ceph osd pool create data1 100

2、创建一个名为metadata1的存储池,用来存储元数据。 ceph osd pool create metadata1 100

查看存储池:ceph osd lspools

存储池的最大内存显示30G是因为潜在内存最大为当其他存储没有使用时全部的内存空间30G。

要删除存储池:ceph osd pool delete name name --yes-i-really-really-mean-it
3、创建文件系统new后面第一个表示要创建文件系统的名字,第二个存储池用来存储元数据,第三个存储池用来存储数据,创建完查看存储池
ceph fs new myfs1 metadata1 data1

查看文件系统: ceph fs ls。metadata pool:元数据池为metadata1,data pool:数据池为data1。

4、挂载文件系统需要密码,查看/etc/ceph/ceph.client.admin.keyring

-t:指定文件系统类型。-o:是选项,提供用户名和密码。cephfs的端口号默认是6789

mount -t ceph -o name=admin,secret=AQCn3Qhmt+9zARAAv60ERLf6OQN0Lefai277DQ== 192.168.88.13:6789:/ /mydata。ceph是一个整体挂载11,12,13都可以,但最后工作的还是安装MDS服务的node3主机。

当挂载的11主机,拷贝数据


关闭13主机

此时客户端查看共享该挂载目录就会停止工作一直搜索文件,被卡住。

当开启13主机后就会显示数据,恢复正常。

5、当node3关机,客户端拷贝文件到共享目录,被卡住。

使用node2也部署MDS服务

此时拷贝文件就能拷贝了

对象存储:需要专门的客户端访问,键值对存储方式,对象存储需要rgw组件。
安装部署:ceph-deploy rgw create node3











