文章目录
本文gateway与微服务已开源到gitee
杉极简/gateway网关阶段学习
在Gateway(网关)与微服务架构中,令牌校验器(Token Validator)通常扮演着至关重要的角色,它的作用主要包括:
- 身份验证:令牌校验器确保只有拥有有效令牌的用户或服务才能访问微服务。这是保护后端服务的第一道防线。
- 权限控制:令牌中可能包含了用户的权限信息,校验器可以检查用户是否有足够的权限来访问特定的资源或执行特定的操作。
- 会话管理:在用户与服务之间维护会话状态,确保用户在一段时间内的请求可以关联到同一个会话。
- 单点登录(SSO):如果多个微服务共享同一个认证系统,令牌校验器可以帮助实现单点登录,用户只需要登录一次就可以访问所有服务。
- 负载减轻:通过在网关层面校验令牌,可以减轻微服务的负担,因为微服务不需要再进行令牌的校验,可以专注于业务逻辑的处理。
- 安全性增强:令牌校验器可以确保令牌的传输和使用符合安全标准,比如使用HTTPS传输,确保令牌不被窃取或篡改。
- 跨域处理:在网关层面处理跨域资源共享(CORS)问题,确保来自不同域的请求能够正常访问微服务。
- 集中管理:通过在网关处统一校验令牌,可以集中管理认证策略和令牌格式,便于维护和更新。
- 监控与日志记录:在令牌校验的过程中,可以记录相关的访问日志,便于后续的监控和分析。
令牌校验器通常是集成在API网关中的一个组件,它作为微服务架构中的守门人,确保所有进入微服务网络的请求都是合法和安全的。
集成redis
Nacos配置增加
Nacos中增加如下配置
redis:
host: localhost
port: 6379
password: 123456
timeout: 6000
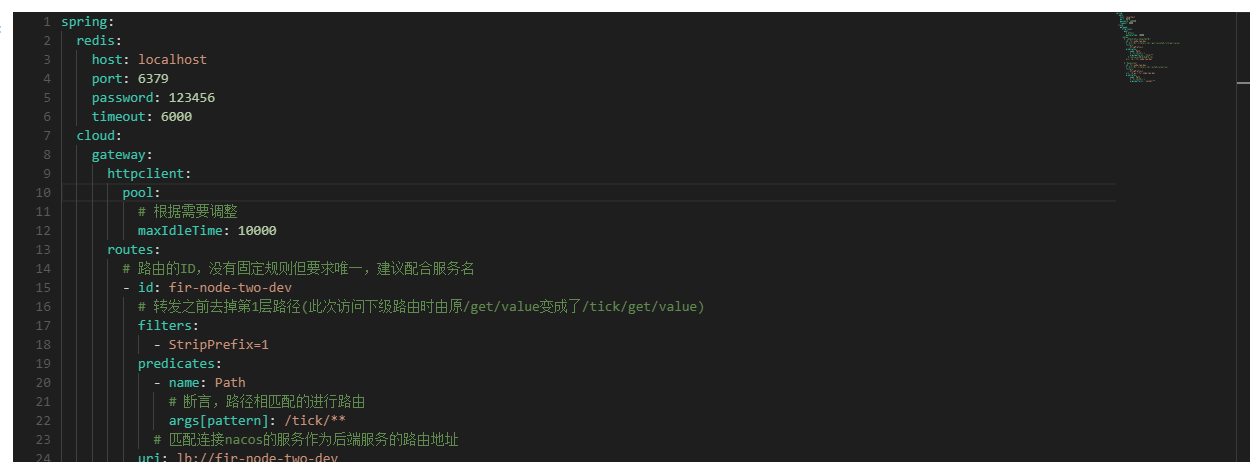
redis配置
配置pom
<!--redis-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
redis配置RedisConfig
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.JsonTypeInfo;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.jsontype.impl.LaissezFaireSubTypeValidator;
import org.springframework.cache.annotation.CachingConfigurerSupport;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.StringRedisSerializer;
/**
* redis配置
*
* @author fir
*/
@Configuration
@EnableCaching
public class RedisConfig extends CachingConfigurerSupport
{
@Bean
@SuppressWarnings(value = { "unchecked", "rawtypes" })
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory connectionFactory)
{
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(connectionFactory);
FastJson2JsonRedisSerializer serializer = new FastJson2JsonRedisSerializer(Object.class);
ObjectMapper mapper = new ObjectMapper();
mapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
mapper.activateDefaultTyping(LaissezFaireSubTypeValidator.instance, ObjectMapper.DefaultTyping.NON_FINAL, JsonTypeInfo.As.PROPERTY);
serializer.setObjectMapper(mapper);
// 使用StringRedisSerializer来序列化和反序列化redis的key值
template.setKeySerializer(new StringRedisSerializer());
template.setValueSerializer(serializer);
// Hash的key也采用StringRedisSerializer的序列化方式
template.setHashKeySerializer(new StringRedisSerializer());
template.setHashValueSerializer(serializer);
template.afterPropertiesSet();
return template;
}
}
redis序列化工具FastJson2JsonRedisSerializer
package com.fir.gateway.config.redis;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.serializer.SerializerFeature;
import com.fasterxml.jackson.databind.JavaType;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.type.TypeFactory;
import org.springframework.data.redis.serializer.RedisSerializer;
import org.springframework.data.redis.serializer.SerializationException;
import org.springframework.util.Assert;
import java.nio.charset.Charset;
import java.nio.charset.StandardCharsets;
/**
* Redis使用FastJson序列化
*
* @author fir
*/
public class FastJson2JsonRedisSerializer<T> implements RedisSerializer<T>
{
public static final Charset DEFAULT_CHARSET = StandardCharsets.UTF_8;
private final Class<T> clazz;
public FastJson2JsonRedisSerializer(Class<T> clazz)
{
super();
this.clazz = clazz;
}
@Override
public byte[] serialize(T t) throws SerializationException
{
if (t == null)
{
return new byte[0];
}
return JSON.toJSONString(t, SerializerFeature.WriteClassName).getBytes(DEFAULT_CHARSET);
}
@Override
public T deserialize(byte[] bytes) throws SerializationException
{
if (bytes == null || bytes.length <= 0)
{
return null;
}
String str = new String(bytes, DEFAULT_CHARSET);
return JSON.parseObject(str, clazz);
}
public void setObjectMapper(ObjectMapper objectMapper)
{
Assert.notNull(objectMapper, "'objectMapper' must not be null");
}
protected JavaType getJavaType(Class<?> clazz)
{
return TypeFactory.defaultInstance().constructType(clazz);
}
}
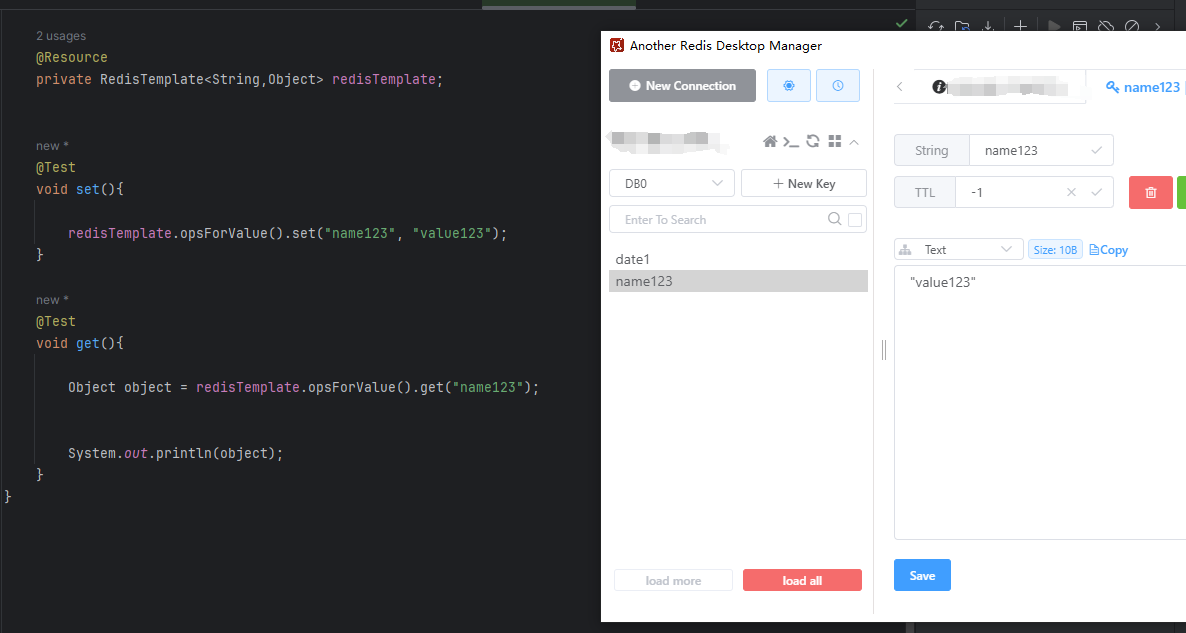
测试
通过一下代码进行测试,通过测试redis已经集成成功,详情如下:
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
import javax.annotation.Resource;
@SpringBootTest
public class RedisTest {
@Resource
private RedisTemplate<String,Object> redisTemplate;
@Test
void set(){
redisTemplate.opsForValue().set("name123", "value123");
}
@Test
void get(){
Object object = redisTemplate.opsForValue().get("name123");
System.out.println(object);
}
}
令牌校验拦截器
nacos配置
首先在nacos中新增tokenCheck与whiteUrls配置项**,**如下配置:
global:
# 全局异常捕捉-打印堆栈异常
printStackTrace: true
# 令牌头变量名称
token: Authorization
# 令牌校验
tokenCheck: true
# 不需要进行过滤的白名单
whiteUrls:
- /tick/auth/login
- /ws
拦截器代码
import com.fir.gateway.config.GlobalConfig;
import com.fir.gateway.config.exception.CustomException;
import com.fir.gateway.config.result.AjaxStatus;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.Ordered;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.http.server.reactive.ServerHttpRequest;
import org.springframework.stereotype.Component;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
import javax.annotation.Resource;
import java.util.List;
/**
* 令牌token校验拦截器
*
* @author fir
*/
@Slf4j
@Component
public class AuthorizationFilter implements GlobalFilter, Ordered {
/**
* 网关参数配置
*/
private GlobalConfig globalConfig;
@Resource
private RedisTemplate<String, Object> redisTemplate;
@Autowired
public void someComponent(GlobalConfig globalConfig) {
this.globalConfig = globalConfig;
}
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
log.info("登录信息校验:start");
// 判断token是否存在,且是否过期
boolean tokenKey = globalConfig.isTokenCheck();
if (tokenKey) {
// 白名单路由判断
ServerHttpRequest request = exchange.getRequest();
String path = request.getPath().toString();
List<String> whiteUrls = globalConfig.getWhiteUrls();
if (!whiteUrls.contains(path)) {
String tokenHeader = globalConfig.getTokenHeader();
String token = exchange.getRequest().getHeaders().getFirst(tokenHeader);
if (token == null || token.isEmpty()) {
log.error("token为空");
throw new CustomException(AjaxStatus.EXPIRATION_TOKEN);
}
Object obj = redisTemplate.opsForValue().get(token);
if (obj != null) {
log.info("登录信息校验:true");
} else {
log.error("token已失效");
throw new CustomException(AjaxStatus.EXPIRATION_TOKEN);
}
} else {
log.info("登录信息校验:true,白名单");
}
} else {
log.info("登录信息校验:true,验证已关闭");
}
return chain.filter(exchange);
}
@Override
public int getOrder() {
return -290;
}
}
微服务登录接口实现
微服务同样需要集成redis,集成方式与gateway一样
package com.fir.nacos.controller;
import com.alibaba.nacos.common.utils.StringUtils;
import com.fir.nacos.config.result.AjaxResult;
import com.fir.nacos.config.result.AjaxStatus;
import com.fir.nacos.entity.LoginResultDTO;
import com.fir.nacos.service.IAuthService;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiImplicitParam;
import io.swagger.annotations.ApiImplicitParams;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.cloud.context.config.annotation.RefreshScope;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
/**
* @author fir
*/
@Slf4j
@Api(tags = "系统接口")
@RestController
@RefreshScope
@RequestMapping("/auth")
public class AuthController {
@Resource
private IAuthService iAuthService;
/**
* 用户统一登陆
*
* @param username 用户
* @param password 密码
* @return 登录信息/登录失败信息
*/
@ApiOperation("登录接口")
@ApiImplicitParams({
@ApiImplicitParam(name = "username", value = "用户"),
@ApiImplicitParam(name = "password", value = "密码")
})
@RequestMapping("/login")
public AjaxResult login(String username, String password) {
LoginResultDTO loginResultDTO;
if(StringUtils.isNoneBlank(username) && StringUtils.isNoneBlank(password)){
loginResultDTO = iAuthService.login(username, password);
}else {
return AjaxResult.error(AjaxStatus.NULL_LOGIN_DATA);
}
return AjaxResult.success(loginResultDTO);
}
}
/**
* 用户统一登录
*
* @param username 账号
* @param password 密码
* @return 登录信息
*/
@Override
public LoginResultDTO login(String username, String password){
LoginResultDTO loginResultDTO = new LoginResultDTO();
if(StringUtils.isNoneBlank(username) && StringUtils.isNoneBlank(password)){
// 此处简单处理,根据实际的项目做更改
if(username.equals("fir") && password.equals("123456")){
// 生成 Token (可用多种方式例如jwt,此处不额外集成)
String token = "Bearer " + username + "token";
ConnectDTO connectDTO = ConnectDTO.builder()
.name(username)
.build();
Object o = JSONObject.toJSONString(connectDTO);
redisTemplate.opsForValue().set(token, o, globalConfig.getTimeNum(), globalConfig.timeUnit);
loginResultDTO = LoginResultDTO.builder()
.token(token)
.build();
}
}
return loginResultDTO;
}
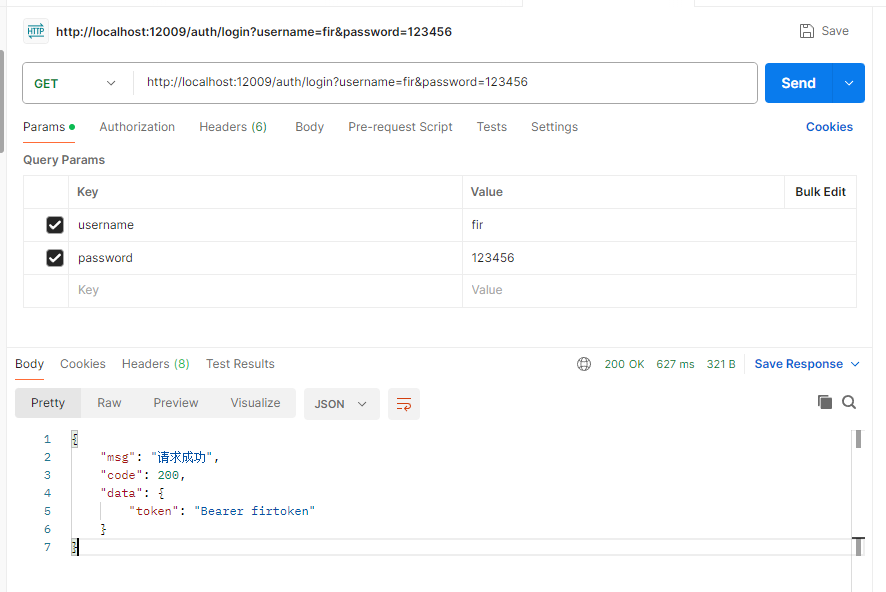
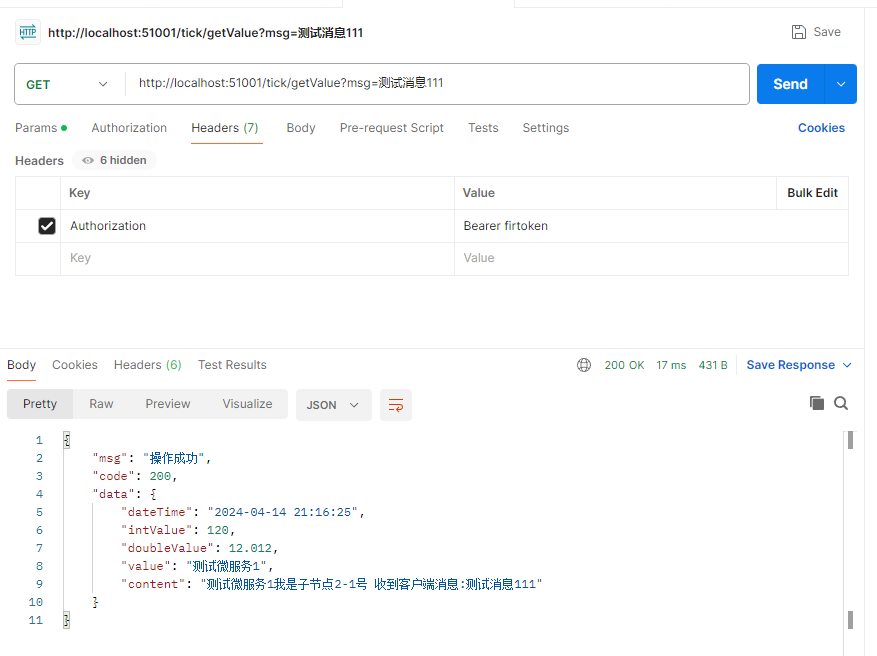
最终效果-登录接口与数据接口
此时如果不登录,则会被拦截
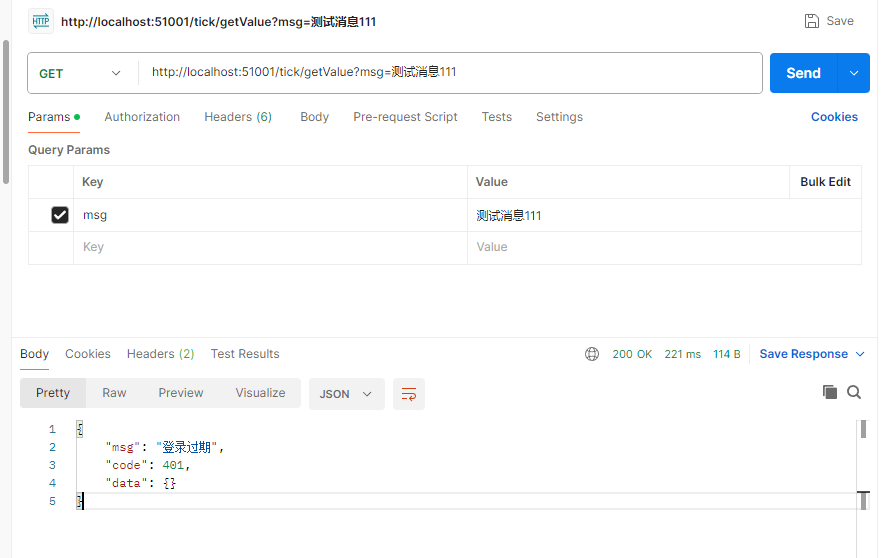
此时需要先获取到token之后,在数据接口的访问中,增加一个令牌请求头参数Authorization