目录
2.1 负载均衡集群(Load Balance Cluster)
2.2 高可用集群(High Availiablity Cluster)
2.3 高性能运算集群(High Performance Computing Cluster)
二、LVS(Linux Virtual Server )概述
一、集群
1、集群概述
1.1 什么是集群
在计算机科学中,集群(Cluster)是指一组相互连接的计算机(节点),这些计算机协同工作以完成共同的任务。集群可以通过网络相互通信和协作,从而形成一个整体系统
由多台主机构成,但对外只能表现为一个整体,只提供一个访问入口(域名或者ip地址),相当于一个大型计算机
集群通常被用于提高计算性能、可靠性和可扩展性
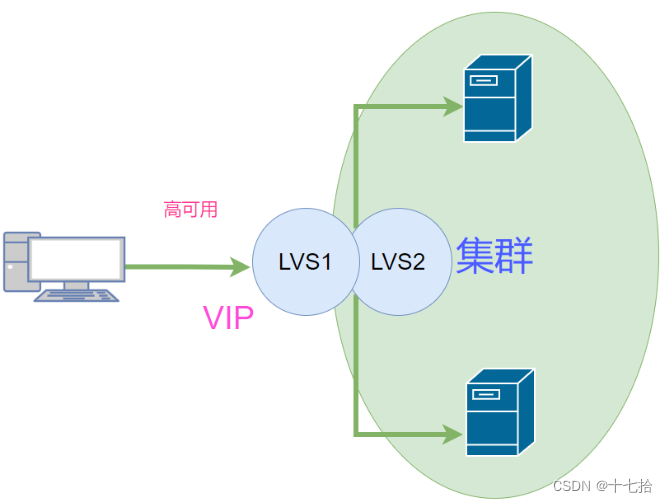
1.2 集群系统扩展方式
1.2.1 Scale UP(纵向扩展)
- 概念:Scale UP是通过增加单个服务器或节点的资源能力来提高系统性能和处理能力。这包括增加CPU核数、内存容量、存储容量等。
- 特点:Scale UP通常适用于单节点负载增加的情况,可以通过升级硬件或增加资源来提高系统的性能。这种扩展方式相对简单,但存在物理限制,无法无限制地扩展性能。
- 优点:简单易行,对于某些应用可以快速提高性能。
- 缺点:成本较高,存在硬件资源限制,不易实现无缝扩展。
1.2.2 Scale OUT(横向扩展)
- 概念:Scale OUT是通过增加系统中的节点或服务器数量来提高系统的性能和负载能力。这包括将负载分散到多个节点上进行并行处理。
- 特点:Scale OUT适用于需要处理大规模并发请求或需要高可用性的情况,可以通过增加节点数量来实现性能的线性扩展。
- 优点:相对于Scale UP,Scale OUT具有更好的横向扩展性,可以根据需求灵活地增加节点数量。
- 缺点:实现复杂一些,需要考虑数据一致性、通信开销等问题。
1.2.3 区别
- Scale UP是通过增加单个节点的资源来提高性能,而Scale OUT是通过增加节点数量来提高性能。
- Scale UP适用于单节点负载增加的情况,而Scale OUT适用于需要处理大规模并发请求或需要高可用性的情况。
- Scale UP相对简单,但存在硬件资源限制,而Scale OUT具有更好的横向扩展性,可以根据需求灵活地增加节点数量。
总之,在实际应用中,通常会根据系统需求和情况选择合适的扩展方式,有时也会将Scale UP和Scale OUT结合使用以实现更好的性能和可扩展性。
这里垂直扩展不再提及:随着计算机性能的增长,其价格会成倍增长
1.3 分布式系统
- 分布式概念:分布式系统是由多台计算机或节点协同工作,共同完成某个任务或提供某种服务的系统。在分布式系统中,各个节点通过网络通信相互协作,共享资源和信息,以实现更高的性能、可靠性和可扩展性
- 分布式存储:Ceph,GlusterFS,FastDFS,MogileFS
- 分布式计算:hadoop,Spark
- 分布式常见应用:
分布式应用:服务按照功能拆分,使用微服务(单一应用程序划分成一组小的服务,服务之间互相协调、互相配合,为用户提供最终价值服务)
分布式静态资源:静态资源放在不同的存储集群上
分布式数据和存储:使用key-value缓存系统
分布式计算:对特殊业务使用分布式计算,比如Hadoop集群
1.4 分布式与集群
集群:同一个业务系统,部署在多台服务器上。集群中,每一台服务器实现的功能没有差别,数据和代码都是一样的。
分布式:一个业务被拆成多个子业务,或者本身就是不同的业务,部署在多台服务器上。分布式中,每一台服务器实现的功能是有差别的,数据和代码也是不一样的,分布式每台服务器功能加起来,才是完整的业务。
1.5 集群设计原则
- 可扩展性:集群的横向扩展能力
- 可用性:无故障时间 (SLA service level agreement)
- 性能:访问响应时间
- 容量:单位时间内的最大并发吞吐量(C10K 并发问题)
1.6 集群设计实现
1.6.1 基础设施层面
- 提升硬件资源性能:从入口防火墙到后端 web server 均使用更高性能的硬件资源
- 多域名:DNS 轮询A记录解析
- 多入口:将A记录解析到多个公网IP入口
- 多机房:同城+异地容灾
- CDN(Content Delivery Network)—基于GSLB(Global Server Load Balance)实现全局负载均衡,如:DNS
1.6.2 业务层面
- 分层:安全层、负载层、静态层、动态层、(缓存层、存储层)持久化与非持久化
- 分割:基于功能分割大业务为小服务
- 分布式:对于特殊场景的业务,使用分布式计算
- 微服务
2、集群的类型
2.1 负载均衡集群(Load Balance Cluster)
- 提高应用系统的响应能力、尽可能处理更多的访问请求、减少延迟为目标,获得高并发、高负载(LB)的整体性能
- LB的负载分配依赖于主节点的分流算法,将来自客户机的访问请求分担给多个服务器节点,从而缓解整个系统的负载压力。例如,“DNS轮询”“反向代理”等
2.2 高可用集群(High Availiablity Cluster)
- 提高应用系统的可靠性、尽可能地减少中断时间为目标,确保服务的连续性,达到高可用(HA)的容错效果
- HA的工作方式包括双工和主从两种模式,双工即所有节点同时在线;主从则只有主节点在线,但当出现故障时从节点能自动切换为主节点。例如,”故障切换” “双机热备” 等
2.3 高性能运算集群(High Performance Computing Cluster)
- 提高应用系统的CPU运算速度、扩展硬件资源和分析能力为目标,获得相当于大型、超级计算机的高性能运算(HPC)能力
- 高性能依赖于“分布式运算”、“并行计算”,通过专用硬件和软件将多个服务器的CPU、内存等资源整合在一起,实现只有大型、超级计算机才具备的计算能力。例如“云计算”、“网格计算”
3、负载均衡集群架构
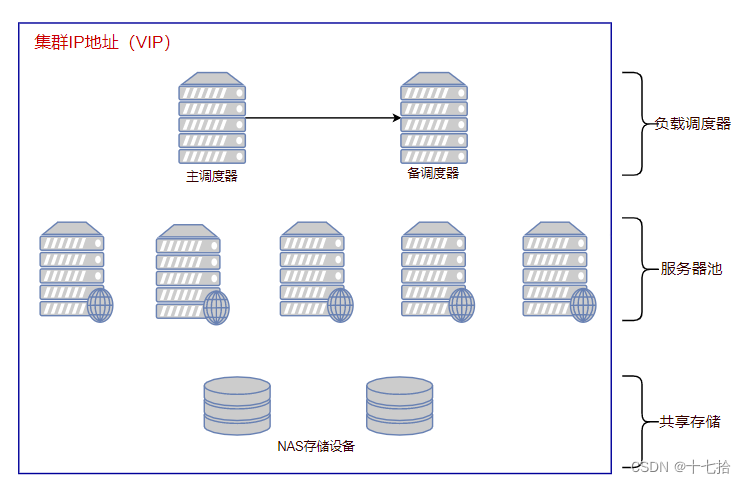
3.1 负载均衡集群的结构
- 第一层:负载调度器(Load Balancer或Director)
访问整个群集系统的唯一入口,对外使用所有服务器共有的VIP地址,也称为群集IP地址。通常会配置主、备两台调度器实现热备份,当主调度器失效以后能够平滑地替换至备用调度器,确保高可用性。
- 第二层:服务器池(Server Pool)
群集所提供的应用服务、由服务器池承担,其中每个节点具有独立的RIP地址(真实IP),只处理调度器分发过来的客户机的请求。当某个节点暂时失效时,负载调度器的容错机制会将其隔离,等待错误排除以后再重新纳入服务器池。
- 第三层:享存储(Share Storage)
为服务器池中所有节点提供稳定、一致的文件存取服务,确保整个群集的统一性;共享存储可以使用NAS设备,或者提供NFS共享服务的专用服务器。
3.2 LB Cluster负载均衡集群
3.2.1 按实现方式划分
硬件:
- F5 Big-IP(F5服务器负载均衡模块)
- Citrix Netscaler
- A10 A10
软件:
- lvs:Linux Virtual Server,阿里四层 SLB (Server Load Balance)使用
- nginx:支持七层调度,阿里七层SLB使用 Tengine
- haproxy:支持七层调度
- ats:Apache Traffic Server,yahoo捐助给apache
- perlbal:Perl 编写
- pound
3.2.2 基于工作的协议层次划分
传输层(通用):DNAT和DPORT
- LVS
- nginx:stream
- haproxy:mode tcp
应用层(专用):针对特定协议(常称为Proxy Server)
- http:nginx, httpd, haproxy(mode http)
- fastcgi:nginx, httpd
- mysql:mysql-proxy, mycat
负载均衡的会话保持:
- session sticky:同一用户调度固定服务器 Source IP:LVS sh算法(对某一特定服务而言) Cookie
- session replication:每台服务器拥有全部session(复制) session multicast cluster
- session server:专门的session服务器(server) Memcached,Redis
3.3 HA 高可用集群实现
keepalived:vrrp协议
Ais:应用接口规范
- heartbeat
- cman+rgmanager(RHCS)
- coresync_pacemaker
二、LVS(Linux Virtual Server )概述
1、LVS概念
LVS:Linux Virtual Server,负载调度器,内核集成,针对Linux内核开发的负载均衡解决方案;1998年5月,由我国章文嵩(花名正明)博士创建, 阿里的四层SLB(Server Load Balance)是基于LVS+keepalived实现;LVS实际上相当于基于IP地址的虚拟化应用,为基于IP地址和内容请求分发的负载均衡提出了一种高效的解决方法。
LVS官网:http://www.linuxvirtualserver.org/
阿里SLB和LVS:https://yq.aliyun.com/articles/1803 https://github.com/alibaba/LVS整个SLB系统由三部分构成:四层负载均衡、七层负载均衡 和 控制系统
- 四层负载均衡,采用开源软件LVS(Linux Virtual Server),并根据云计算需求对其进行定制化;该技术已经在阿里巴巴内部业务全面上线应用2年多
- 七层负载均衡,采用开源软件Tengine,该技术已经在阿里巴巴内部业务全面上线应用3年多
- 控制系统,用于配置和监控负载均衡系统
2、LVS功能及组织架构
负载均衡的应用场景为高访问量的业务,提高应用程序的可用性和可靠性。
2.1 应用于高访问量的业务
如果您的应用访问量很高,可以通过配置监听规则将流量分发到不同的云服务器 ECS(Elastic Compute Service 弹性计算服务)实例上。此外,可以使用会话保持功能将同一客户端的请求转发到同一台后端ECS
2.2 扩展应用程序
可以根据业务发展的需要,随时添加和移除ECS实例来扩展应用系统的服务能力,适用于各种Web服务器和App服务器。
2.3 消除单点故障
可以在负载均衡实例下添加多台ECS实例。当其中一部分ECS实例发生故障后,负载均衡会自动屏蔽故障的ECS实例,将请求分发给正常运行的ECS实例,保证应用系统仍能正常工作
2.4 同城容灾 (多可用区容灾)
为了提供更加稳定可靠的负载均衡服务,阿里云负载均衡已在各地域部署了多可用区以实现同地域容灾。当主可用区出现机房故障或不可用时,负载均衡仍然有能力在非常短的时间内(如:大约30s中断)切换到另外一个备可用区恢复服务能力;当主可用区恢复时,负载均衡同样会自动切换到主可用区提供服务。使用负载均衡时,您可以将负载均衡实例部署在支持多可用区的地域以实现同城容灾。此外,建议您结合自身的应用需要,综合考虑后端服务器的部署。如果您的每个可用区均至少添加了一台ECS实例,那么此种部署模式下的负载均衡服务的效率是最高的
3、LVS集群类型中的术语
-
VS:Virtual Server(代理服务器),DS:Director Server(负载调度器),Dispatcher(调度器),Load Balancer(lvs服务器)
-
RS:Real Server(lvs), upstream server(nginx), backend server(haproxy)(后端真实服务器)
-
CIP:Client IP(客户端IP)
-
VIP:Virtual serve IP(代理服务器VS外网的IP)
-
DIP:Director IP(代理服务器内网的IP)
-
RIP:Real server IP(后端真实服务器IP)
- 其他
4、LVS工作原理
VS根据请求报文的目标IP和目标协议及端口将其调度转发至某RS,根据调度算法来挑选RS。LVS是内核级功能,工作在INPUT链的位置,将发往INPUT的流量进行“处理”
[root@localhost ~]#grep -i -C 10 ipvs /boot/config-3.10.0-693.el7.x86_64
#在文件 /boot/config-3.10.0-693.el7.x86_64 中搜索包含关键字 ipvs 的行,并显示每个匹配行的上下文(上方和下方各10行)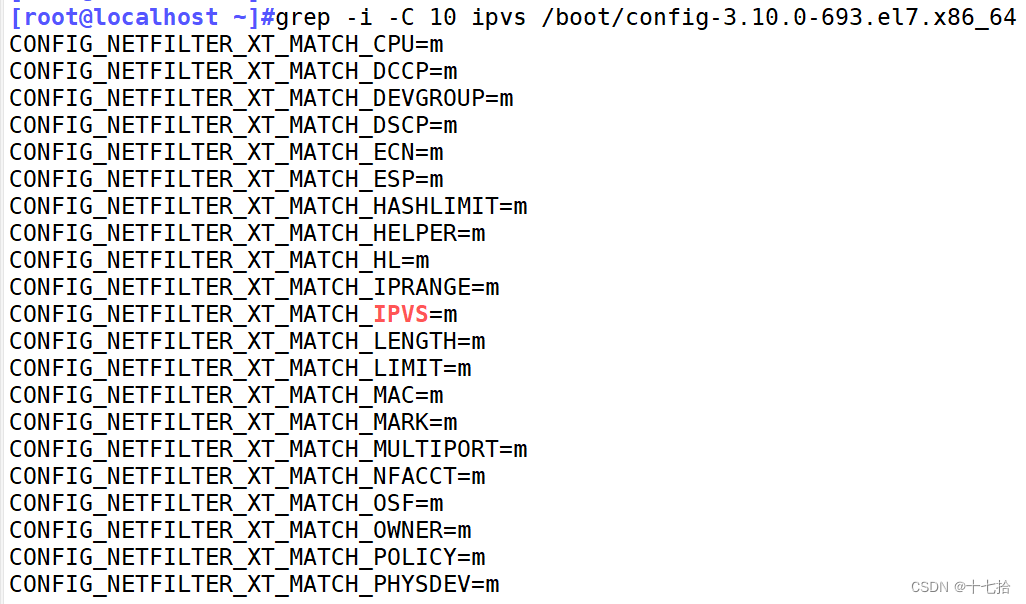
5、LVS工作模式和相关命令
5.1 LVS集群的工作模式
- lvs-nat:修改请求报文的目标IP,多目标IP的DNAT
- lvs-dr:操纵封装新的MAC地址(直接路由)
- lvs-tun:隧道模式
5.1.1 NAT模式
一种在负载均衡架构中使用的网络地址转换方式。它通过在负载调度器(Load Balancer)上进行地址转换,将来自客户端的请求重写为负载调度器的IP地址,并将请求转发给后端服务器
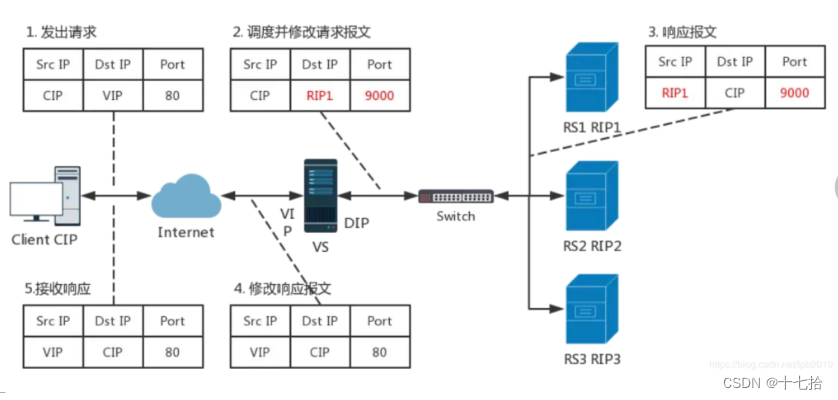
完整请求过程:
- 客户端发起请求报文,源IP为客户端IP地址(CIP),目的地址为VIP(代理服务器的外网地址)
- 当数据包到达我们的代理服务器,源IP不变,需要修改目的IP及端口号,此时源IP为客户端IP地址(CIP),目的地址为RIP(后端真实服务器IP)
- 真实服务器收到报文后构建响应报文,此时源IP修改为真实服务器自己的IP(VIP是内网地址),目的地址为CIP(外网客户端地址)
- 此时再发给代理服务器,源IP为代理服务器IP地址(VIP),目的地址为CIP(外网客户端地址)
- 回复至客户端:最终,负载调度器将后端服务器的回复返回给原始的客户端。对于客户端而言,它们与负载调度器之间的通信是透明的,客户端不需要知道后端服务器的存在
NAT模式的优点是实施简单,适用于需要隐藏后端服务器的IP地址或在与后端服务器通信时需要进行地址转换的情况。它可以将多个后端服务器组织为一个集群,并通过负载调度器实现负载均衡和高可用性。
5.1.2 IP隧道模式(IP Tunneling)
一种在负载均衡架构中使用的网络通信方式。它通过在负载调度器(Load Balancer)上创建隧道,将客户端请求原封不动地转发给后端服务器,并将后端服务器的响应原封不动地返回给客户端
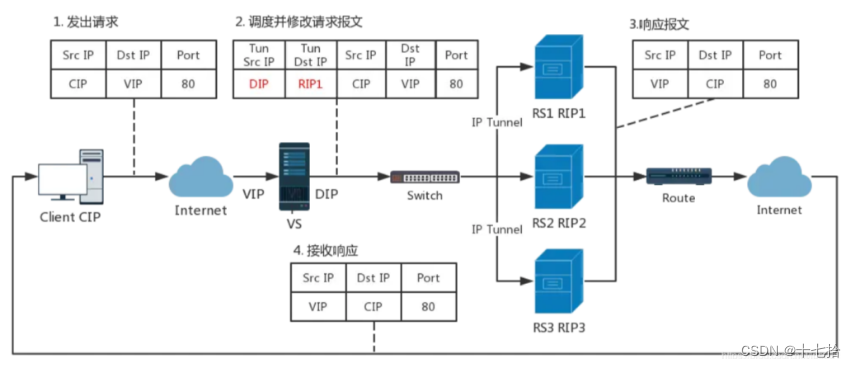
完整请求过程:
-
客户端请求到达:当客户端发送请求时,请求会到达负载调度器。负载调度器通常具有一个公共IP地址,这是对外部网络可见的地址
-
隧道创建:在IP隧道模式下,负载调度器会创建一个隧道,将客户端请求原封不动地封装在通道中,并通过隧道转发给后端服务器
-
转发请求:经过隧道封装后,负载调度器将请求转发给后端服务器。后端服务器接收到的请求与直接来自客户端的请求完全相同,不经过任何地址转换或重写操作
-
后端服务器处理:后端服务器对收到的请求进行处理,并产生相应的响应
-
响应返回:后端服务器的响应会原封不动地通过隧道返回给负载调度器
-
回复至客户端:最终,负载调度器将后端服务器的响应原封不动地返回给原始的客户端。对于客户端而言,它们与负载调度器之间的通信是透明的,客户端不需要知道后端服务器的存在
IP隧道模式的优点是实现简单,可以保留客户端和后端服务器之间的原始通信方式,不需进行地址转换或重写。然而,由于负载调度器只是透传客户端请求和后端服务器响应,可能无法实现负载均衡和高可用性
5.1.3 直接路由模式(Direct Routing)
一种在负载均衡架构中使用的网络通信方式。它通过在负载调度器(Load Balancer)和后端服务器之间建立直接的通信路径,实现请求的负载均衡和响应的传递。
通过路由技术实现虚拟服务器,节点服务器需在回环网卡上配置虚拟IP地址。注意mac地址广播,只开启负载调度服务器的arp广播。
-
负载调度器配置:在直接路由模式下,负载调度器通常有一个公共IP地址,也称为虚拟服务器IP地址(Virtual IP Address)。负载调度器通过这个公共IP地址与客户端进行通信
-
后端服务器配置:在直接路由模式下,后端服务器的IP地址必须与负载调度器在同一个子网下,并且负载调度器和后端服务器之间必须有直接的网络连通性
-
请求转发:当客户端发送请求时,请求会到达负载调度器。负载调度器将根据负载均衡算法选择一个后端服务器,并将请求原封不动地转发给该后端服务器
-
后端服务器处理:后端服务器接收到请求后,对其进行处理,并生成相应的响应
-
响应传递:后端服务器的响应不经过负载调度器,直接返回给客户端。负载调度器在这个过程中充当了一个透明的转发中介,不参与实际的数据传递
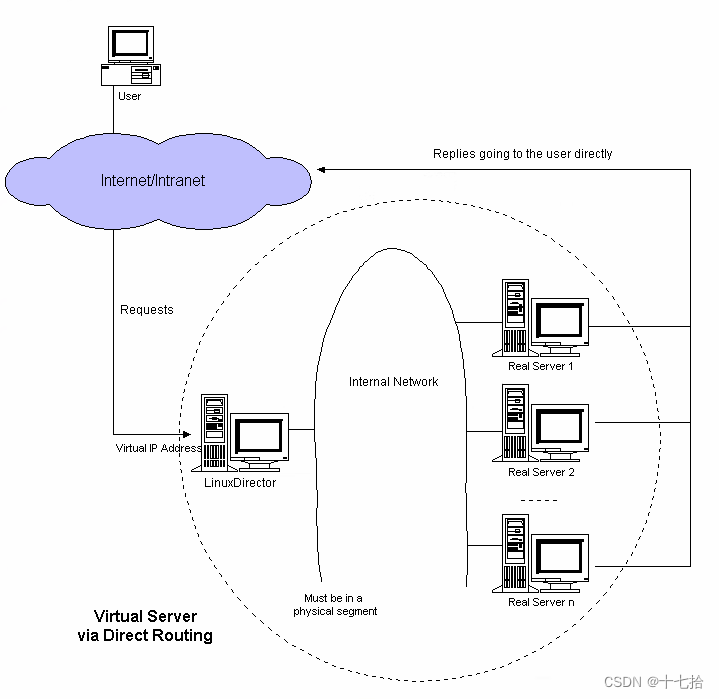
直接路由模式的优点是高性能和低延迟,因为负载调度器和后端服务器之间的通信是直接的,不需要额外的网络地址转换或重写操作。此外,由于响应不需要通过负载调度器,后端服务器的处理能力可以完全发挥出来
5.1.4 LVS工作模式总结和比较
6、LVS调度算法
ipvs scheduler:根据其调度时是否考虑各RS当前的负载状态
类型分为:静态调度算法和动态调度算法
6.1 静态调度算法
- RR:roundrobin,轮询,较常用
- WRR:Weighted RR,加权轮询,较常用
- SH:Source Hashing,实现session sticky,源IP地址hash;将来自于同一个IP地址的请求始终发往第一次挑中的RS,从而实现会话绑定
- DH:Destination Hashing;目标地址哈希,第一次轮询调度至RS,后续将发往同一个目标地址的请求始终转发至第一次挑中的RS,典型使用场景是正向代理缓存场景中的负载均衡,如: Web缓存
6.2 动态调度算法
主要根据每RS当前的负载状态及调度算法进行调度,Overhead=value较小的RS将被调度
- LC:least connections 适用于长连接应用。不考虑权重
LC算法:Overhead=activeconns*256+inactiveconns- WLC:Weighted LC,默认调度方法,较常用。第一轮不合理,都是一样的优先级
WLC算法:Overhead=(activeconns*256+inactiveconns)/weight- SED:Shortest Expection Delay,初始连接高权重优先,只检查活动连接,而不考虑非活动连接。权重小的,比较空闲
SED算法:Overhead=(activeconns+1)*256/weight- NQ:Never Queue,第一轮均匀分配,后续SED
- LBLC:Locality-Based LC,动态的DH算法,使用场景:根据负载状态实现正向代理,实现Web Cache等
- LBLCR:LBLC with Replication,带复制功能的LBLC,解决LBLC负载不均衡问题,从负载重的复制到负载轻的RS,,实现Web Cache等
6.3 其他调度算法
内核版本 4.15 版本后新增调度算法 FO 和 OVF
- FO(Weighted Fail Over)调度算法,在此FO算法中,遍历虚拟服务所关联的真实服务器链表,找到还未过载(未设置IP_VS_DEST_F_OVERLOAD标志)的且权重最高的真实服务器,进行调度,属于静态算法
- OVF(Overflow-Connection)调度算法,基于真实服务器的活动连接数量和权重值实现。将新连接调度到权重最高的真实服务器,直到其活动连接数量超过权重值,之后调度到下一个权重值最高的真实服务器,在此OVF算法中,遍历虚拟服务相关联的真实服务器链表,找到权重值最高的可用真实服务器,属于动态算法
一个可用的真实服务器需要通式满足以下条件
- 未过载(未设置IP_VS_DEST_F_OVERLOAD标志)
- 真实服务器当前的活动连接数量小于其权重值
- 其权重值不为零


