深度学习语义分割篇——DeepLabV2原理详解篇
写在前面
在上一节,我已经为大家介绍了DeepLabV1的原理,还不清楚的赶快点击☞☞☞了解详情。🍍🍍🍍那么这篇就和大家唠唠DeepLabV1的兄弟篇——DeepLabV2。其实呢,你要是清楚DeepLabV1的话,那么DeepLabV2对你来说就是小菜一碟了,改进点是比较少也比较好理解的。话不多说,让我们一起走进DeepLabV2的世界叭~~~🚖🚖🚖
语义分割存在的挑战
是不是发现和DeepLabV1博客的结构很像呢,在V2论文的INTRODUCTION中也首先提出了DCNN应用于语义分割的三个挑战,如下图所示:

翻译一下:
- 特征分辨率降低
- 目标在多尺度上的存在
- 由于DCNN的不变性降低了定位精度
熟悉,熟悉,实在是太熟悉了,大家一定会有这样的感受。确实如此,这和DeepLabV1的挑战几乎一致,就多了一个第2点,而且其实在DeepLabV1中也使用到了多尺度的方法,不记得的大家可以点击☞☞☞去瞅一眼。🍖🍖🍖
DeepLabV2网络优势

- 速度更快:借助atrous算法(空洞卷积算法),密集的DCNN在NVidia Titan X GPU上以8帧/秒的速度运行。
- 准确性更高:我们在几个具有挑战性的数据集上获得了最新的结果,包括PASCAL VOC 2012语义分割基准、PASCAL- context、PASCALPerson-Part和cityscape。
- 模型结构简单:我们的系统由两个非常完善的模块级联组成,即DCNN和CRF。
我想大家又发现了,这个和DeepLab的表述几乎是一样的。🥗🥗🥗
大家通过上面两个小节我想应该会发现,DeepLabV1和DeepLabV2似乎存在很多相似之处,在后文DeepLabV2的网络结构中我会挑一些重点为大家讲解,其实也没几个,先给大家透个底叭,V2较V1主要做了如下改变:
- 添加了ASPP多尺度结构
- 修改了backbone
- 设计了poly学习率更新策略
后面我也将主要从这三个方面为大家展开叙述~~~🍻🍻🍻
DeepLabV2网络结构
前文提到DeepLabV2较DeepLabV1主要添加了ASPP结构、修改了backbone及设计了poly学习率更新策略,其实呢,论文中还做了一些其它的小改进,这里就不一一阐述了。比如对CRF的二元势函数进行了更新,但是呢,由于我在V1中就没有介绍CRF,所以这里也就不介绍啦,感兴趣的去看看论文叭。🍚🍚🍚
ASPP结构
先来说说这个ASPP的全称叭,即atrous spatial pyramid pooling,翻译过来的话叫空洞空间金字塔池化【蹩脚的翻译,勿喷🤐🤐🤐】。下图为ASPP模块的结构示意图:
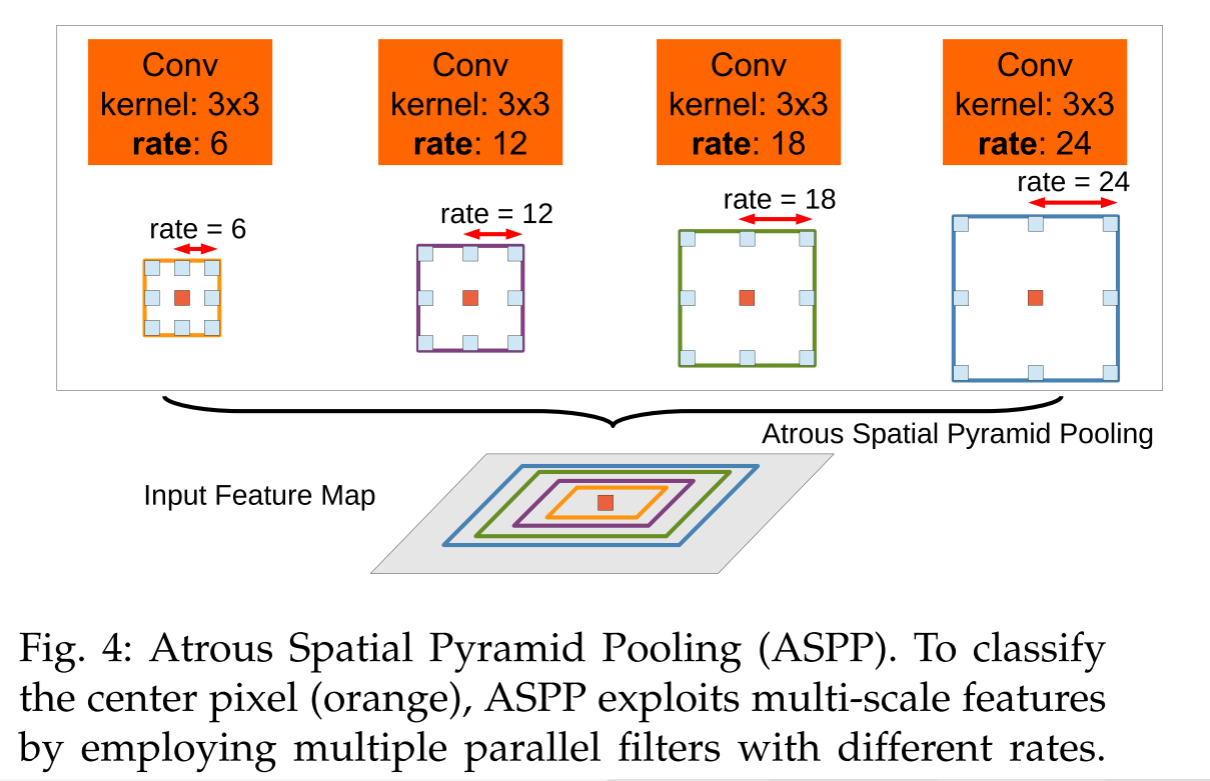
从上图可以看到ASPP模块是在输出的特征图上并联了四个分支,每个分支上采用了卷积核大小为3×3、膨胀系数依次为6、12、18、24的空洞卷积,以此实现每个分支具有不同的感受野大小,也就具有了解决目标多尺度问题的能力。🏆🏆🏆
大家还记得在DeepLabV1中提到的LargeFOV结构吗,不记得的话点击☞☞☞去了解下叭。🍄🍄🍄那么在DeepLabV2中就没有使用LargeFOV结构了喔,而是用的ASPP结构。其实通过上图你可能就会发现ASPP就像是在LargeFOV的基础上多并联了几个分支,即增加了多尺度信息,所以有了ASPP就用不着LargeFOV模块啦。🥗🥗🥗当然了,V2的论文中也给出了LargeFOV和ASPP的详细结构,如下图所示:
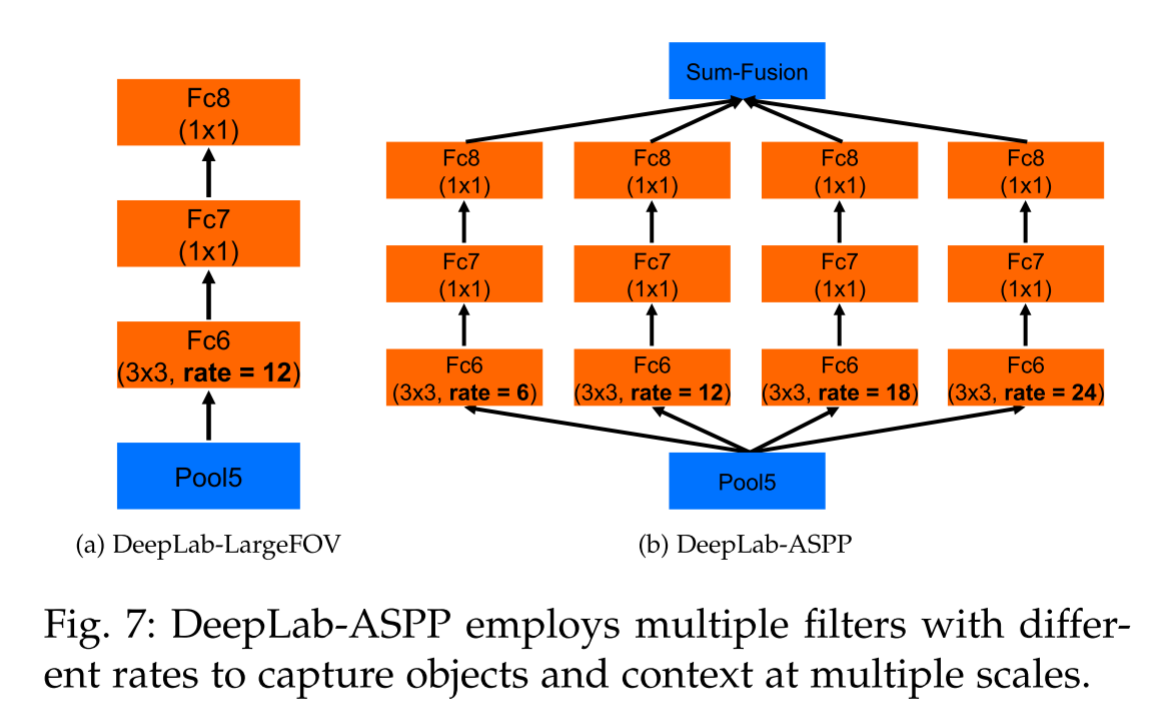
这个图已经非常清晰的展示了ASPP的结构了,但有一点需要大家注意一下,即上图这两个结构都是基于backbone为VGG16绘制的【DeepLabV2中将backbone换成了resnet】,但是不管采用哪种backbone,ASPP结构的核心思想都是一样的,这里稍微来谈谈以resnet为backbone的ASPP结构是什么样的,如下图所示:
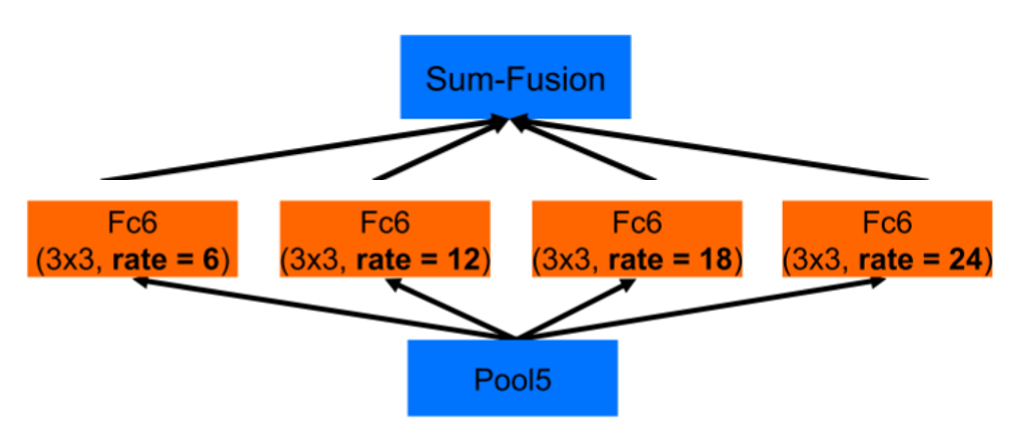
我想大家一对比很容易就看出来了,此时每个分支都少了后面两层结构,这里大家注意一下就好。🍗🍗🍗
最后在给大家展示一下采用了ASPP的效果,如下图所示:

其中,ASPP-S表示并联的四个分支采用的膨胀系数r依次为2、4、8、12;ASPP-L表示并联的四个分支采用的膨胀系数r依次为6、12、18、24;🌼🌼🌼
修改backbone
呀呀呀,在上一小节已经透露了,DeepLabV2使用的backbone为resnet,这可以说是最常见的一种网络了,是由咱们中国人何恺明大佬提出的,还不清楚的快点击☞☞☞学起来叭。这里为方便读者阅读,贴出resnet的相关参数,如下图:【以resnet101为例】
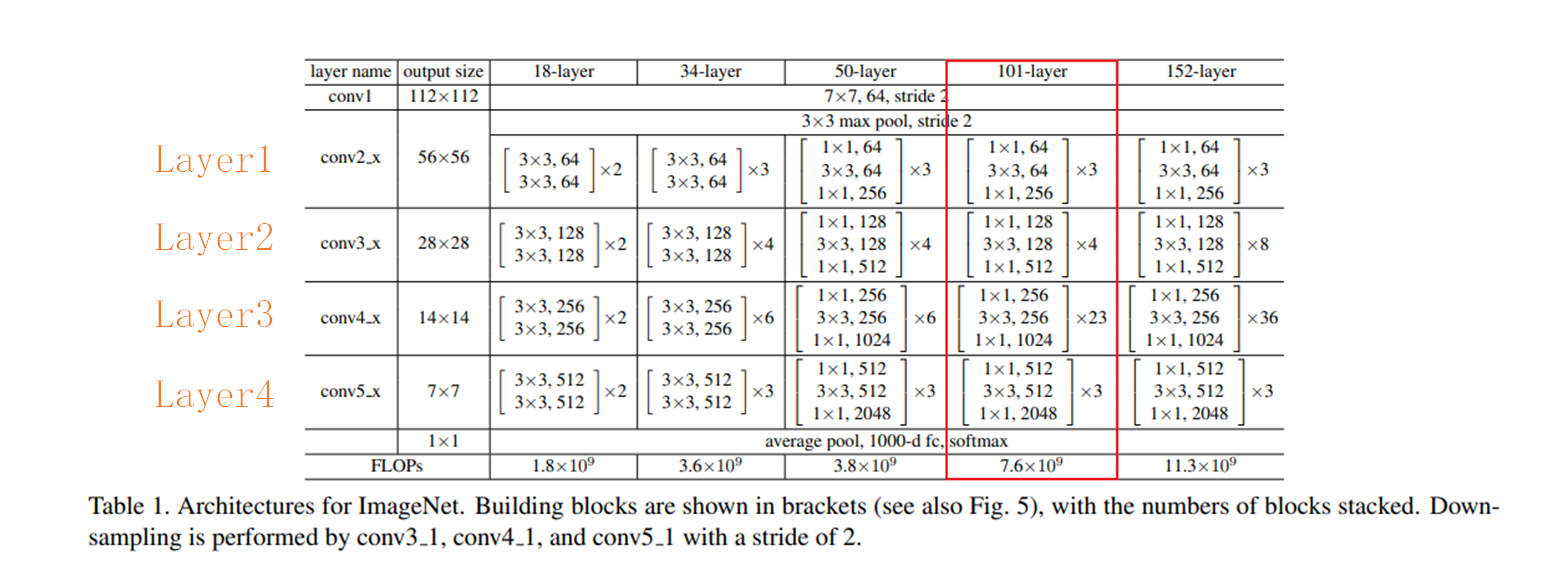
DeepLabV2在Layer2层之前的结构和resnet101是完全一致的,经过Layer2层后,图像已经下采样了8倍,和V1一样,现在不希望再过度的下采样导致丢失大量信息了,因此在Layer3和Layer4层不再进行下采样,同样采用空洞卷积来弥补不进行下采样减少的感受野,DeepLab的网络结构如下图所示:
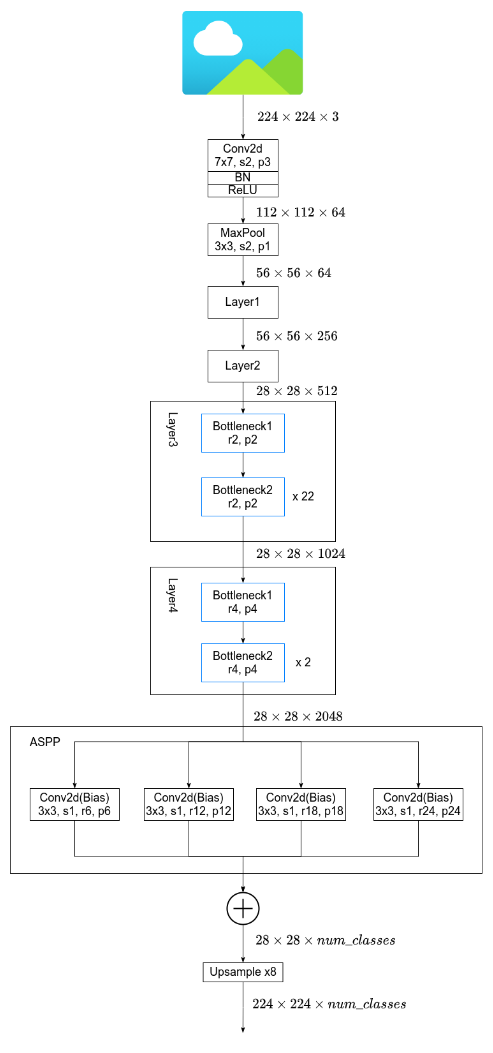
图片来自B站霹雳吧啦Wz
其中,Layer3、Layer4的详细结构如下:

图片来自B站霹雳吧啦Wz
可以看到,在经过Layer4层后,特征图的下采样倍数仍然是8,大小为
28
×
28
×
2048
28×28×2048
28×28×2048。然后就会接入上文提及的ASPP结构,即并联一个膨胀系数分别为6、12、18、24的空洞卷积,注意一下这里的空洞卷积的卷积核个数都为number_class。🍵🍵🍵
设计poly学习率更新策略
在DeepLabV2中,作者设计了poly学习率更新策略,其公式如下:
l r = l r ∗ ( 1 − i t e r m a x _ i t e r ) p o w e r lr=lr*(1-\frac{iter}{max\_iter})^{power} lr=lr∗(1−max_iteriter)power
其中power是一个超参,默认为0.9。 l r lr lr为初始学习率, i t e r iter iter为当前迭代的step数,$m a x _ i t e r 为训练过程中总的迭代步数。 p o l y 策略的 为训练过程中总的迭代步数。poly策略的 为训练过程中总的迭代步数。poly策略的lr$变化曲线大致如下图所示:

这样的策略会给实验效果带来多大的影响呢,如下表所示:

震惊,有没有,直接提了3个多点,什么时候我也能成为炼丹大师。🍋🍋🍋
DeepLabV2实验对比
在V2中,作者在PASCAL VOC 2012语义分割基准数据集、PASCAL- context、PASCALPerson-Part和cityscape四个数据集上做了实验,下面分别展示一下。
小结
好啦,DeepLabV2就为大家介绍到这里了,是不是非常简单腻,下一节将为大家带来DeepLabV3的原理和代码了喔,让我们一起加油叭!!!🌱🌱🌱
参考链接
如若文章对你有所帮助,那就🛴🛴🛴











