
hive 慢sql 查询
-
查找 hive 执行日志存储路径(一般是 hive-audit.log )
比如:/var/log/Bigdata/audit/hive/hiveserver/hive-audit.log
-
解析日志 获取 执行时间 执行 OperationId 执行人 UserName=root 执行sql 数据分隔符为 \001 并写入 hivesql.txt
tail -1000f /var/log/Bigdata/audit/hive/hiveserver/hive-audit.log |grep OperationId= |awk -F"|" '{print $1,$4}' |awk -F "\t" -v OFS="\001" '{print $1,$2,$6}' >> /home/yx_test/hiveSql/hivesql.txt解析结果如下 2024-04-03 08:37:57,851 OperationId=e0c496d6-6979-4e44-a9a3-1ec3ac2a6767UserName=rootstmt={sql语句} -
上传相关解析日志到hive
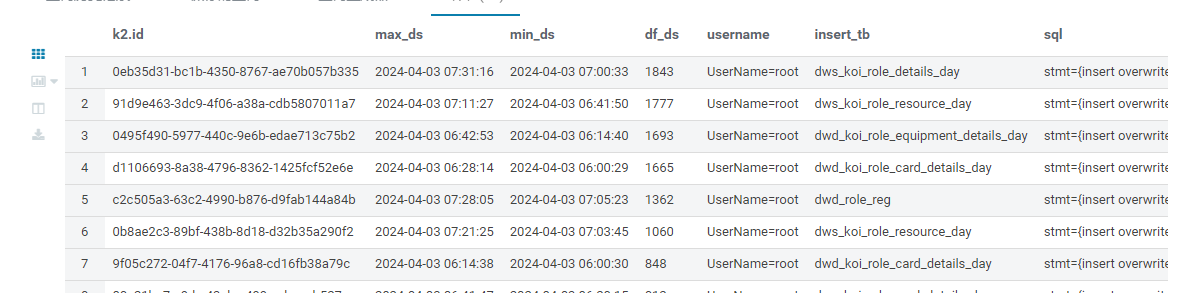
hadoop fs -put /home/yx_test/hiveSql/hivesql*.txt hive/warehouse/yx_test/ods_format_datas1/tb=hivesql/ 1.刷新hive元数据 MSCK REPAIR TABLE yx_test.ods_format_datas1 2.然后再次解析日志 获取: 执行id 执行结束时间 执行开始时间 执行时长 执行人 写入表 执行sql语句 SELECT k2.id,max_ds,min_ds,df_ds,username,insert_tb,sql from ( SELECT id,max_ds,min_ds,df_ds from ( SELECT id -- 执行id ,max(substr(ds,1,19)) max_ds -- 执行结束时间 ,min(substr(ds,1,19)) min_ds -- 执行开始时间 , unix_timestamp(max(substr(ds,1,19)))-unix_timestamp(min(substr(ds,1,19))) df_ds -- 执行时长 from ( SELECT split(c1,' OperationId=')[0] ds ,split(c1,' OperationId=')[1] id from yx_test. ods_format_datas1 where tb='hivesql' -- and c2 like '%insert%' )k group by id )k1 where df_ds>=600 -- 获取执行时长超过 10分钟的sql信息 order by df_ds )k2 inner join -- 通过执行 id 匹配出 执行的详细sql 以及写入 表 (SELECT id,username ,trim(substr(substr(lower(c3),beg,ends-beg),1, if(instr(substr(lower(c3),beg,ends-beg),' partition')!=0,instr(substr(lower(c3),beg,ends-beg),' partition'),1000))) insert_tb -- 写入表 ,lower(c3) sql from ( SELECT split(c1,' OperationId=')[1] id -- 执行id ,c2 username -- 执行角色 ,c3 -- 执行的sql语句 --提取写入表前后位置 ,if(instr(lower(c3),'table')=0,instr(lower(c3),'into')+length('into'),instr(lower(c3),'table')+length('table')) beg ,instr(lower(c3),' select') ends from yx_test.ods_format_datas1 where tb='hivesql' and c3 like '%insert%' -- 只获取 包含 insert 的日志 )k )k3 on k2.id=k3.id ORDER BY df_ds desc ; 3. 通过写入表 查看 涉及到的具体库 SELECT * from ( SELECT k.DB_ID,k.`NAME`,k1.TBL_NAME from ( SELECT DB_ID,`NAME` FROM `dbs` )k left join (SELECT DB_ID,TBL_NAME from tbls )k1 on k.DB_ID=k1.DB_ID )k2 WHERE TBL_NAME in ('dws_koi_role_details_day')效果如图:
部署脚本
-- 日志采集
ssh omm@192.168.0.183 'bash -s' << 'EOF'
source /opt/Bigdata/client/bigdata_env
touch /home/yangxiong/hiveSql/hivesql2.txt
hadoop fs -put /home/yangxiong/hiveSql/hivesql*.txt obs://youkia-koi/hive/warehouse/yx_test/ods_format_datas1/tb=hivesql/
echo > /home/yangxiong/hiveSql/hivesql*.txt
ps -ef |grep 'tail -1000f /var/log/Bigdata/audit/hive/hiveserver/hive-audit.log' |awk '{print $2}'|xargs kill -9
nohup tail -1000f /var/log/Bigdata/audit/hive/hiveserver/hive-audit.log |grep OperationId= |awk -F"|" '{print $1,$4}' |awk -F "\t" -v OFS="\001" '{print $1,$2,$6}' >> /home/yangxiong/hiveSql/hivesql2.txt 2>&1 &
exit
# 这里可以添加更多的命令
EOF
-- 日志解析
insert overwrite table sgz_game_common.hive_timeout_sql
SELECT k2.id sql_id,min_ds begint_ds,max_ds end_ds,df_ds sustain_ds ,username,insert_tb,sql,'${hiveconf:ds}' ds from (
SELECT id,max_ds,min_ds,df_ds from (
SELECT
id
,max(substr(ds,1,19)) max_ds
,min(substr(ds,1,19)) min_ds
, unix_timestamp(max(substr(ds,1,19)))-unix_timestamp(min(substr(ds,1,19))) df_ds
from (
SELECT split(c1,' OperationId=')[0] ds ,split(c1,' OperationId=')[1] id from yx_test.ods_format_datas1
where tb='hivesql'
-- and c2 like '%insert%'
)k group by id
)k1
where df_ds>=1800
order by df_ds
)k2
inner join
(
SELECT
id,username
,trim(substr(substr(lower(c3),beg,ends-beg),1, if(instr(substr(lower(c3),beg,ends-beg),' partition')!=0,instr(substr(lower(c3),beg,ends-beg),' partition'),1000))) insert_tb
,lower(c3) sql from (
SELECT split(c1,' OperationId=')[1] id,c2 username,c3
,if(instr(lower(c3),'table')=0,instr(lower(c3),'into')+length('into'),instr(lower(c3),'table')+length('table')) beg
,instr(lower(c3),' select') ends
from yx_test.ods_format_datas1
where tb='hivesql' and c3 like '%insert%'
)k
)k3 on k2.id=k3.id
-- ORDER BY df_ds desc
UNION all
SELECT sql_id,begint_ds,end_ds,sustain_ds,username,insert_tb,sql,ds from (
SELECT sql_id,begint_ds,end_ds,sustain_ds,username,insert_tb,sql,ds
,row_number() OVER (PARTITION by 1=1 ORDER BY ds desc) rk
from sgz_game_common.hive_timeout_sql
WHERE ds!='{hiveconf:ds}'
)k where rk<=30
;









