
文章目录
一、引言
你可能听说过高水位(High Watermark),但不一定耳闻过 Leader Epoch。
前者是 Kafka 中非常重要的概念,而后者是社区在 0.11 版本中新推出的,主要是为了弥补高水位机制的一些缺陷。
鉴于高水位机制在 Kafka 中举足轻重,而且深受各路面试官的喜爱,今天我们就来重点说说高水位。当然,我们也会花一部分时间来讨论 Leader Epoch 以及它的角色定位。
本文的篇幅比较长,副本之间的同步比较细节,建议留一定的时间用来阅读
二、何为高水位
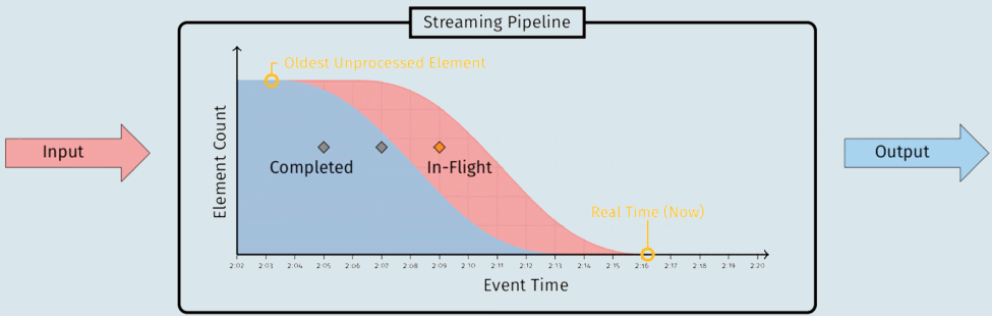
日常生活中,我们一般把什么叫做水位呢?
- 经典教科书
- 在时刻
T,任意创建时间(Event Time)为T',且T'<=T的所有事件都已经到达,那么T就被定义为水位
- 在时刻
- 《Streaming System》
- 水位是一个单调增加且表征最早未完成工作的时间戳
- 如上图所示,标注为
Completed的蓝色区域代表已经完成的工作,而标注为In-Flight的红色区域代表未完成(正在进行)的工作,两边的交界线就是水位线。 - 在 kafka 中,水位不是时间戳,而是与位置信息绑定的,即用 **消息位移(offset)**来表征水位
- 当然,kafka 中也有低水位(Low Watermark),与 kafka的删除消息有关,不在我们本篇文章的讨论范围之内
三、高水位的作用
在 kafka 中,高水位的作用主要是 2 个
- 定义消息可见性,既用来告诉我们的消费者哪些消息是可以进行消费的
- 帮助 kafka 完成副本机制的同步
Kafka 分区下有可能有很多个副本用于实现冗余,从而进一步实现高可用。副本根据角色的不同可分为3种
- leader 副本:相应 clients 端读写请求的副本
- Follower 副本:被动的备注 leader 副本的内容,不能相应 clients 端读写请求
- ISR 副本: 包含了 leader 副本和所有与 leader 副本保持同步的 Followerer 副本
每个 kafka 副本对象都有两个重要的属性:LEO 和 HW。注意是所有的副本(leader + Follower)
- LEO:当前日志末端的位移(log end offset),记录了该副本底层日志(log)中下一条消息的位移值。
- HW:高水位值(High Watermark),对于同一个副本对象,其 HW 的值不会超越 LEO。
我们假设下图是某个分区 leader 副本的高水位图:
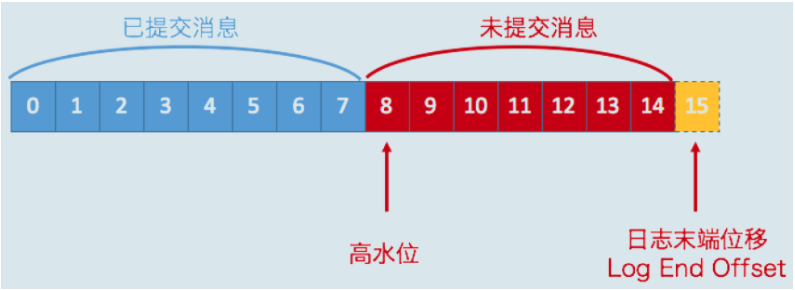
在高水位线之下的为 已提交消息,在水位线之上的为 未提交消息,对于 已提交消息,我们的消费者可以进行消费,也就是图中 0-7 下标的消息。需要关注的是,位移值等于高水位的消息也属于未提交消息。也就是说,高水位上的消息是不能被消费者消费的。
图中的日志末端位置,既我们所说的 LEO,他表示副本写入下一条消息的位移值。我们可以发现,位移值 15 的地方为虚框,这表示我们当前副本只有15条消息,位移值是从 0 到 14,下一条新消息的位移是 15。
观察得知,对于同一个副本,我们的高水位值不会超越其 LEO 值。
四、高水位更新机制
通过上面的讲述,我们知道每个副本对象都保存了一组 HW 和 LEO。
但实际上,在 leader 副本所在的 Broker0 上,还保存了其他 Follower 副本的 LEO 值,这些 Follower 副本又被称为远程副本(Remote Replica)

kafka 副本机制在运行过程中:
-
更新
-
Broker1 上 Follower 副本的高水位和 LEO 值,
-
Broker0 上 leader 副本的高水位和 LEO 以及所有 Follower 副本的 LEO
-
-
不会更新
- 所有 Follower 副本的 HW,既图中标记为灰色的部分。
这里可能你会有疑问了,为什么我们要在 Broker0 上保存这些 Follower 副本呢?
- 帮助 leader 副本确定其高水位,也就是分区高水位
1、更新时机
| 更新对象 | 更新时机 |
|---|---|
| Borker0 上Leader副本的LEO | Leader副本接收到生产者发送的消息,写入到本地磁盘后,会更新其LEO值 |
| Broker 1上Follower副本的LEO | Follower副本从Leader副本拉取消息,写入本地磁盘后,会更新其LEO值 |
| Broker0上远程副本的LEO | Follower副本从Leader副本拉取消息,会告诉Leader副本从哪个位移开始拉取,Leader副本会使用这个位移来更新远程副本的LEO |
| Broker0上Leader副本的高水位 | 两个更新时机:一个是Leader副本更新其LEO之后,一个是更新完远程副本LEO后,具体算法:取Leader副本和所有与Leader同步的远程副本LEO的最小值 |
| Broker 1上Follower副本的高水位 | Follower副本更新完LEO后,会比较LEO与leader副本发来的高水位值,并用两者的较少值去更新自己的高水位 |
- Follower 副本与 Leader 副本保持同步,需要满足两个条件
- Follower 副本在 ISR 中
- Follower 副本 LEO 值落后 Leader 副本 LEO 值的时间不超过参数
replica.lag.time.max.ms,默认是 10 秒
这两个条件好像是一回事,因为某个副本能否进入 ISR 就是靠第 2 个条件判断的。
但有些时候,会发生这样的情况:即 Follower 副本已经“追上”了 Leader 的进度,却不在 ISR 中,比如某个刚刚重启回来的副本。如果 Kafka 只判断第 1 个条件的话,就可能出现某些副本具备了“进入 ISR”的资格,但却尚未进入到 ISR 中的情况。此时,分区高水位值就可能超过 ISR 中副本 LEO,而高水位 > LEO 的情形是不被允许的。
2、leader 副本和 Follower 副本
Leader 副本
- 处理生产者的逻辑如下:
- 写入消息到磁盘
- 更新 LEO 值
- 更新分区高水位值
- 获取 leader 副本所在 Broker 保存的所有远程副本 LEO 值,如:
LEO-1、LEO-2、LEO-3....... - 获取 Leader 副本的高水位值:
currentHW - 更新高水位为:
HW = Math.max(currentHW,Math.min(LEO-1,LEO-2,LEO-3....));
- 获取 leader 副本所在 Broker 保存的所有远程副本 LEO 值,如:
- 处理 Follower 副本拉取消息的逻辑如下:
- 读取磁盘(页缓存)中的消息数据
- 使用 Follower 副本发送消息请求中的位移值更新远程副本 LEO 值
- 更新分区高水位值(同上)
Follower 副本
- 从 Leader 拉取消息的处理逻辑如下:
- 写入消息到本地磁盘,更新 LEO 值
- 更新高水位
- 获取 Leader 发送的高水位值:
currentHW - 获取步骤 2 中更新的 LEO 值:
currentLEO - 更新高水位为:
HW = Math.min(currentHW, currentLEO);
- 获取 Leader 发送的高水位值:
3、副本同步机制
我来举一个实际的例子,说明一下 Kafka 副本同步的全流程。该例子使用一个单分区且有两个副本的主题。
当生产者发送一条消息时,Leader 和 Follower 副本的高水位是怎么被更新的
首先是初始状态,这里的 Remote LEO 代表之前我们 Broker0 中的远程副本的 LEO,我们的 Follower 副本通过 FETCH 请求不断与 Leader 副本进行数据同步

3.1 第一次同步
当生产者给我们的主题分区发送一条消息后,状态变更为:
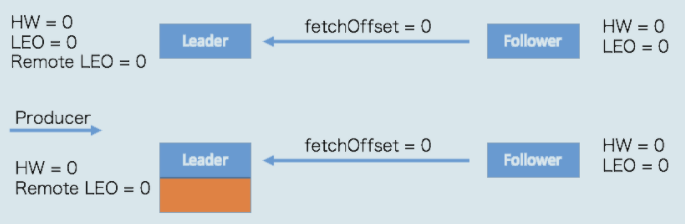
我们上面讲过,关于 Leader 副本处理生产者的逻辑
- 写入磁盘,更新
LEO = 1 - 更新高水位
- 当前的高水位为:0
- 当前远程副本的LEO为:0
- 所以:
HW = Math.max(0,0) = 0

Follow 副本尝试从 Leader 拉取消息,和之前不同的是,这次有消息可以拉取了,因此状态进一步变更为:

我们上面讲过,Leader 副本处理 Follower 副本拉取消息的逻辑
- 读取磁盘(页缓存)中的消息数据
- 使用 Follower 副本发送消息请求中的位移值更新远程副本 LEO 值(Remote LEO)
Remote LEO = fetchOffset = 0
- 更新分区高水位值**(无变化、省略)**
我们上面讲到,Follower 副本从 Leader 拉取消息的处理逻辑
- 写入消息到本地磁盘,更新 LEO 值为 1
- 更新高水位
- 获取 Leader 发送的高水位值:
currentHW = 0 - 获取步骤 2 中更新的 LEO 值:
currentLEO = 1 - 更新高水位为:
HW = 0
- 获取 Leader 发送的高水位值:
经过这一次拉取,我们的 Leader 和 Follower 副本的 LEO 都是 1,各自的高水位依然是0,没有被更新。
3.2 第二次同步
它们需要在下一轮的拉取中被更新,如下图所示:

Leader 副本处理 Follower 副本拉取消息的逻辑
- 读取磁盘(页缓存)中的消息数据
- 使用 Follower 副本发送消息请求中的位移值更新远程副本 LEO 值(Remote LEO)
Remote LEO = fetchOffset = 1
- 更新分区高水位值
- LEO 值:
Remote LEO = 1 - Leader 高水位值:
currentHW = 0 - 高水位值:
HW = Math.max(0,1) = 1
- LEO 值:
Follower 副本从 Leader 拉取消息的处理逻辑
- 写入消息到本地磁盘,更新 LEO 值(无变化)
- 更新高水位
- 获取 Leader 发送的高水位值:
currentHW = 1 - 获取步骤 2 中更新的 LEO 值:
currentLEO = 1 - 更新高水位为:
HW = Math.min(1,1) = 1
- 获取 Leader 发送的高水位值:
至此,一次完整的消息同步周期就结束了。事实上,Kafka 就是利用这样的机制,实现了 Leader 和 Follower 副本之间的同步。
五、Leader Epoch 闪耀登场
依托于高水位,我们不仅向外界定义了消息的可见性,又实现了副本的同步机制。
俗话说的好:人无完人,物无完物
我们需要思考思考,这种副本同步机制会有什么危害呢?
1、数据丢失
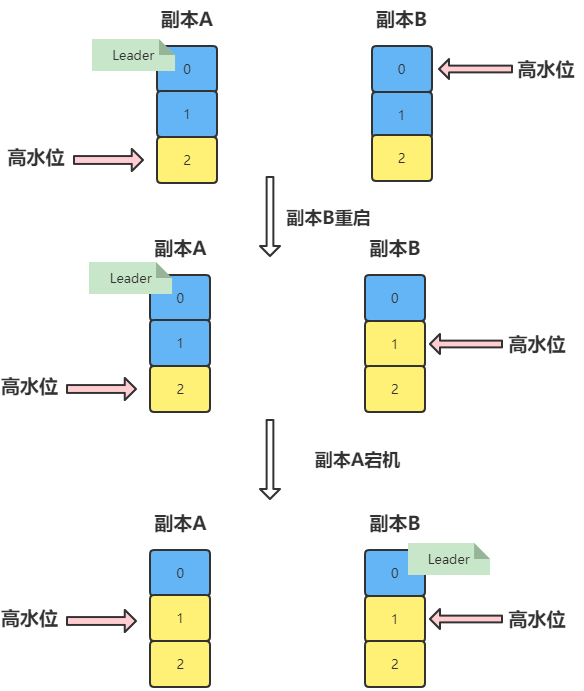
- 蓝色:已落磁盘的数据
- 黄色:无任何数据
当我们的副本进行第二次同步时,假如在 Follower 副本从 Leader 拉取消息的处理逻辑 这里,我们的副本B重启了机器。
等到 副本B 重启成功后,副本B 会执行日志截断操作(根据高水位的数值进行截断),将 LEO 值调整为之前的高水位值,也就是 1。位移值为 1 的那条消息被副本 B 从磁盘中删除,此时副本 B 的底层磁盘文件中只保存有 1 条消息,即位移值为 0 的那条消息。
当执行完截断日志的操作后,副本B开始从副本A拉取消息,进行正常的消息同步。这时候副本A重启了,我们会让我们的副本B成为 Leader。
当副本A重启成功时,会自动向 Leader 看齐,此时,当 A 回来后,需要执行相同的日志截断操作,即将高水位调整为与 B 相同的值,也就是 1。
这样操作之后,位移值为 1 的那条消息就从这两个副本中被永远地抹掉了,这就是这张图要展示的数据丢失场景。
2、数据不一致
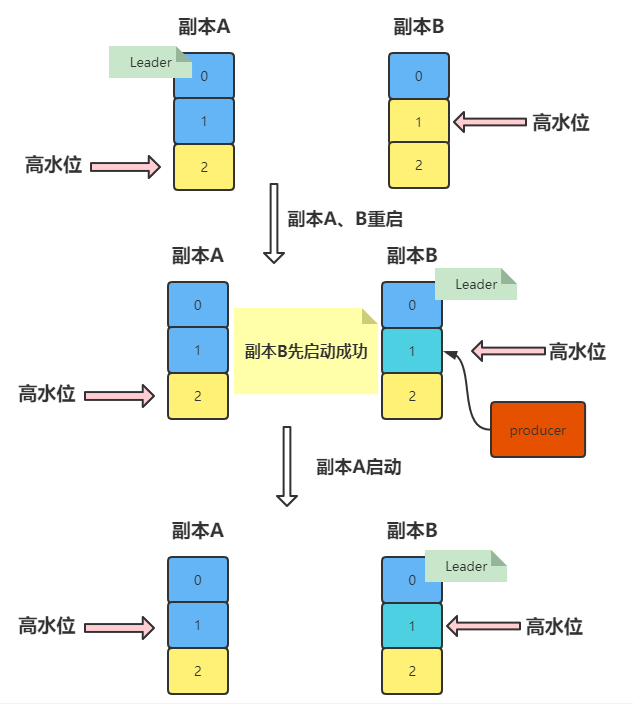
当我们的副本B想要同步副本A的消息时,这个时候,副本A和副本B都发生了重启的操作
我们的副本B先启动成功,成功当选 Leader,这个时候我们的生产者会将数据发送到副本B中,也就是图中的 1
等到副本A启动成功时,会与 Leader 副本进行同步,发现 Leader副本的 LEO 和 HW 都为1,这个时候,副本A不需要进行任何操作
我们观察结果,可以看到,我们副本A的数据和副本2的数据发生了不一致的现象
3、Leader Epoch
简单来说,Leader Epoch是一对值:(epoch,offset)
- epoch:代表当前 leader 的版本号,从0开始,当 Leader 变更过一次时,我们的 epoch 就会 +1
- offset:该 epoch 版本的 Leader 写入第一条消息的位移
我们以下面的例子解释一下:(0,0)(1,120)
第一个 Leader 版本号为0,从位移 0 开始写入消息,一共写了120条,也就是 [0,119]
第二个 Leader 版本号为1,从位移 120 开始写入消息
leader broker 中会保存这样的一个缓存,会定期的写入到一个 checkpoint 中
当 Leader 写底层 log 时,他会尝试更新整个缓存。如果这个 Leader 是第一次写消息,则会在缓存中增添一个条目,否则就不做更新
每次副本重新成为 Leader 时,会查询这部分缓存,获取出对应 Leader 版本的位移,避免了数据丢失和不一致的情况
3.1 如何规避数据丢失
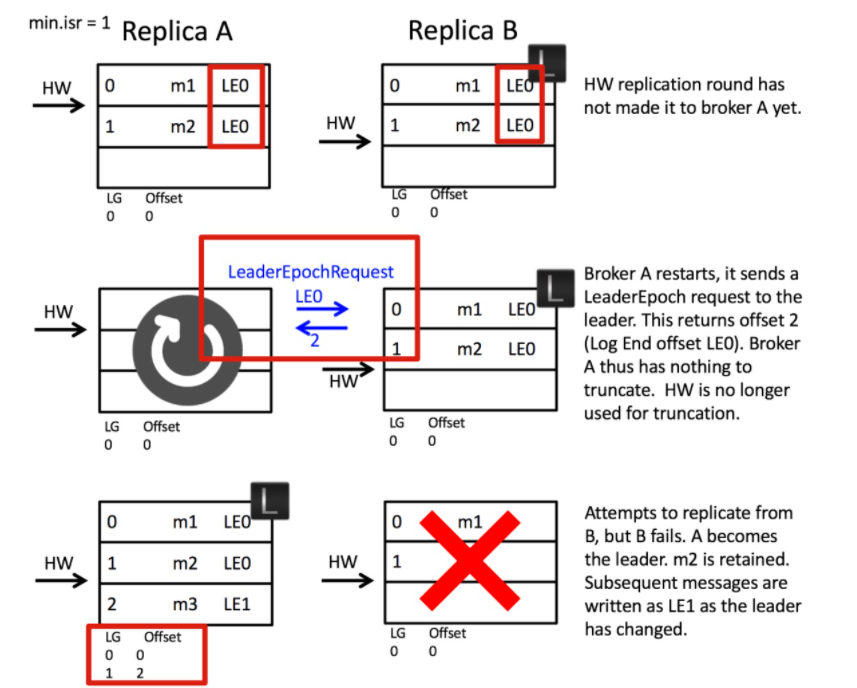
当我们的 副本A 重启完毕时,它会向 leader副本B 发送一个 LeaderEpochRequest 请求,来获取自身所处的 leader epoch 最新的偏移量是多少。
因为 followerA 和 Leader副本B 所处的时代相同(leader epoch编码都是0),Leader副本B 会返回自己的 LEO,也就是 2 给 Follower副本A
当我们的副本A收到 LEO = 2,自己的位移量都小于 2,不需要做任何的操作
这是对高水位机制的一个明显改进,即副本是否执行日志截断不再依赖于高水位进行判断。
3.2 如何规避数据不一致
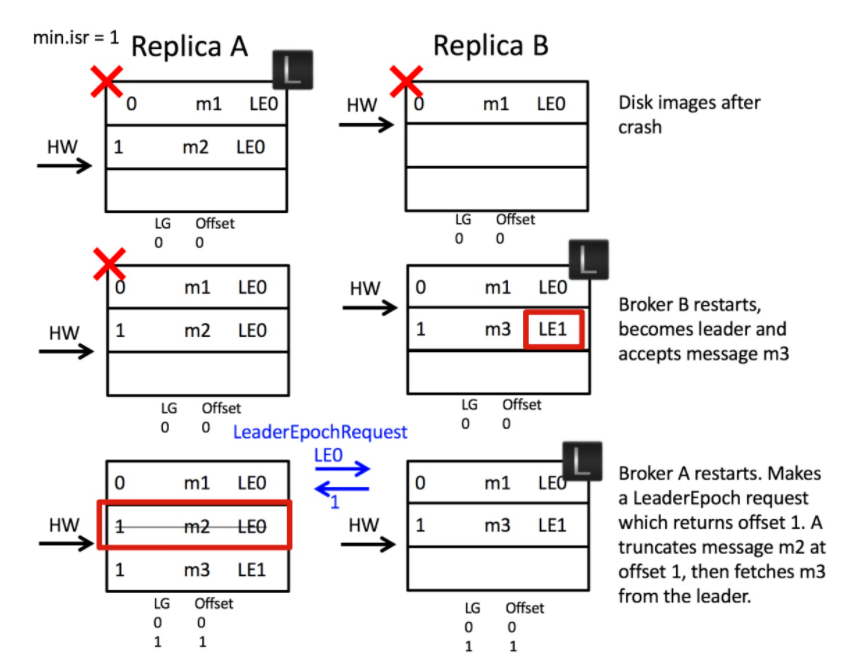
开始的时候 副本A 是 leader副本,当两个 broker 在崩溃后重启后,brokerB 先成功重启,Follower副本B 成为 Leader副本
它会开启一个新的领导者纪元 Leader1,开始接受消息 m3
然后 brokerA 又成功重启,此时 副本A 很自然成为 Follower副本A,接着它会向 Leader B 发送一个 LeaderEpoch request 请求,用来确定自己应该处于哪个领导者时代,Leader B 会返回 Leader1 时代的第一个位移,这里返回的值是1(也就是m3所在的位移)。follower B 收到这个响应以后会根据这个 位移1 来截断日志,它知道了应该遗弃掉m2,从位移1开始同步获取日志。
六、总结
通过 Leader Epoch 的机制,我们让我们副本的日志截断不单单依靠高水位的值
关键点快速总结:
-
高水位的2个主要作用
-
定义消息可见性
-
帮助Kafka完成副本同步
-
-
在分区高水位以下的消息被认为是已提交消息,反之就是未提交消息。消费者只能消费已提交消息。
-
日志末端位移(LEO) :表示副本写入下一条消息的位移值。
-
Leader Epoch:这是Leader版本。它由两部分数据组成(Epoch,offset)
- Epoch(单调增加的版本号):每当副本领导权发生变更时,都会增加该版本号。小版本号的Leader被认为是过期Leader。
- offset(起始位移) :**Leader副本 **在该 Epoch 值上写入的首条消息的位移。
在讲述 kafka 之前,博主一直不知道从哪里下手,从基础架构又过于保守,从源码又过于复杂,最终决定从副本机制的同步入手,毕竟面试的老选手了
今天的 kafka 的副本同步机制到这里就结束了,下一期将会讲述 kafka 的基本架构








