相比于同时期的VggNet,GoogLeNet可以说是进行了一步有趣的创新探索,其一定程度上改变了我们熟知的CNN架构。我们一起来看一下它到底做了哪些改变以及背后的思考。
首先,我们先把模型的代码放上来:
class GoogleNet:
def build(width,height,depth,classes):
weight_decay=0.0005
inputShape=(height,width,depth)
axis=3
if K.image_data_format()=="channels_first":
inputShape=(depth,height,width)
axis=1
def Conv(kernels,size,padding="same",strides=(1,1)):
return Conv2D(kernels,size,strides=strides,padding=padding,
activation="relu",kernel_initializer='he_normal',
kernel_regularizer=l2(weight_decay))
def Inception(inputs,kernel1,kernel1_3,kernel3,kernel1_5,kernel5,
kernel_pool_1):
channel1=Conv(kernel1,(1,1))(inputs)
channel1_3=Conv(kernel1_3,(1,1))(inputs)
channel3=Conv(kernel3,(3,3))(channel1_3)
channel1_5=Conv(kernel1_5,(1,1))(inputs)
channel5=Conv(kernel5,(5,5))(channel1_5)
maxchannel=MaxPooling2D(pool_size=(3,3),strides=(1,1),padding="same")(inputs)
channel_pool=Conv(kernel_pool_1,(1,1))(maxchannel)
outputs=Concatenate(axis=axis)([channel1,channel3,channel5,channel_pool])
return outputs
def branch(inputs,name):
net=AveragePooling2D(pool_size=(5,5),strides=3)(inputs)
net=Conv(128,(1,1))(net)
net=Flatten()(net)
net=Dense(512,activation="relu",kernel_initializer='he_normal',
kernel_regularizer=l2(weight_decay))(net)
net=Dropout(0.7)(net)
net=Dense(classes,activation="softmax",name=name)(net)
return net
X=Input(shape=inputShape)
net=Conv(64,(7,7),strides=(2,2))(X)
net=MaxPooling2D(pool_size=(3,3),padding="same",strides=(2,2))(net)
net=Conv(64,(1,1))(net)
net=Conv(192,(3,3))(net)
net=MaxPooling2D(pool_size=(3,3),padding="same",strides=(2,2))(net)
net=Inception(net,64,96,128,16,32,32)
net=Inception(net,128,128,192,32,96,64)
net=MaxPooling2D(pool_size=(3,3),padding="same",strides=(2,2))(net)
net=Inception(net,192,96,208,16,48,64)
branch1=branch(net,name="branch1")
net=Inception(net,160,112,224,24,64,64)
net=Inception(net,128,112,224,24,64,64)
net=Inception(net,112,144,288,32,64,64)
branch2=branch(net,name="branch2")
net=Inception(net,256,160,320,32,128,128)
net=MaxPooling2D(pool_size=(3,3),padding="same",strides=(2,2))(net)
net=Inception(net,256,160,320,32,128,128)
net=Inception(net,384,192,384,48,128,128)
net=GlobalAveragePooling2D()(net)
net=Dropout(0.4)(net)
outputs=Dense(classes,activation="softmax",name="outputs")(net)
return [X,outputs,branch1,branch2]
可能看着有点多,但其实已经比摊开来写简短许多。这是因为GoogLeNet包括许多Inception和一些中间分支,这些区块大部分都是高度重复的,所以我们总结规律后把他们写成一个函数,来调用实现。
Inception
GoogLenet最特别的地方大概就是这个子块了,我们看看作者为什么会提出这个东西。
Inception架构的主要想法是考虑怎样近似卷积视觉网络的最优稀疏结构并用容易获得的密集组件进行覆盖。
这里我们注意一个关键词,稀疏结构(sparse structure)。
我们先以我们的视觉为例子,在我们的视觉皮层有许多细胞。在观察外界时,每一个细胞其实只对我们整体视觉区域的一部分产生反映。这种局部敏感我们就叫做稀疏,我们平时使用的卷积其实就是一个稀疏连接,与之相反,全连接层则是对全局敏感,所以我们后面充当隐藏层的全连接层将被替换为全局平均池化。
对于卷积层,作者也希望找到一个更优的稀疏结构而不是单纯地照搬以前传统的叠加方法。
我们的网络将以卷积构建块为基础。我们所需要做的是找到最优的局部构造并在空间上重复它。
这句话可以和下面这句连起来看。
分析最后一层的相关统计并将它们聚集成具有高相关性的单元组。
在解释之前,我再引入一个Hebbian原理:两个神经元或者神经元系统,如果总是同时兴奋,就会形成一种‘组合’,其中一个神经元的兴奋会促进另一个的兴奋。即这两个神经元是高度相关的,又或者说这两个神经元所处的局部结构在空间上是高度重复的。
那么我们如何来确定神经元之间的高度相关性呢?
我们假设较早层的每个单元都对应输入层的某些区域,并且这些单元被分成滤波器组。在较低的层(接近输入的层)相关单元集中在局部区域。因此,我们最终会有许多聚类集中在单个区域。
同时受多尺寸训练的启发,我们开始考虑不同大小卷积核运算的结果是否会存在相关性?即,小卷积核感受到局部视野区域,我们用大一点的卷积核感受到这局部视野区域(会比小卷积核略大,因为包括了周边区域),如果是高度相关的,它们应该是会被聚类在某一区域内。
所以一开始的Inception包括了几种类型的卷积,以得到不同大小卷积核运算的结果并合并进行计算。
由于较高层会捕获较高的抽象特征,其空间集中度预计会减少。这表明随着转移到更高层,3×3和5×5卷积的比例应该会增加。
在改进版的Inception中,我们添加了更多的1 × 1的卷积核。
1 × 1卷积有两个目的:最关键的是,它们主要是用来作为降维模块来移除卷积瓶颈,否则将会限制我们网络的大小。这不仅允许了深度的增加,而且允许我们网络的宽度增加但没有明显的性能损失。
该架构的一个有用的方面是它允许显著增加每个阶段的单元数量,而不会在后面的阶段出现计算复杂度不受控制的爆炸。这是在尺寸较大的块进行昂贵的卷积之前通过普遍使用降维实现的。此外,设计遵循了实践直觉,即视觉信息应该在不同的尺度上处理然后聚合,为的是下一阶段可以从不同尺度同时抽象特征。
全局平均池化 GAP (Global Average Pooling)
在前面我们提到,作者为了实现更优的稀疏结构,将会移除掉全连接层。
我们发现从全连接层变为平均池化,提高了大约top-1 %0.6的准确率,然而即使在移除了全连接层之后,dropout的使用还是必不可少的。
GAP的思路是使用GAP来替代该全连接层(即使用池化层的方式来降维),更重要的一点是保留了前面各个卷积层和池化层提取到的空间信息\语义信息,所以在实际应用中效果提升也较为明显。
GAP直接从 feature map 的通道信息下手。假设我们最后一层的卷积输出的 feature map 就只有N个通道,然后对这个 feature map 进行全局池化操作,获得长度为N的向量,这就相当于直接赋予了每个通道类别的意义。同时,相对于全连接层来说,减少了大量的参数。
辅助分类器
GoogLenet还有一个别致的设计,就是这个辅助分类器,也就是我们前文提到的分支。
它是通过在网络架构中间选取两点,将这两个输出来进行结果的分类。这两个结果以及我们最终得到的结果会进行一个加权求和来共同决定我们的权重。
在这个任务上,更浅网络的强大性能表明网络中部层产生的特征应该是非常有识别力的。通过将辅助分类器添加到这些中间层,可以期望较低阶段分类器具有更好的判别力。这被认为是在提供正则化的同时克服梯度消失问题。
结果
我们的数据集包括5000张训练集和1000张测试集。对象是动物,分为三类。
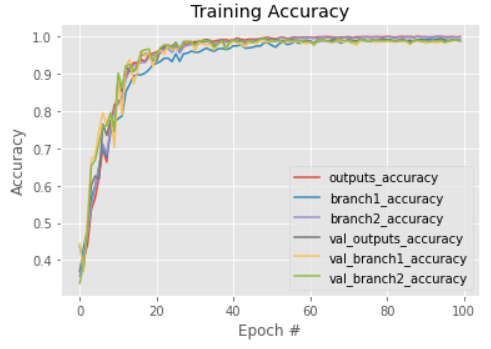
对于结果来说,网络收敛得非常快。在40次的时候已经接近瓶颈了,精度也是在0.99波动。
比较三个分支,可能图里看不太清楚。第一个分支结果(浅层网络)的精确度是一直略小于另外两个结果的,另外两个并没有太大的差别。虽然差别不大,但中层网络的结果的震荡幅度是大于深层网络的。