上篇文章安装了Crawlab,现在开始使用。
0.6.0beta目前有问题,建议稳定版出了再用,所以本文用截止发布文章时的最新稳定版0.5.1。
本文最核心的内容在文档中,即配置scrapy爬虫和单个py文件爬虫所需的设置。
先说一下,如果在Crawlab中运行爬虫时提示没有库,看文档。
scrapy爬虫
文档
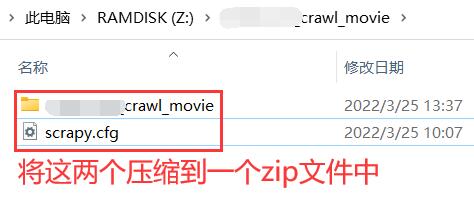
将上图压缩后的zip文件上传,上传时开启是否为Scrapy。另外,上传时有提示要从根目录下开始压缩爬虫文件,文档中也有说。
上传后,从文件中打开py代码文件,在settings.py中找到 ITEM_PIPELINES,添加
ITEM_PIPELINES = {
'crawlab.pipelines.CrawlabMongoPipeline': 888,
}也可以上传前先添加。这就会将数据保存到上篇文章中自己设置的数据库中,然后再启动爬虫。
单个py文件的爬虫
同样需将py文件压缩成zip后上传。
上传后,在保存数据的地方添加
# 引入保存结果方法
from crawlab import save_item
# 这是一个结果,需要为 dict 类型
result = {'name': 'crawlab'}
# 调用保存结果方法
save_item(result)也可以上传前先添加。这就会将数据保存到上篇文章中自己设置的数据库中,然后再启动爬虫。
另外,对于单文件爬虫,如果代码中需要通过终端的用户输入来给变量赋值,则可以用下面的写法
import sys
start_page_number = int(sys.argv[1])
end_page_number = int(sys.argv[2])
print(start_page_number)
print(end_page_number)添加爬虫时需在执行命令处写python py文件名 变量值1 变量值2,如python 1.py 5 10,这样运行后sys.argv[1]的值就是5,sys.argv[2]的值就是10,sys.argv[0]的值是1.py。

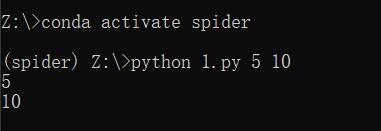
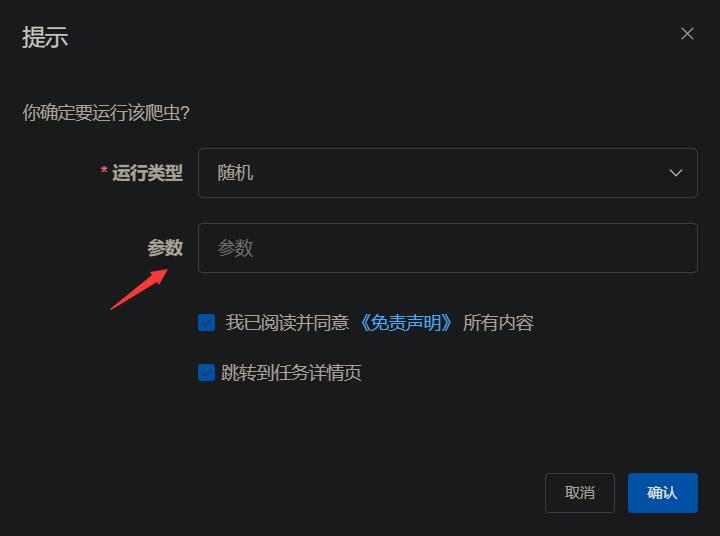
如果添加爬虫时的执行命令中不写参数,也可以在运行爬虫时的弹窗中写参数,如图中可以写5 10,这样就将5和10分别传给sys.argv[1]和sys.argv[2]。在这里写参数,比在添加爬虫时的执行命令中更灵活,因可能每次运行所需的参数不同,如这一次爬取第1到10页,传入1 10,下一次爬取第11到20页,传入11 20;若写在添加爬虫时的执行命令中就写死了,每次运行都得先修改执行命令为期望的值再运行。