一、背景:
一个做展会的小伙伴儿找到我,希望能帮他采集某一类目的1688厂家信息,然后邀请他们参加展会。
二、设计思路如下:
- 采用 Python3 语言编码 , 工具 PyCharm;
- 模仿真实用户登录1688,使用Selenium + Google Chrome + chromedriver.exe;
备注1:Google Chrome + chromedriver.exe版本对应参考链接
备注2:Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。
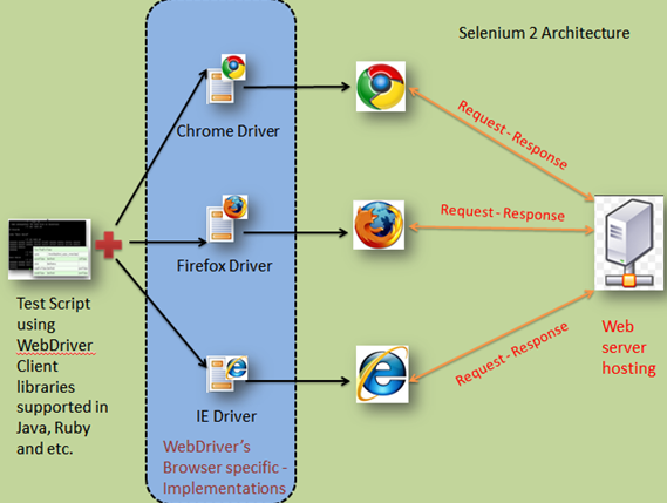
- 对1688的超频次访问限制策略,采用sleep等待重试的策略解决。
- 以excel表格的形式保存结果。
三、功能实现:
关键代码
def get_url_list(self):
beginPage = 1
while beginPage < 100:
try:
httpDone = ('http://s.1688.com/company/company_search.htm?n=y&netType=1,11&encode=utf-8&keywords=%s&beginPage=%d') % (
self.keyword_encode, beginPage)
print("parsettt 页码", beginPage, httpDone)
self.browser.get(httpDone)
nodes = self.browser.find_elements_by_xpath('//a[@class="list-item-title-text"]')
if len(nodes) == 0:
print("parsettt 未找到节点------------------", beginPage)
if self.browser.page_source.find("滑动一下马上回来") >=0 :
seconds = random.randint(self.min_seconds, self.max_seconds)
print("parsettt sleep s,程序被限制,滑动一下马上回来 ", seconds, beginPage)
time.sleep(seconds)
continue
else :
print("parsettt 结束 exit---------------------", beginPage)
break
else:
self.url_list = []
print("parsettt 找到节点----------------", len(nodes), len(self.url_list))
for node in nodes:
url = node.get_attribute('href')
title = node.get_attribute('title')
# 去重处理
if url not in self.url_list:
self.url_list.append(url)
for url in self.url_list:
self.save_gys_info(url)
beginPage = beginPage + 1
print("")
except Exception as e:
print("error", e)
time.sleep(30)- 配置文件
{
"chrome": "",
"chromedriver": "chromedriver.exe",
"keyword": "服装",
"min_seconds": 600,
"max_seconds": 720
}- 结果展示
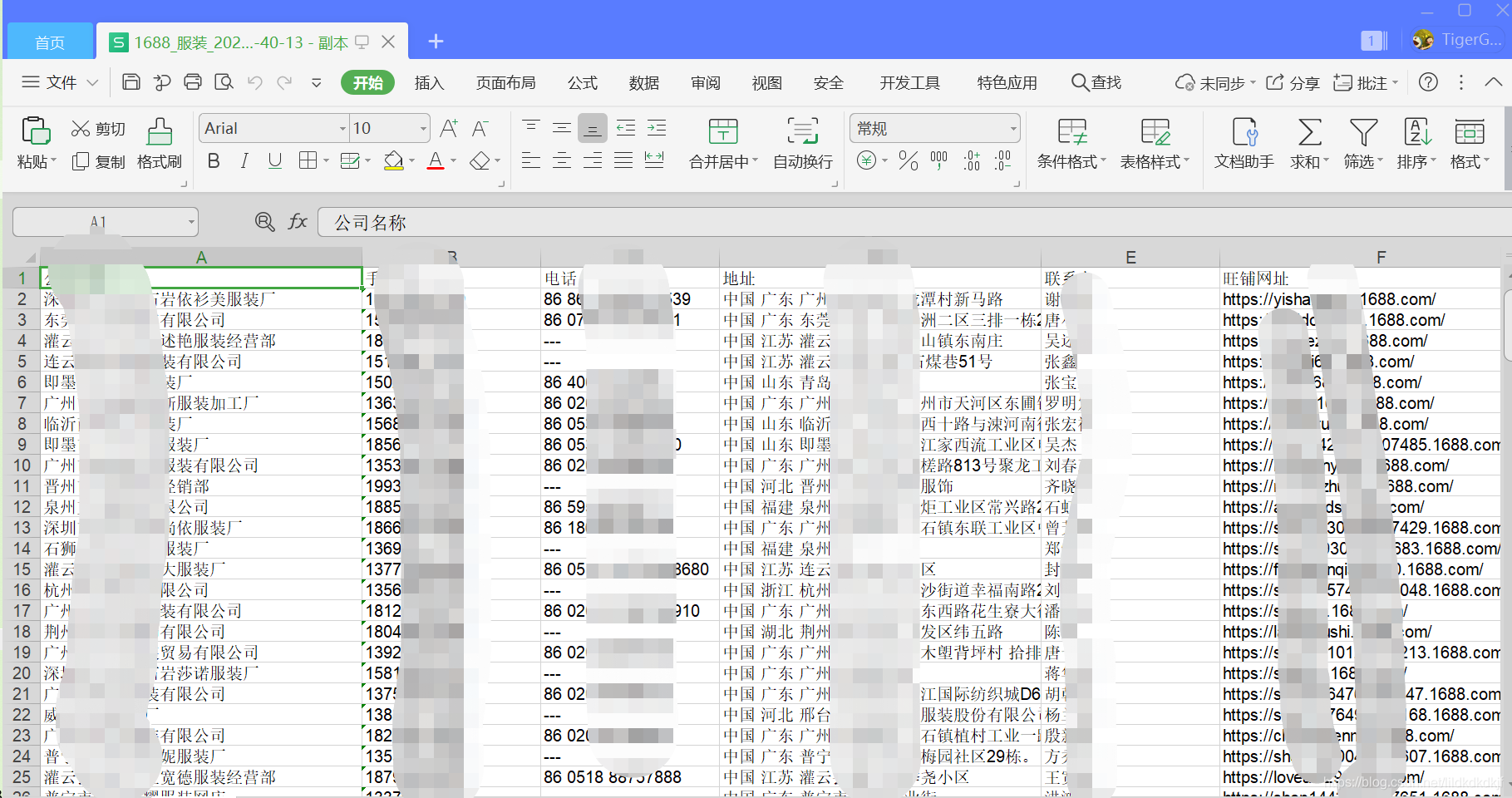
四、总结
节前实现了这个功能,交付给了小伙伴儿,他很满意,因为他节省了时间和精力去做更有创造力的事情。
本次分享结束,欢迎讨论










