默认情况下,Spark程序运行完毕关闭窗口之后,就无法再查看运行记录的Web UI(4040)了,但通过 HistoryServer 可以提供一个服务, 通过读取日志文件, 使得我们可以在程序运行结束后, 依然能够查看运行过程。本篇博客,博主就为大家带来在Spark上配置JobHistoryServer的详细过程。

1.进入到spark安装目录下的conf文件夹
cd /export/servers/spark/conf
2.修改配置文件名称
vim spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node01:8020/sparklog注意:HDFS上的目录需要提前存在
hadoop fs -mkdir -p /sparklog
3.修改spark-env.sh文件
vim spark-env.sh
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000
-Dspark.history.retainedApplications=3
-Dspark.history.fs.logDirectory=hdfs://node01:8020/sparklog"参数描述:
spark.eventLog.dir:Application在运行过程中所有的信息均记录在该属性指定的路径下;
spark.history.ui.port=4000 WEBUI访问的端口号为4000
spark.history.fs.logDirectory=hdfs://node01:8020/sparklog 配置了该属性后,在start-history-server.sh时就无需再显式的指定路径,Spark History Server页面只展示该指定路径下的信息
spark.history.retainedApplications=30指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
4.同步配置文件
这里可以用scp命令,也可以用xsync自定义的命令,关于如何使用xsync请参考<带你书写linux超实用的脚本——xcall(同步执行命令)与xsync(同步文件目录)>
xsync spark-defaults.conf
xsync spark-env.sh
5.重启集群
/export/servers/spark/sbin/stop-all.sh /export/servers/spark/sbin/start-all.sh
6.在master上启动日志服务器
/export/servers/spark/sbin/start-history-server.sh
7.运行一个计算PI的实例程序
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--executor-memory 1G \
--total-executor-cores 2 \
/export/servers/spark/examples/jars/spark-examples_2.11-2.2.0.jar \
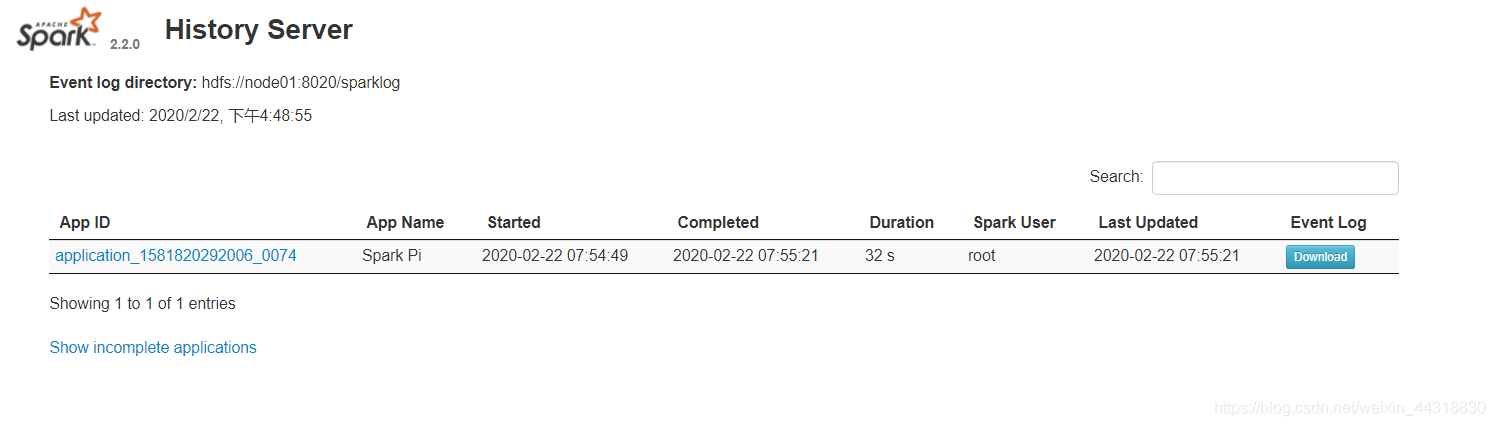
100待运行完毕之后,从浏览器输入http://node01:4000/
- 如果遇到Hadoop HDFS的写入权限问题:
org.apache.hadoop.security.AccessControlException
解决方案:
在hdfs-site.xml中添加如下配置,关闭权限验证
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>本次的分享就到这里,受益的小伙伴或对大数据技术感兴趣的朋友记得点赞关注小菌哟~











