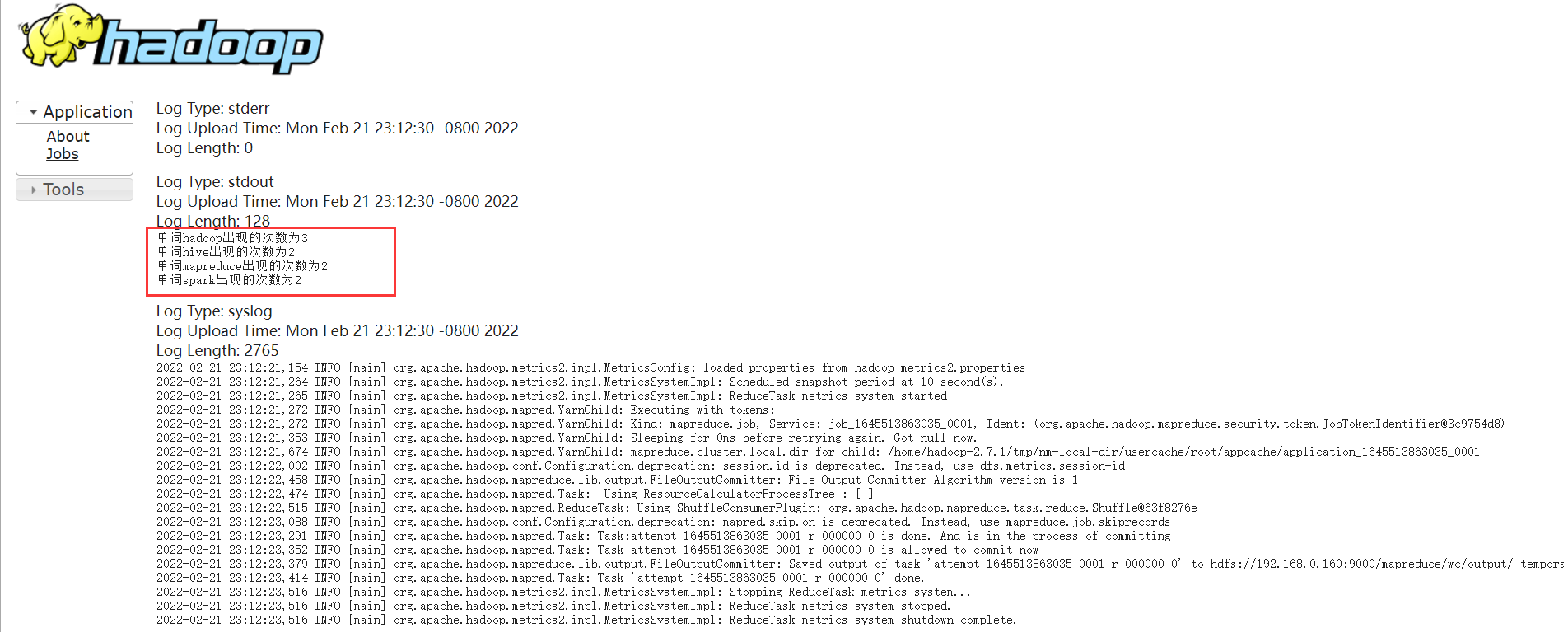
MapReudce在集群上运行时查询System.out的结果
准备工作
- 我们在使用MapReduce在集群上运行时,常常为了方便而使用System.out,但是却无法显示在控制台上,往往我们就需要去日志里面寻找
- 本次所使用到的数据

- 本次使用的代码
package WC;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountTest {
public static class WCMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
IntWritable v = new IntWritable();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split(" ");
for (String word : words) {
context.write(new Text(word), v);
}
}
}
public static class WCReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable count : values) {
sum += 1;
}
context.write(key, new IntWritable(sum));
System.out.println("单词" + key.toString() + "出现的次数为" + sum);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(WordCountTest.class);
job.setMapperClass(WCMapper.class);
job.setReducerClass(WCReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path("hdfs://192.168.0.160:9000/mapreduce/wc/input"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.0.160:9000/mapreduce/wc/output"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
-
如果虚拟机使用的是映射,我们常常也需要在window中配置一下,window上的host文件的地址为
C:\Windows\System32\drivers\etc -
开启
historyServer服务启动命令:mr-jobhistory-daemon.sh start historyserver 关闭命令:mr-jobhistory-daemon.sh stop historyserver
查看日志文件
-
登录yarn的UI界面:
localhost:8088 -
找到需要查找项目的编号
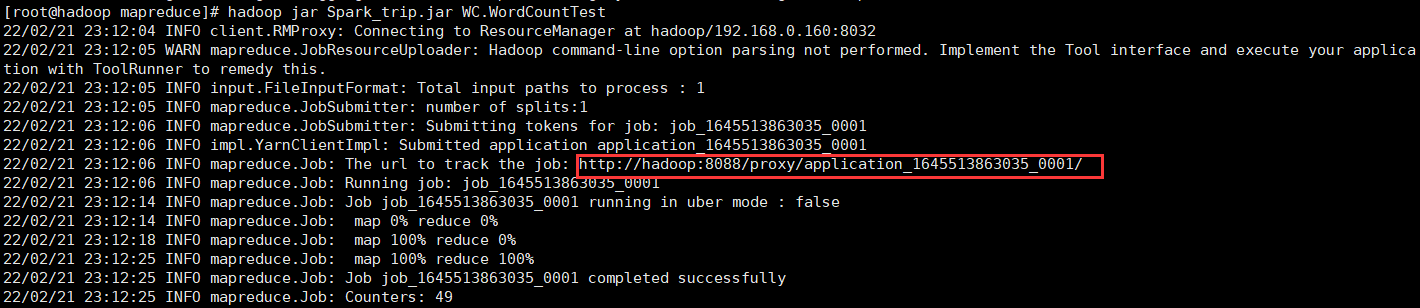
-
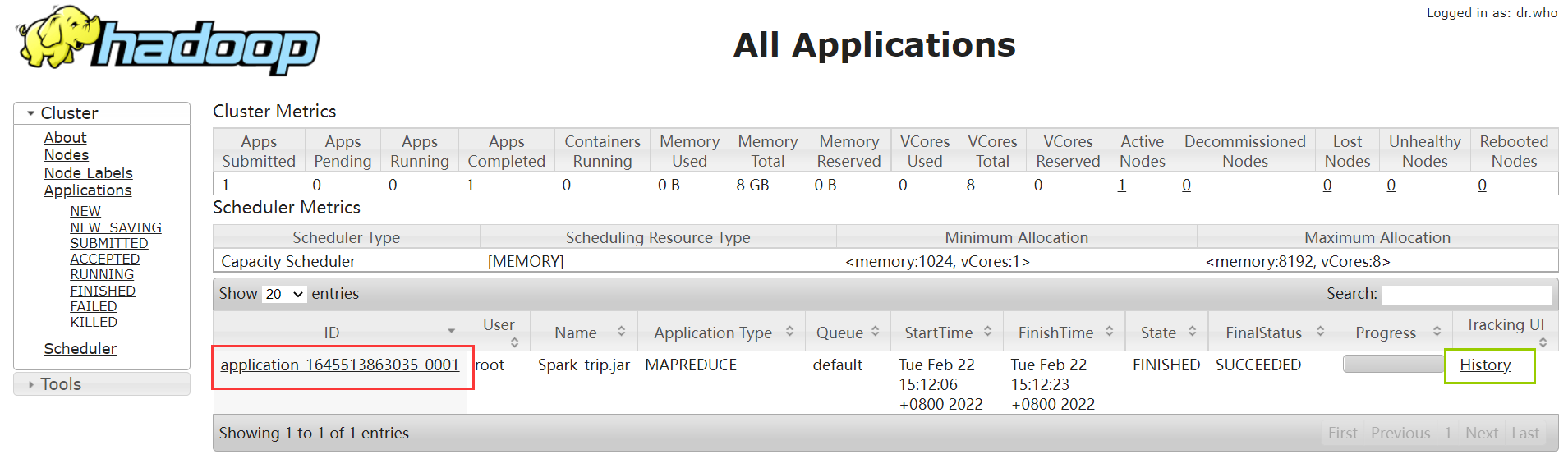
找到对应的项目,点击绿色圈住的地方
-
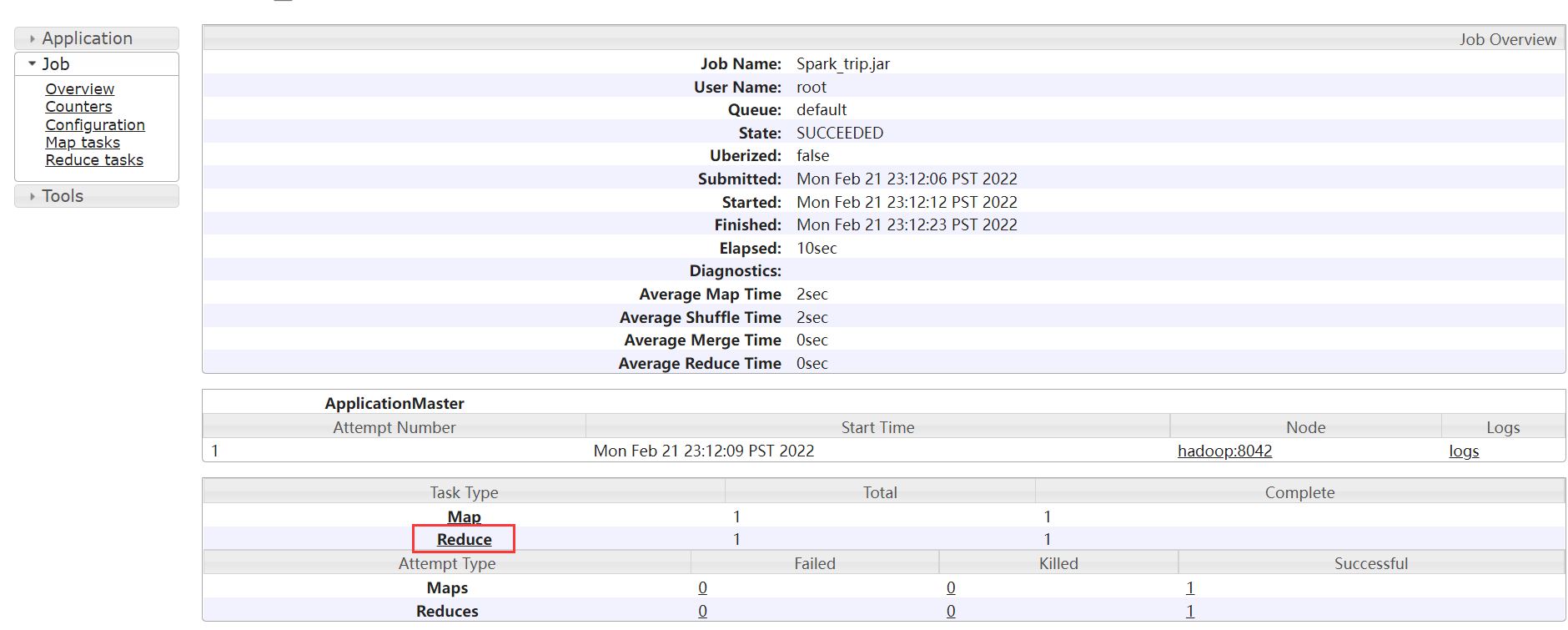
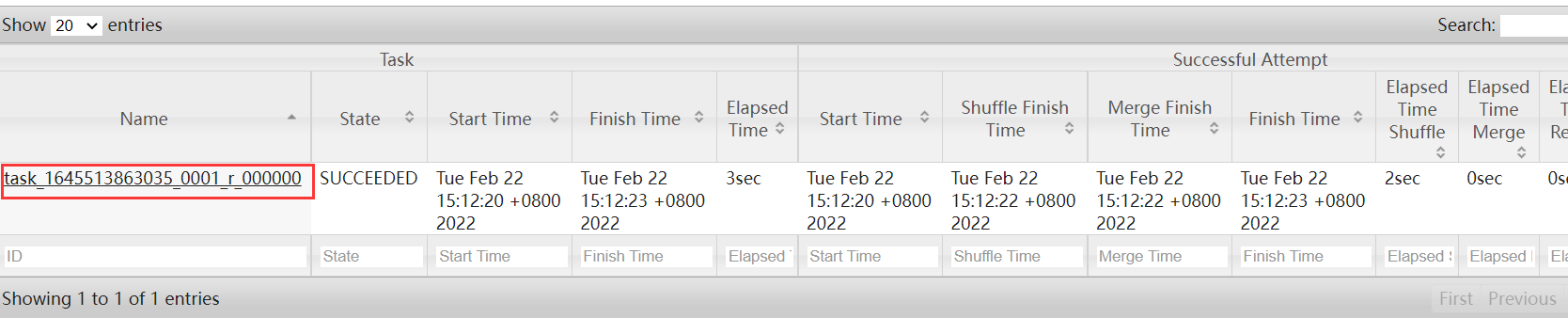
日志都是在reduce阶段产生的
-
继续点击
-
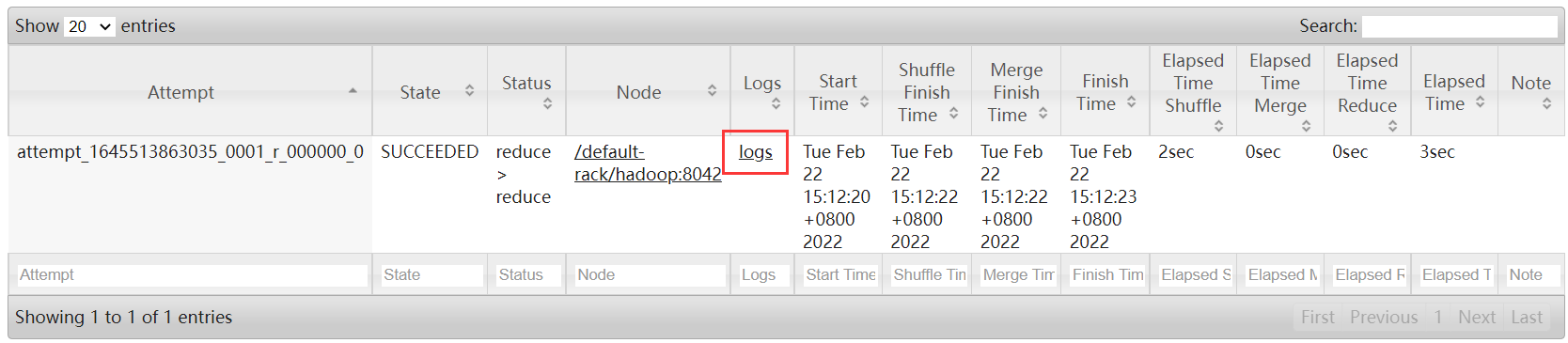
点击logs查看日志
-
如果出现的时下图,请在yarn-site.xml文件里增加

<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>
开启日志聚集功能,任务执行完之后,将日志文件自动上传到文件系统(如HDFS文件系统),
否则通过namenode1:8088页面查看日志文件的时候,会报错
"Aggregation is not enabled. Try the nodemanager at namenode1:54951"
</description>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>302400</value>
<description>
日志文件保存在文件系统(如HDFS文件系统)的最长时间,默认值是-1,即永久有效。
这里配置的值是:7天 = 3600 * 24 * 7 = 302400
</description>
</property>
- 最后应该看到