目录
四.AggregateFunction Mean PV 实践
一.引言
Aggregate 意为聚合,与 Spark 以及 MapReduce 的 reduce 聚合有异曲同工之义。工业场景下一般基于 window 配合使用,达到聚合一定数量或一定时间样本的需求。
二.Aggregate 简介
在 Flink 中主要以 AggregateFunction 的方式存在,其本身是 ReduceFunction 的通用版本。

三.Aggregate Demo
1.AggregateFunction Demo
创建了一个 Tuple2 的统计元组,分别针对 IN 的 value,_.1 累加其值,_.2 累加其出现次数,getResult 返回 _.1 / _.2,可以理解该 AverageAggragate 为平均值统计,根据窗口类型为 CountWindow 或者 TimeWindow 统计一定数据量或一定时间内数据的平均指标。
/**
* The accumulator is used to keep a running sum and a count. The [getResult] method
* computes the average.
*/
class AverageAggregate extends AggregateFunction[(String, Long), (Long, Long), Double] {
override def createAccumulator() = (0L, 0L)
override def add(value: (String, Long), accumulator: (Long, Long)) =
(accumulator._1 + value._2, accumulator._2 + 1L)
override def getResult(accumulator: (Long, Long)) = accumulator._1 / accumulator._2
override def merge(a: (Long, Long), b: (Long, Long)) =
(a._1 + b._1, a._2 + b._2)
}
val input: DataStream[(String, Long)] = ...
input
.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(new AverageAggregate)该方法适用于统计计算窗口中第二个字段的平均值,窗口数据类型 T 为 Tuple2(String, Long)。
2.实践 Source 类
2.1 Event Class
// 用户浏览行为
case class Event(user: String, url: String, timeStamp: Long)采用 Event 作为 DataStream[T] 中的数据类型,其中包含3个字段:
user:用户名称
url:用户访问 URL
timeStamp:用户访问时间
2.2 Source Class
继承 SourceFunction 实现自定义源,用户通过 random.nextInt(256) 模拟 256 个用户,URL 则是模拟了 5 个网址,同样适用 Random 随机生成。更多 DataStream 源生成方法可以参考:Flink / Scala - DataSource 之 DataStream 获取数据总结。
import org.apache.flink.streaming.api.functions.source.SourceFunction
import scala.util.Random
// 用户浏览行为源
class ClickHouse extends SourceFunction[Event] {
var running: Boolean = true
val random: Random = scala.util.Random
val urlList: Array[String] = Array("www.a.com", "www.b.com", "www.c.com", "www.d.com", "www.e.com")
override def run(ctx: SourceFunction.SourceContext[Event]): Unit = {
while (running) {
val user = random.nextInt(256).toString
val url = urlList(random.nextInt(urlList.length))
ctx.collect(Event(user, url, System.currentTimeMillis()))
// 定时生成
Thread.sleep(1000)
}
}
override def cancel(): Unit = {
running = false
}
}后续 UV、PV 实践将基于上述 DataStream[Event] 作为模拟数据源进行统计。
四.AggregateFunction Mean PV 实践
1.AggregateFunction
这里 AggregateFunction 设计到上面提到的4个函数:
import org.apache.flink.api.common.eventtime.{SerializableTimestampAssigner, WatermarkStrategy}
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.api.scala.createTypeInformation
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows
import scala.collection.mutable
class Aggregate_1_MeanPV extends AggregateFunction[Event, mutable.HashMap[String, Long], String] {
override def createAccumulator(): mutable.HashMap[String, Long] = {
new mutable.HashMap[String, Long]()
}
override def add(in: Event, acc: mutable.HashMap[String, Long]): mutable.HashMap[String, Long] = {
if (acc.contains(in.user)) {
acc(in.user) += 1
} else {
acc(in.user) = 1
}
acc
}
override def getResult(acc: mutable.HashMap[String, Long]): String = {
// 窗口闭合时,增量聚合结束,结果发送至下游
val meanPV = acc.values.sum / acc.size.toDouble
val userNum = acc.keySet.size
val valuseSum = acc.values.sum
s"UserNum: $userNum ValuseSum: $valuseSum MeanPV: $meanPV"
}
override def merge(acc: mutable.HashMap[String, Long], acc1: mutable.HashMap[String, Long]): mutable.HashMap[String, Long] = {
null
}
}2.Mean PV Count
demo 采用滑动事件时间窗口,每 2s 统计一次 10s 窗口的 MeanPV 数据,通过 keyBy True 的方法保证所有数据发送到一个 TaskManager 下,当然这里也可以使用 WindowAll 直接汇聚全部数据。
object Aggregate_1_MeanPV {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.addSource(new ClickHouse)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.forMonotonousTimestamps[Event]() // 增序时间事件 WatermarkStrategy
.withTimestampAssigner(new SerializableTimestampAssigner[Event] {
override def extractTimestamp(event: Event, l: Long): Long = event.timeStamp
}))
.keyBy(event => true) // 滑动事件窗口,每2s统计10s窗口的 UVPV
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(2)))
.aggregate(new Aggregate_1_MeanPV())
.print()
env.execute()
}
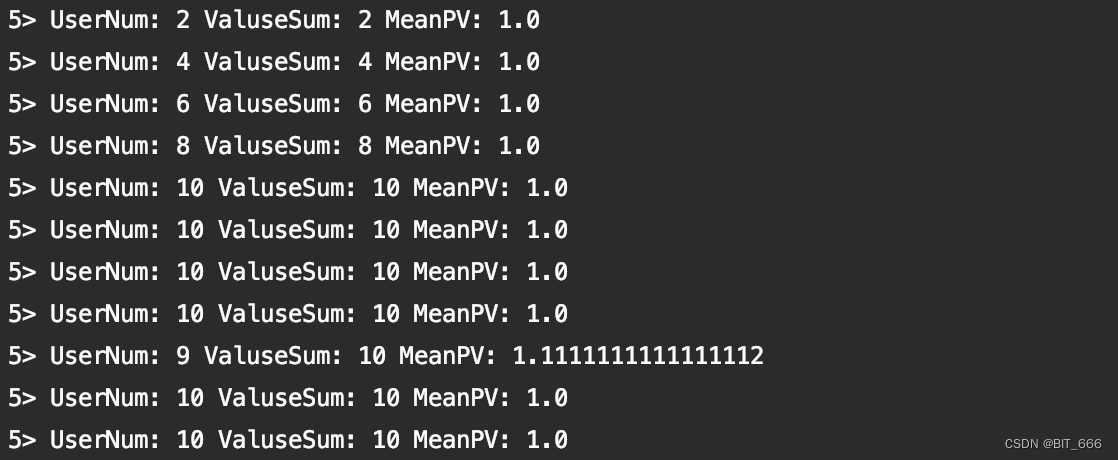
}运行任务可以得到下述结果,由于 Source 生成数据 Sleep(1000),所以10s窗口内最多包含 10 个 User,导致平均 PV 基本都是 1.0。
五.ProcessFunction Total UV 实践
1.ProcessFunction
import org.apache.flink.api.common.eventtime.{SerializableTimestampAssigner, WatermarkStrategy}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.api.scala.createTypeInformation
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
import scala.collection.mutable
object Process_2_TotalUV {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.addSource(new ClickHouse)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.forMonotonousTimestamps[Event]()
.withTimestampAssigner(new SerializableTimestampAssigner[Event] {
override def extractTimestamp(event: Event, l: Long): Long = event.timeStamp
}))
.keyBy(event => true)
.window(TumblingEventTimeWindows.of(Time.seconds(10))) // 滚动10s的窗口
.process(new ProcessWindowFunction[Event, String, Boolean, TimeWindow] {
override def process(key: Boolean, context: Context, elements: Iterable[Event], out: Collector[String]): Unit = {
val set = new mutable.HashSet[String]() // 通过 Set 去重实现 UV 统计
elements.foreach(elem => set.add(elem.user))
val start: Long = context.window.getStart
val end: Long = context.window.getEnd
val log = s"Start: $start End: $end UV: ${set.size}"
out.collect(log)
}
}).print()
env.execute()
}
}使用 10s 的滚动窗口统计相关的访问 UV 数量,这里顺便打印了窗口的 start 和 end 时间,等下通过日志可以观察到 start 和 end 的起止时间,相关的 TimeWindow 起止时间与类型可以参考:Flink - TimeWindow And TimeWindowAll 详解。

取第一条日志的 start 和 end 时间戳查看:
![]()
![]()
可以看到窗口的起止时间是固定的,如果定时为5s,则窗口的启动时间为每 60s 内的 0-5、5-10、10-15 ... 以此类推。
2.可能出现的 Bug
一些同学使用上面代码的 ProcessWindowFunction可能遇到 type mismatch 的问题:

这里是因为 Scala 和 Java 环境下,使用的 ProcessWindowFunction 类型不同:
Java: import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunctionScala: import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction二者在 import 时相差一个 scala,所以使用该样例代码时,需要注意 import 与对应代码匹配。
六. Aggregate URL PV 实践
1.Main Function
上面提到的 ProcessFunction 统计 PV 需要等到窗口完整的数据缓存后再进行迭代的处理,除此之外,Aggregate 提供了一个方法,可以同时传入 ACC 函数与 ProcessWindowFunction,可以对窗口内到达的数据先执行 ACC 进行统计,而最终的 WindowFunction 只是在窗口触发的时候调用,从 ACC 中 getResult 得到总的累加结果,相比于上面的 缓存 + 批处理 的方式,此方式更加优雅,对资源的利用也更加合理。这里先给出 Main 函数,后续给出具体的 ACC 函数与最终处理函数,其思想与 Spark 的 reduceByKey + groupByKey 的分治思想相近。
import org.apache.flink.api.common.eventtime.{SerializableTimestampAssigner, WatermarkStrategy}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.api.scala.createTypeInformation
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
object Aggregate_3_Combine {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.addSource(new ClickHouse)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.forMonotonousTimestamps[Event]()
.withTimestampAssigner(new SerializableTimestampAssigner[Event] {
override def extractTimestamp(event: Event, l: Long): Long = event.timeStamp
}))
// URL 浏览量
stream.keyBy(_.url)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.aggregate(new UrlViewCountAgg, new UrlViewCountResult)
.print()
env.execute()
}
}这里不再通过 keyBy true 使得数据汇总到同一个窗口,而是根据 URL keyBy 最终分别统计每个 URL 的访问量。
2.UrlViewCountAgg
相比于上面的 Mean PV 统计,这里的统计简化了很多,由于只需统计单个 URL 的 PV,所以只需要初始化一个 Long,随后对其累加即可。
import org.apache.flink.api.common.functions.AggregateFunction
class UrlViewCountAgg extends AggregateFunction[Event, Long, Long] {
override def createAccumulator(): Long = {
0L
}
override def add(in: Event, acc: Long): Long = {
acc + 1
}
override def getResult(acc: Long): Long = {
acc
}
override def merge(acc: Long, acc1: Long): Long = {
0L
}
}3.ProcessWindowFunction
最终的处理函数可以理解为最终的 reduce 聚合函数,由于每个 URL 对应一个 ACC,而 ACC 返回唯一的统计 Long,所以 Iterable 虽然是迭代器,其实内部只包含一个数据,就是对应 URL 的 PV 统计,这里获取窗口的 Start 与 End 并返回对应 URL 的 PV 数。
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
class UrlViewCountResult extends ProcessWindowFunction[Long, String, String, TimeWindow] {
override def process(url: String, context: Context, elements: Iterable[Long], out: Collector[String]): Unit = {
val start = context.window.getStart
val end = context.window.getEnd
val viewCount = s"URL: $url Count: ${elements.iterator.next()} Start: $start End: $end"
out.collect(viewCount)
}
}可以看到不同时间窗口下,各个 URL 的访问 PV 也是随机变化的。
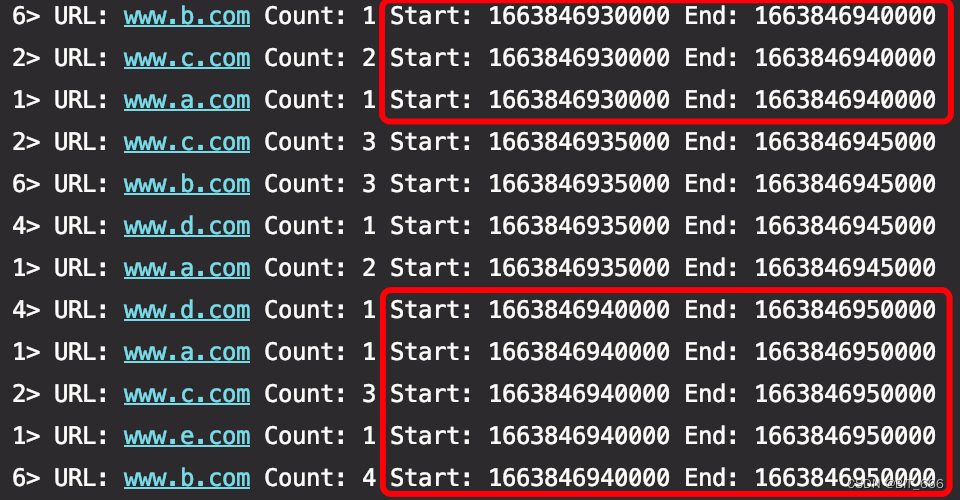
这里总结一下 aggregateFunction + ProcessWindowFunction 的模式,该模式下窗口的主体还是增量聚合逻辑,即 ACC,但是 ProcessWindowFunction 引入了 context 可以获得更多地信息,结合了 AggregateFunction 与 ProcessFunction 的优势,在保证处理性能的同时也支持了实时性,使得其适用于更佳丰富的场景。
七.总结
Aggregate 其实就是运用了 Reduce 的思想,在 Flink CountWindow 中,就是使用 ReduceSum 的 ReduceFunction 实现了元素的 Count 累加,当 ReduceSum 达到了规定的 Count 值,触发 CountWindow,其模式如下:
import org.apache.flink.api.common.functions.ReduceFunction
class ReduceSum() extends ReduceFunction[Long] {
override def reduce(t: Long, t1: Long): Long = {
t + t1
}
}可以看到 ReduceFunction 和 AggregateFunction 的相似之处,二者也师出同源:
====================== ReduceFunction ======================
@FunctionalInterface
@Public
public interface ReduceFunction<T> extends Function, Serializable {
T reduce(T var1, T var2) throws Exception;
}
====================== AggregateFunction ======================
@PublicEvolving
public interface AggregateFunction<IN, ACC, OUT> extends Function, Serializable {
ACC createAccumulator();
ACC add(IN var1, ACC var2);
OUT getResult(ACC var1);
ACC merge(ACC var1, ACC var2);
}









