PG存储结构术语
PostgreSQL中有一些术语与其他数据库中的名称不一样,了解了这些术语的含义,就能更好地看懂PostgreSQL中的文档。与其他数据库不同的术语有如下几个。
Relation:表示表或索引,也就是其他数据库的Table或Index。具体表示的是Table还是Index需要看具体情况。
Tuple:表示表中的行,在其他数据库中使用Row来表示。
Page:表示在磁盘中的数据块。
Buffer:表示在内存中的数据块。
数据库结构
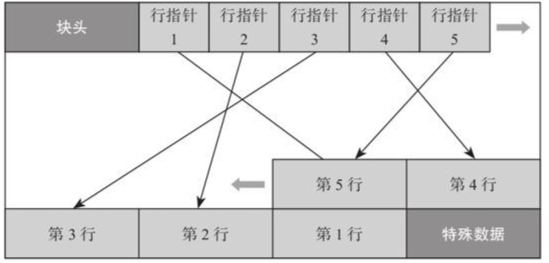
数据块的大小默认是8KB,最大是32KB,一个数据块中存储了多行的数据。块中的结构是先有一个块头,后面记录了块中各个数据行的指针,行指针是向后顺序排列的,而实际的数据行内容是从块尾向前反向排列的。行数据指针与行数据之间的部分就是空闲空间。
块头记录了如下信息:
·块的checksum值。
·空闲空间的起始位置和结束位置。
·特殊数据的超始位置。
·其他一些信息。
行指针是一个32bit的数字,具体结构如下:
·行内容的偏移量,占用15bit。
·指针的标记,占用2bit。
·行内容的长度,占用15bit。
行指针中表示行内容的偏移量是15bit,能表示的最大偏移量是215=32768,因此在PostgreSQL中,块的最大大小是32768,即32KB。
Tuple结构
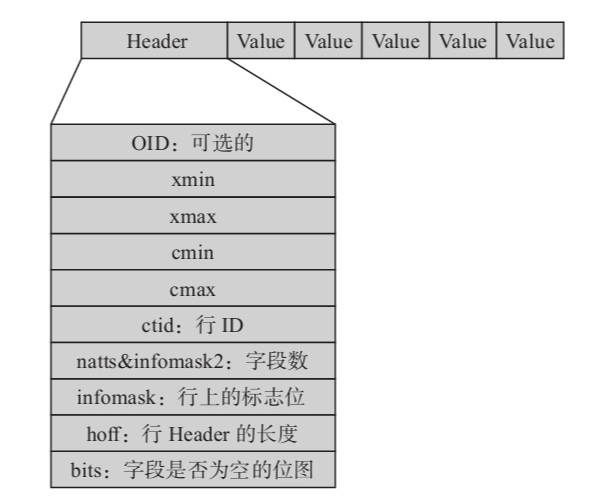
在PostgreSQL数据库中,Tuple是指数据行。行的结构如图10-2所示。
从图中可以看出,行的物理结构是先有一个行头,后面跟了各项数据。行头中记录了以下重要信息。
·oid、ctid、xmin、xmax、cmin、cmax、ctid:这些信息的含义在前面已介绍过。
·natts&infomask2:字段数,其中低11位表示这行有多少个列。其他的位则是HOT(Heap Only Touples)技术及行可见性的标志位。
·infomask:用于标识行当前的状态,比如行是否具有OID,是否有空属性,共有16位,每位都代表不同的含义。
·hoff:表示行头的长度。
·bits:是一个数组,用于标识该行上哪些字段(列)为空。
行上的xmin、xmax、cmin、cmax和CLOG日志一起用于控制行的可见性。每个事务在CLOG中占用两个bit,数据库运行一段时间后,如几年,就可能产生上亿个事务,最多时甚至可能达到20亿个事务,它们使用的CLOG可能占用512MB的空间,在这么大的CLOG中查询事务的状态,效率可能不高,于是PostgreSQL对查询行的可见性做了优化,把一些可见性的信息记录在infomask字段上,该字段的t_infomask中有以下与可见性相关的标志位:
·#define HEAP_XMIN_COMMITTED 0x0100 /* t_xmin committed */。
·#define HEAP_XMIN_INVALID 0x0200 /* t_xmin invalid/aborted */。
·#define HEAP_XMAX_COMMITTED 0x0400 /* t_xmax committed */。
·#define HEAP_XMAX_INVALID 0x0800 /* t_xmax invalid/aborted */。
·#define HEAP_XMAX_IS_MULTI 0x1000 /* t_xmax is a MultiXactId */。
如果t_infomask中HEAP_XMIN_COMMITTED为真,而HEAP_XMAX_INVALID为假,则说明该行是新插入的行,是可见的,此时就不需要到CLOG中查询xmin和xmax的事务状态了。
而如果未设置HEAP_XMIN_COMMITTED,并不表示该行没有提交,而是说不知道xmin是否提交了,需要到CLOG中去判断xmin的状态。HEAP_XMAX_COMMITTED也是如此。
第一次插入数据时,t_infomask中的HEAP_XMIN_COMMITTED和HEAP_XMAX_INVALID并未设置,但当事务提交后,有用户再读取这个数据块时会通过CLOG判断出这些行的事务已提交,会设置t_infomask中的HEAP_XMIN_COMMITTED和HEAP_XMAX_INVALID标志位。下次再查询该行时,直接使用t_infomask中的HEAP_XMIN_COMMITTED和HEAP_XMAX_INVALID标志位就可以判断出行的可见性了,不再需要到CLOG中查询事务的状态。
数据块空闲空间管理
在表中的数据块中插入、更新和删除数据会在表中产生旧版本的数据,这些旧版本数据通过Vacuum进程的清理会在数据块中产生空闲空间。再向表中插入数据时,最好的办法就是继续使用这些旧数据块中的空闲空间,如果所有的新数据都分配新的数据块,会导致数据文件不断膨胀。当插入新行时,如果多个数据块中都有空闲空间,应把数据行插到哪个有空闲空间的数据块中呢?首先,有空闲空间的数据块不一定能容纳下新的数据行,所以要插入一行数据时,首先要快速找到一个数据块,且此数据块中的空闲空间能够放下此数据行。
要完成这一操作,要实现以下两个功能:
·首先是要记录每个数据块空闲空间的大小。
·查找时,不能一个一个地找,要实现快速查找。
PostgreSQL数据库使用一个名为“FSM”的文件记录每个数据块的空闲空间。FSM是英文“Free Space Map”的缩写。
PostgreSQL为缩小FSM文件的大小,只使用一个字节来记录一个数据块中的空闲空间,很明显一个字节是无法记录空闲空间实际大小的,该字节值实际上代表空闲空间的一个范围

如果该字节值为“0”,则表示数据块中存在的空闲空间大小的范围为0~31字节;如果为“1”,则表示空闲空间大小的范围为32~63字节,然后以此类推。
在PostgreSQL 8.4之前的版本中,使用一个全局的FSM文件来记录所有表文件的空闲空间,但这会导致管理的复杂和低效,所以从PostgreSQL 8.4版本之后,对每个数据文件创建一个名为“<表oid>_fsm”的文件,如假设一个表“test01”的OID为“25566”,则它的FSM文件名为“25566_fsm”。
为了快速查找到满足要求的数据块,PostgreSQL使用了树型结构组织FSM文件。FSM文件固定使用3层树型结构,第0层和第1层为查找辅助层,第2层中每个块的每个字节代表其对应的数据块中的空闲空间。在第1层中,每个块中的字节值代表其下一层(第2层)相应的数据块中的最大值。假设第2层的每个数据块可以填4000个字节,则这4000个字节对应着在真正的数据文件中的4000个数据块各有多少空闲空间,而第1层中的这个字节,则表示第2层中对应数据块中的最大值,也就是指对应到真正的数据文件中这4000个数据块最大的空闲空间,同时第0层中的每个字节表示的是下一层中数据块中的最大值。第0层只有一个数据块,当需要判断数据块的空闲空间是否足够大时,只需要查询第0层的这个数据块就可确定是否有合适大小的空闲空间的数据块了。
FSM文件并不是在创建表文件时立即创建的,而是等到需要时才会创建,也就是执行VACUUM操作时,或者在为了插入行第一次查询FSM文件时才创建。下面通过示例来验证这个过程,先建一张表
create table test01(id int, note text);
CREATE TABLE
osdba=# insert into test01 values(1,'11111');
INSERT 0 1
osdba=# select oid from pg_class where relname='test01';
oid
-------
25827
(1 row)
然后到数据目录下查看FSM文件,命令如下:
osdba@osdba-laptop:~/pgdata/base/16384$ ls -l 25827*
-rw------- 1 osdba osdba 8192 5月 17 22:43 25827
从上面的运行结果中可以看到并没有生成FSM文件,再做一个VACUUM操作,命令如下:
osdba=# vacuum test01;
VACUUM
然后再到目录下查询FSM文件,命令如下:
osdba@osdba-laptop:~/pgdata/base/16384$ ls -l 25827*
-rw------- 1 osdba osdba 8192 5月 17 22:43 25827
-rw------- 1 osdba osdba 24576 5月 17 22:44 25827_fsm
-rw------- 1 osdba osdba 8192 5月 17 22:44 25827_vm
可见性映射表文件
在PostgreSQL中更新、删除行后,数据行并不会马上从数据块中被清理掉,而是需要等VACUUM时清理。为了能加快VACUUM清理的速度并降低对系统I/O性能的影响,PostgreSQL在8.4.1版本之后为每个数据文件加了一个后缀为“_vm”的文件,此文件被称为可见性映射表文件,简称VM文件。VM文件中为每个数据块存储了一个标志位,用来标记数据块中是否存在需要清理的行。有该文件后,做VACUUM扫描此文件时,如果发现VM文件中该数据块上的位表示该数据块没有需要清理的行,VACUUM就可以跳过对这个数据块的扫描,从而加快VACUUM清理的速度。
VACUUM有两种方式,一种被称为“Lazy VACUUM”,另一种被称为“Full VACUUM”,VM文件仅在Lazy VACUUM中使用,Full VACUUM操作则需要对整个数据文件进行扫描。










