1.慢查询的优化思路
1.1优化更需要优化的SQL
优化SQL是有成本的
高并发低消耗的比低并发高消耗影响更大
优化示例
| 并发形式 | 优化前 | 假设优化后 |
|---|---|---|
| 高并发低消耗 | 每小时10000次,每次20个IO | 每小时节约20000次IO,sql要优化后到18个IO |
| 低并发高消耗 | 每小时10次,每次20000个IO | 每小时节约20000次IO,sql要优化到18000个IO |
显然 前者更容器容易优化
1.2定位优化对象的性能瓶颈
1.3明确的优化目标
1.4 慢查询的优化思路
- 从explain执行计划入手
- 永远用小结果集驱动大的结果集
- 尽可能在索引中完成排序
- 只取出自己需要的列,不要用select *
- 仅使用最有效的过滤条件
- 尽可能避免复杂的join和子查询
- 小心使用order by,group by,distinct 语句
2. join优化
永远用小结果集驱动大的结果集(join操作表小于百万级别)
驱动表的定义
join的实现原理
- mysql只支持一种join算法:
Nested-Loop Join(嵌套循环连接)
但Nested-Loop Join有三种变种: -
Simple Nested-Loop Join (简单嵌套循环)
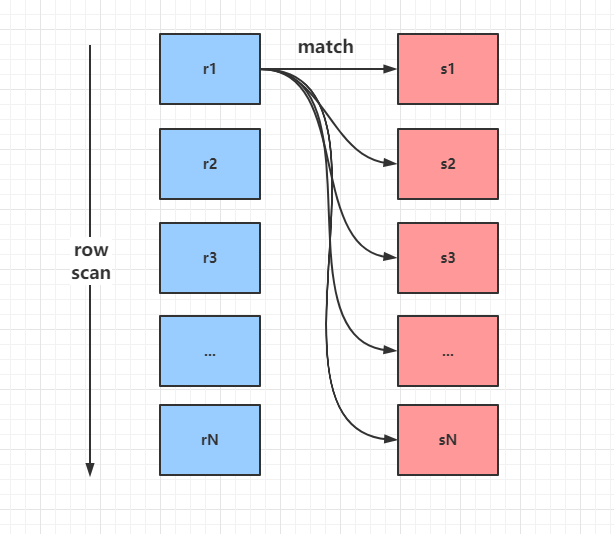
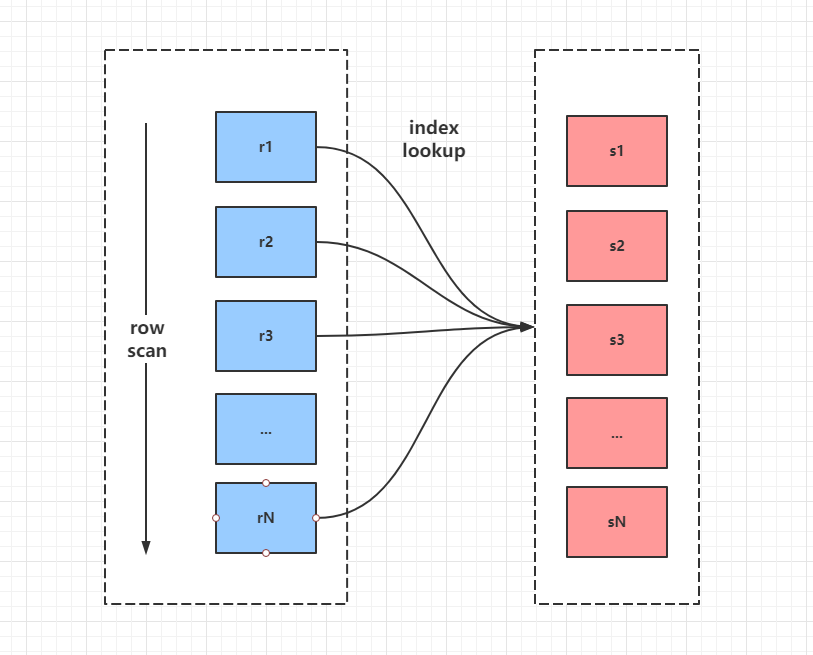
- Index Nested-Loop Join(索引嵌套循环)
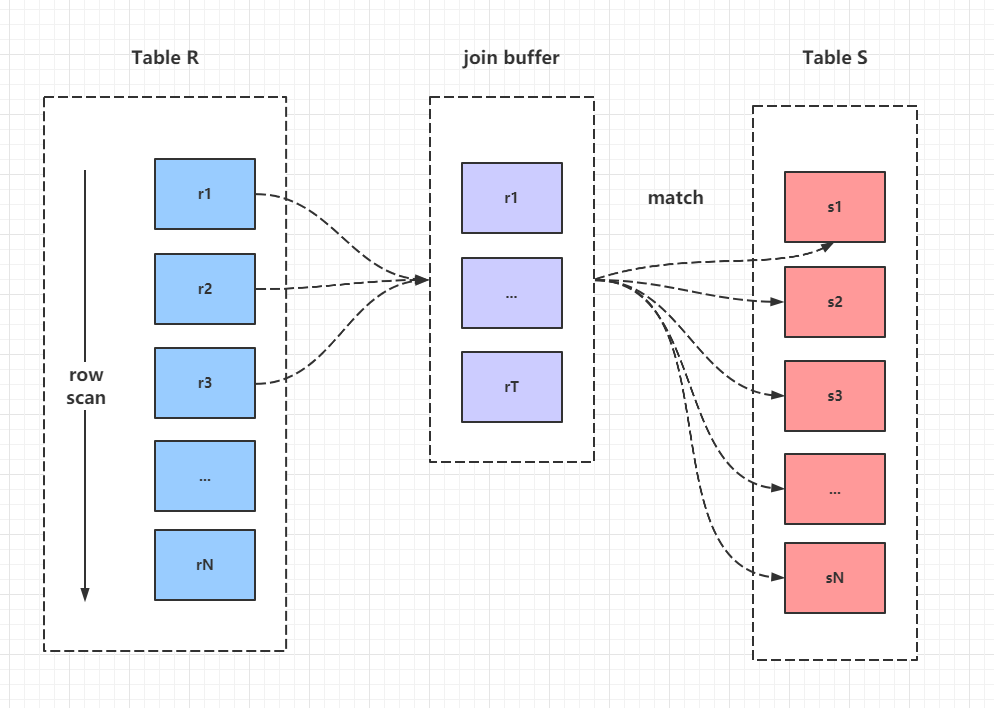
- Block Nested-Loop Join(快嵌套循环)
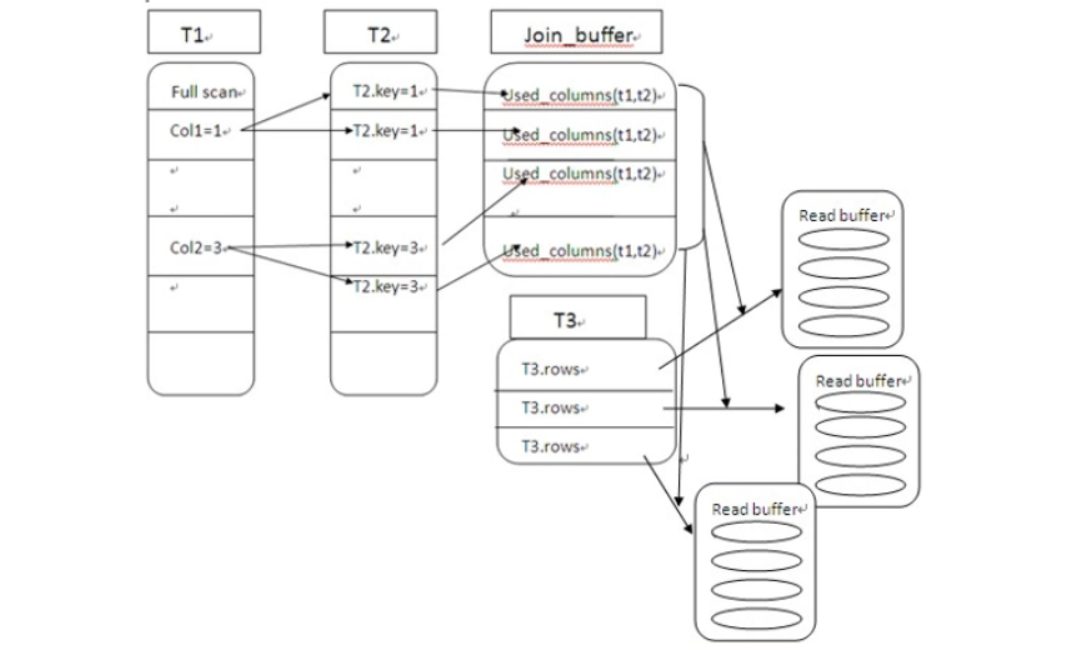
-
Block Nested-Loop Join(3表快嵌套循环)
join的优化思路
- 尽可能减少join语句中的Nested Loop的循环总次数
- 优先优化Nested Loop的内层循环
- 保证join语句中被驱动表上join条件字段已经被索引
- 无法保证被驱动表的Join条件字段被索引且内存资源充足的前提下,不要太吝惜join Buffer的设置
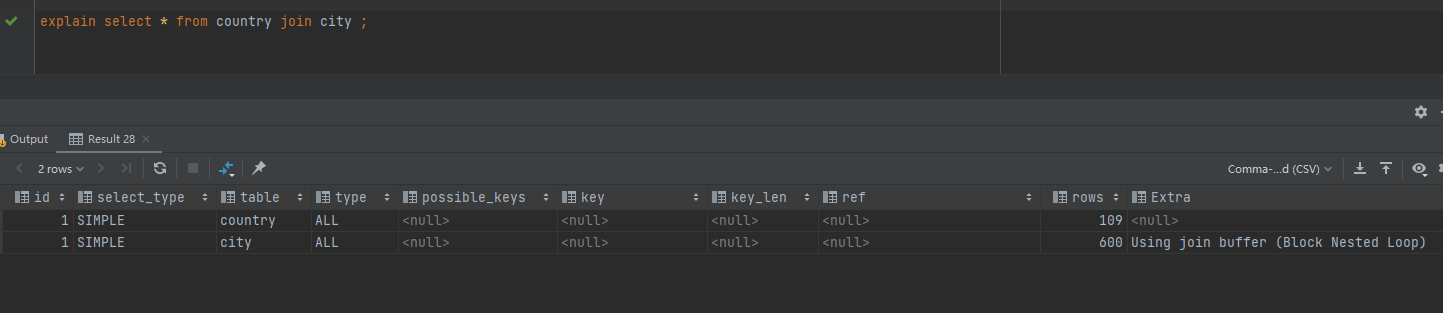
country :106条
city :600条
explain select * from country join city ;
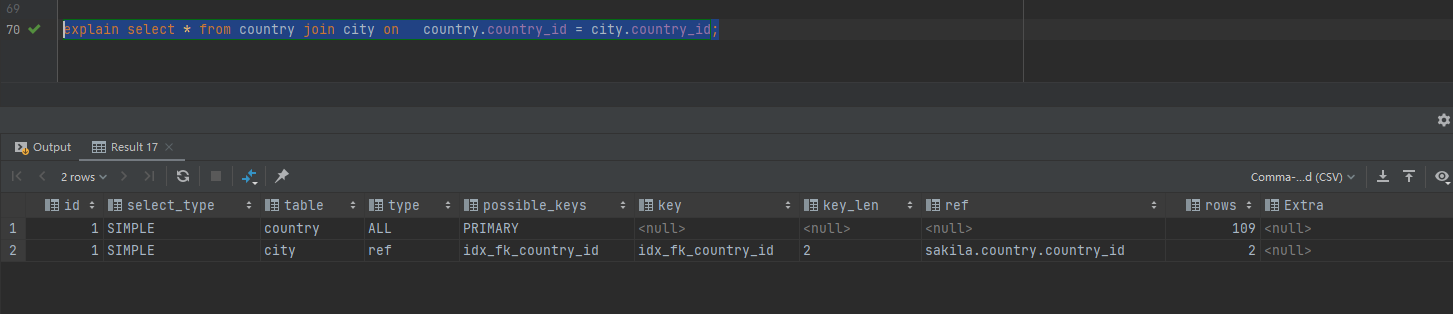
country :106条
city :600条
country_id 都为索引
explain select * from country join city on country.country_id = city.country_id;
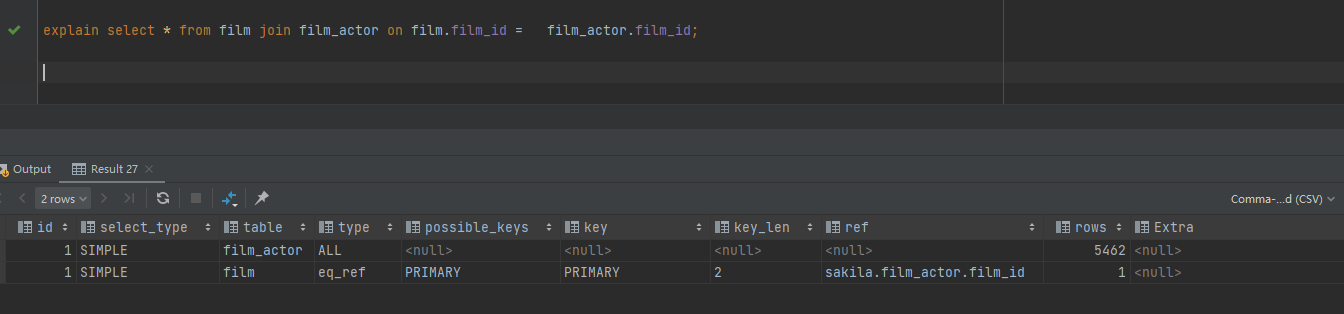
film_actor :5462条
film:1000条
film 中 film_id 为索引, film_actor 不为索引
explain select * from film join film_actor on film.film_id = film_actor.film_id;
join的优化思路总结
- 并发量太高的时候,系统整体性能可能会急剧下降
- 复杂的join语句,所需要锁定的资源也就越多,所阻塞的其他线程也就越多
- 复杂的Query语句分拆成多个较为简单的Query语句分布执行(超过3张表 不要用join,一个表一个表的查)
3.order by 排序优化
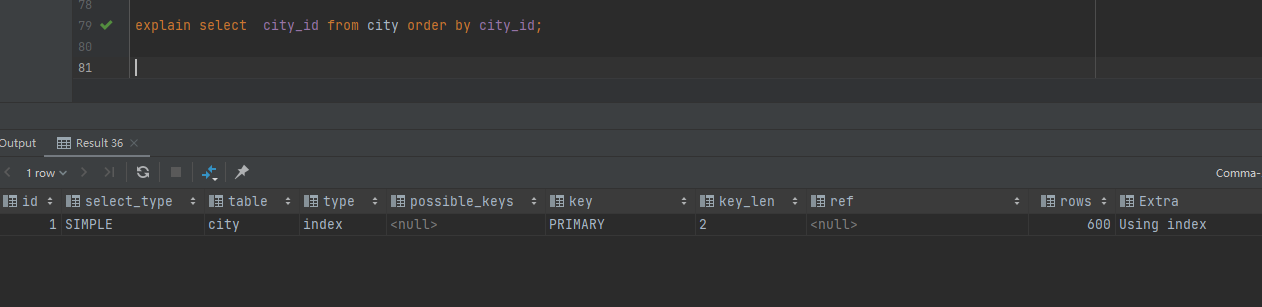
- order by 字句中的字段加索引(扫描索引即可,内存中完成,逻辑io)
explain select city_id from city order by city_id;
- 若不加锁索引的话会可能启用一个临时文件辅助排序(落盘,物理io)
- order by排序可利用索引进行优化,order by子句中只需要是索引的前导列都可以
使索引生效,可以直接在索引中排序,不需要在额外的内存或者文件中排序 - 不能利用索引避免额外排序的情况,例如:排序字段中有多个索引,排序顺序和索引键顺序不一致(非前导列)
order by排序算法
a.常规排序,双路排序
- 从表t1中获取满足WHERE条件的记录
- 对于每条记录,将记录的主键+排序键(id,col2)取出放入sort buffer
- 如果sort buffer可以存放所有满足条件的(id,col2)对,则进行排序;否则sort buffer满后,进行排序并写到临时文件中。(排序算法采用的是快速排序算法)
- 若排序中产生了临时文件,需要利用归并排序算法,保证临时文件中记录是有序的
- 循环执行上述过程,直到所有满足条件的记录全部参与排序
扫描排好序的(id,col2)队,即sort buffer,并利用主键id去取SELECT需要返回的其他列(col1,col2,col3)- 将获取的结果集返回给用户。
b.优化排序,单路排序,max_length_for_sort_data
c.优先队列排序
为了得到最终的排序结果,我们都需要将所有满足条件的记录进行排序才能返回。那么相对于优化排序方式,是否还有优化空间呢?5.6版本针对Order by limit M,N语句,在空间层面做了优化,加入了一种新的排序方式--优先队列,这种方式采用堆排序实现。堆排序算法特征正好可以解limit M,N 这类排序的问题,虽然仍然需要所有字段参与排序,但是只需要M+N个元组的sort buffer空间即可,对于M,N很小的场景,基本不会因为sort buffer不够而导致需要临时文件进行归并排序的问题。对于升序,采用大顶堆,最终堆中的元素组成了最小的N个元素,对于降序,采用小顶堆,最终堆中的元素组成了最大的N的元素。
总结:分别在查询字段、where条件、排序字段上做出各种可能的组合,主要就是看有无索引,索引在以上三个关注点上的生效情况
4.group by 分组优化
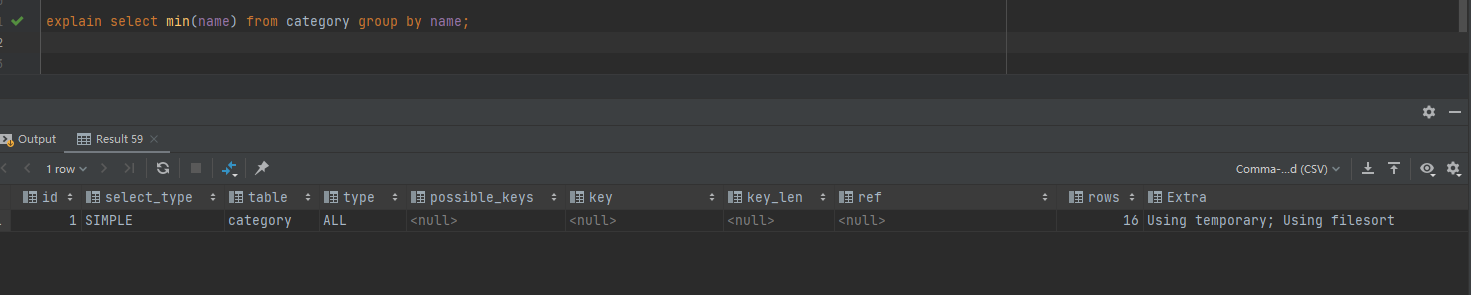
explain select min(name) from category group by name;
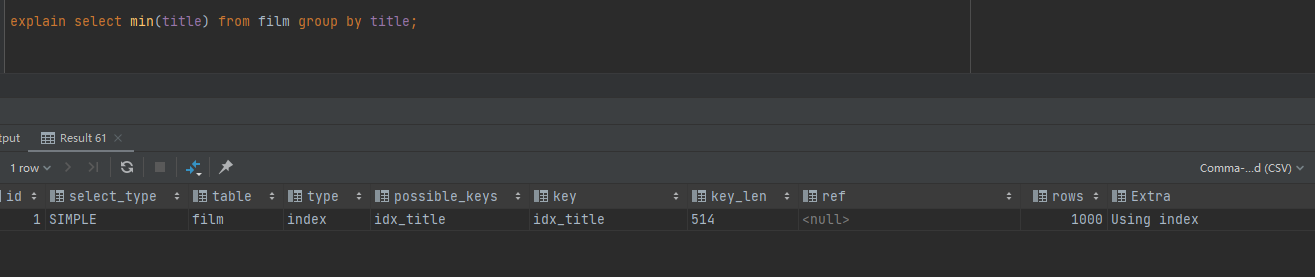
film 中的 title 加了索引
explain select min(title) from film group by title;
4.1 group by的类型
- 三种实现类型
Loose Index Scan(松散的索引扫描)
explain select actor_id, max(film_id) FROM film_actor GROUP BY actor_id;

explain select actor_id, max(film_id) FROM film_actor where film_id > 10 GROUP BY actor_id;

Tight Index Scan(紧凑的索引扫描)
Using temporary 临时表实现(非索引扫描)
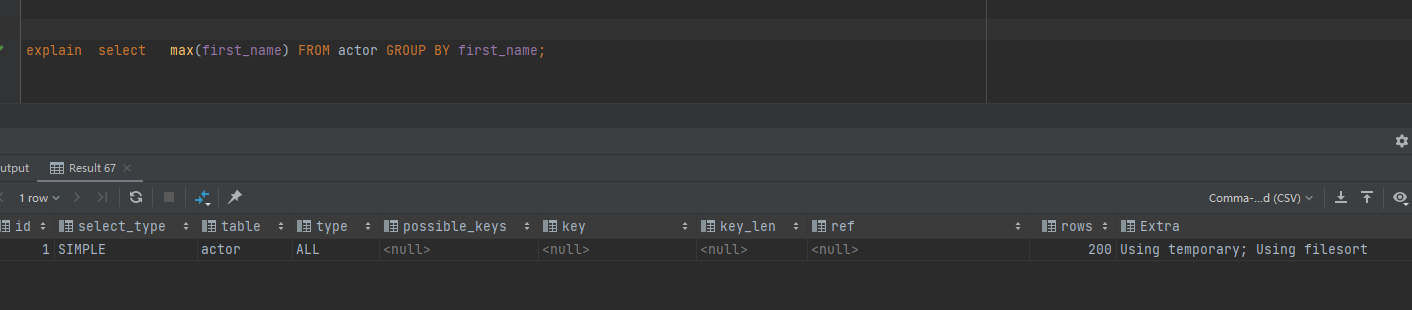
explain select max(first_name) FROM actor GROUP BY first_name;
5.distinct 分组优化
explain select distinct country_id from city;

explain select distinct country_id from city where city_id > 100;










