转自千峰王溯老师
1、用户画像项目简介
1.1 什么是用户画像
所谓的用户画像就是给用户贴一些标签,通过标签说明用户是一个什么样的人。
具体来说,给用户贴一些标签之后,根据用户的目标、行为和观点的差异,将他们区分为不同的类型,然后从每种类型中抽取典型特征,赋予名字、照片、一些人口统计学要素、场景等描述,形成了一个人物原型。
过程就是:通过客户信息抽象为用户画像进而抽象出对客户的认知。
1.2 用户画像主要维度
人口属性:用户是谁(性别、年龄、职业等基本信息)
消费需求:消费习惯和消费偏好
购买能力:收入、购买力、购买频次、渠道
兴趣爱好:品牌偏好、个人兴趣
社交属性:用户活跃场景(社交媒体等)
1.3 用户画像的数据类型
数据有动态数据和静态数据,所谓的静态数据如性别和年龄等短期无法改变的数据;而动态数据就是如短期行为相关的数据,比如说今天我想买件裙子,明天我就去看裤子了,这种数据特征就是比较多变。
1.4 用户画像的用途
杀熟、推荐(非常多)【用户画像是推荐系统的重要数据源】、市场营销、客服
让用户和企业双赢。让用户快速找到想要的商品,让企业找到为产品买单的人。
(一)微观层面
在产品设计时,通过用户画像来描述用户的需求。
在数据应用上,可以用来推荐、搜索、风控
将定性分析和定量分析结合,进行数据化运营和用户分析
进行精准化营销
(二)宏观层面
确定发展的战略、战术方向
进行市场细分与用户分群,以市场为导向
(三)画像建模预测
进行人口属性细分:明确是谁,购买了什么,为什么
购买行为细分:提供市场机会、市场规模等关键信息
产品需求细分:提供更具差异化竞争力的产品规格和业务价值
兴趣态度细分:提供人群类别画像:渠道策略,定价策略,产品策略,品牌策略
1.5 用户画像的步骤
(一)确定画像的目标
在产品不同生命周期,或者不同使用途径,目标不同,对画像的需求也有所不同,所以进行画像之前需要明确目标是什么,需求是什么。
(二)确定所需用户画像的维度
根据目标确定用户画像所需要的维度,比如说想进行商品推荐,就需要能影响用户选择商品的因素作为画像维度。比如用户维度(用户的年龄、性别会影响用户的选择),资产维度(用户的收入等因素会影响用户对价格选择),行为维度(用户最近常看的应该是想买的)等等。
(三)确定画像的层级
用户画像层级越多,说明画像粒度越小,对用户的理解也越清晰。比如说用户维度,可以分为新用户和老用户,进而划分用户的性别、年龄等。这个需要根据目标需求进行划分。
(四)通过原始数据,采用机器学习算法为用户贴上标签
因为我们获得的原始数据是一些杂乱无章的数据,所以就需要算法通过某些特征为用户贴上标签
(五)通过机器学习算法将标签变为业务的输出
每个人会有很多很多的标签,需要进一步将这些标签转化为对用户的理解。需要对不同的标签建不同的权重,从而得出对业务的输出。比如说具有一些标签的用户会喜欢什么样的产品。
(六)业务产生数据,数据反哺业务,不断循环的闭环
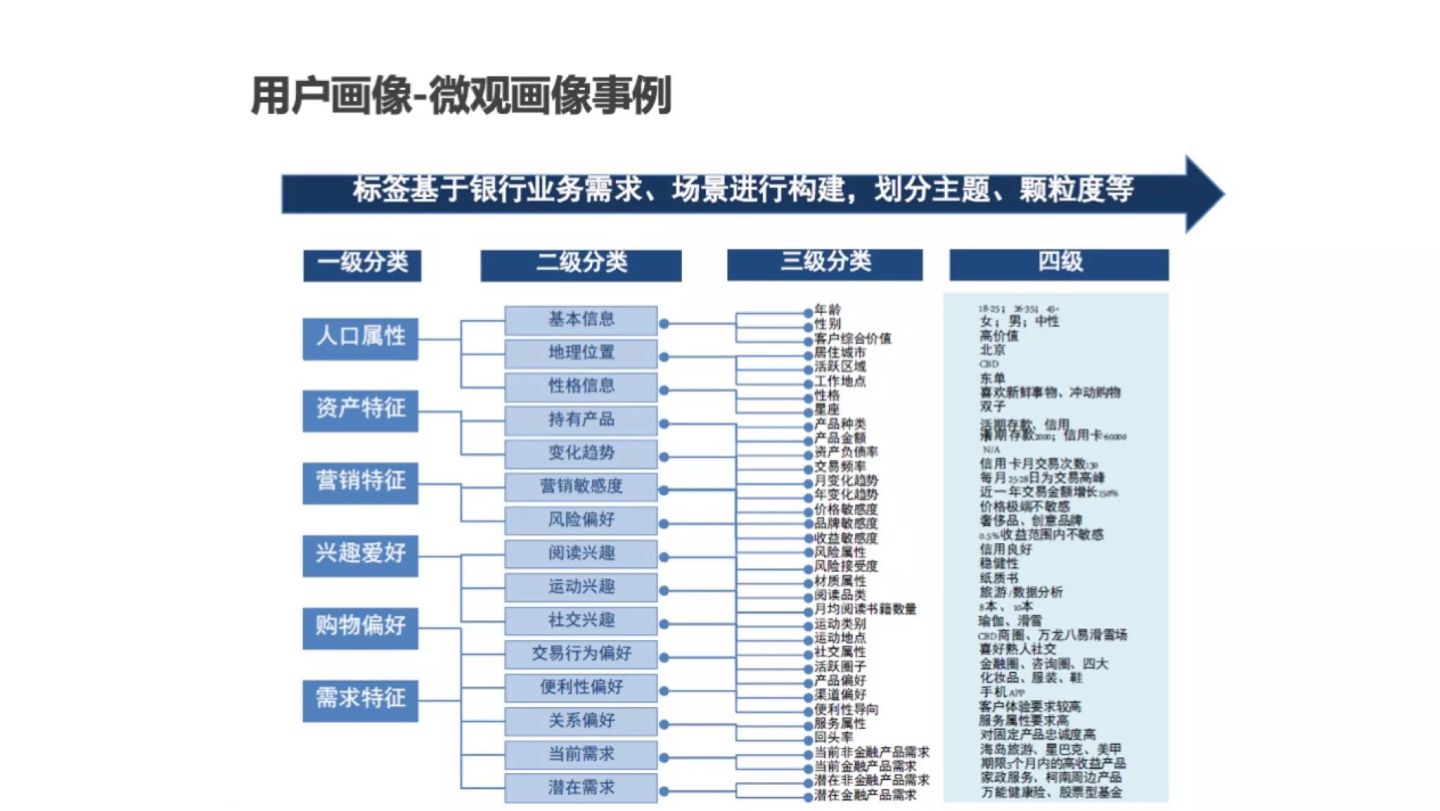
1.6 常见的用户画像标签

2、系统架构
2.1 整体架构(线下项目)

2.2 数据处理流程(要做什么事)

ETL(Extract Tranform Load)用来描述数据从来源端,经过 抽取、转换、加载 到目的端的过程;
ODS(Operational Data Store)操作数据存储。此层数据无任何更改,直接沿用外围系统数据结构和数据,不对外开放;为临时存储层,是接口数据的临时存储区域,为后一步的数据处理做准备。
要实现的主要步骤:ETL、报表统计(数据分析)、生成商圈库、数据标签化(核心)
2.3 主要数据集(要分析的日志数据文件)说明
- 为整合后的日志数据,每天一份,json格式(离线处理)
- 这个数据集整合了内部、外部的数据,以及竞价信息(与广告相关)
- 数据的列非常多,接近百个
| 字段 | 解释 |
|---|---|
| ip | 设备的真实IP |
| sessionid | 会话标识 |
| advertisersid | 广告主ID |
| adorderid | 广告ID |
| adcreativeid | 广告创意ID( >= 200000 : dsp , < 200000 oss) |
| adplatformproviderid | 广告平台商ID(>= 100000: rtb , < 100000 : api ) |
| sdkversionnumber | SDK版本号 |
| adplatformkey | 平台商key |
| putinmodeltype | 针对广告主的投放模式,1:展示量投放 2:点击量投放 |
| requestmode | 数据请求方式(1:请求、2:展示、3:点击) |
| adprice | 广告价格 |
| adppprice | 平台商价格 |
| requestdate | 请求时间,格式为:yyyy-m-dd hh:mm:ss |
| appid | 应用id |
| appname | 应用名称 |
| uuid | 设备唯一标识,比如imei或者androidid等 |
| device | 设备型号,如htc、iphone |
| client | 设备类型 (1:android 2:ios 3:wp) |
| osversion | 设备操作系统版本,如4.0 |
| density | 备屏幕的密度 android的取值为0.75、1、1.5,ios的取值为:1、2 |
| pw | 设备屏幕宽度 |
| ph | 设备屏幕高度 |
| provincename | 设备所在省份名称 |
| cityname | 设备所在城市名称 |
| ispid | 运营商id |
| ispname | 运营商名称 |
| networkmannerid | 联网方式id |
| networkmannername | 联网方式名称 |
| iseffective | 有效标识(有效指可以正常计费的)(0:无效 1:有效) |
| isbilling | 是否收费(0:未收费 1:已收费) |
| adspacetype | 广告位类型(1:banner 2:插屏 3:全屏) |
| adspacetypename | 广告位类型名称(banner、插屏、全屏) |
| devicetype | 设备类型(1:手机 2:平板) |
| processnode | 流程节点(1:请求量kpi 2:有效请求 3:广告请求) |
| apptype | 应用类型id |
| district | 设备所在县名称 |
| paymode | 针对平台商的支付模式,1:展示量投放(CPM) 2:点击量投放(CPC) |
| isbid | 是否rtb |
| bidprice | rtb竞价价格 |
| winprice | rtb竞价成功价格 |
| iswin | 是否竞价成功 |
| cur | values:usd|rmb等 |
| rate | 汇率 |
| cnywinprice | rtb竞价成功转换成人民币的价格 |
| imei | 手机串码 |
| mac | 手机MAC码 |
| idfa | 手机APP的广告码 |
| openudid | 苹果设备的识别码 |
| androidid | 安卓设备的识别码 |
| rtbprovince | rtb 省 |
| rtbcity | rtb 市 |
| rtbdistrict | rtb 区 |
| rtbstreet | rtb 街道 |
| storeurl | app的市场下载地址 |
| realip | 真实ip |
| isqualityapp | 优选标识 |
| bidfloor | 底价 |
| aw | 广告位的宽 |
| ah | 广告位的高 |
| imeimd5 | imei_md5 |
| macmd5 | mac_md5 |
| idfamd5 | idfa_md5 |
| openudidmd5 | openudid_md5 |
| androididmd5 | androidid_md5 |
| imeisha1 | imei_sha1 |
| macsha1 | mac_sha1 |
| idfasha1 | idfa_sha1 |
| openudidsha1 | openudid_sha1 |
| androididsha1 | androidid_sha1 |
| uuidunknow | uuid_unknow UUID密文 |
| userid | 平台用户id |
| iptype | 表示ip库类型,1为点媒ip库,2为广告协会的ip地理信息标准库,默认为1 |
| initbidprice | 初始出价 |
| adpayment | 转换后的广告消费(保留小数点后6位) |
| agentrate | 代理商利润率 |
| lomarkrate | 代理利润率 |
| adxrate | 媒介利润率 |
| title | 标题 |
| keywords | 关键字 |
| tagid | 广告位标识(当视频流量时值为视频ID号) |
| callbackdate | 回调时间 格式为:YYYY/mm/dd hh:mm:ss |
| channelid | 频道ID |
| mediatype | 媒体类型 |
| 用户email | |
| tel | 用户电话号码 |
| sex | 用户性别 |
| age | 用户年龄 |
3、创建工程【第二天重点】
3.1 步骤
-
新建一个Maven项目,用于处理数据
Maven 管理项目中用到的所有jar
-
修改 pom.xml 文件,增加:
- 定义依赖版本
- 导入依赖
- 定义配置文件
创建scala目录(src、test中分别创建)
在scala目录中创建包 cn.itbigdata.dmp
编写一个主程序的架构 (DMPApp)
增加配置文件 dev/application.conf
新增目录 utils,新增参数解析类 ConfigHolder
3.2 修改pom.xml文件【重点】
-
设置依赖版本信息
<properties> <scala.version>2.11.8</scala.version> <scala.version.simple>2.11</scala.version.simple> <hadoop.version>2.6.1</hadoop.version> <spark.version>2.3.3</spark.version> <hive.version>1.1.0</hive.version> <fastjson.version>1.2.44</fastjson.version> <geoip.version>1.3.0</geoip.version> <geoip2.version>2.12.0</geoip2.version> <config.version>1.2.1</config.version> </properties> -
导入计算引擎的依赖
<!-- scala --> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-xml</artifactId> <version>2.11.0-M4</version> </dependency> <!-- hadoop --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <!-- spark core --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.version.simple}</artifactId> <version>${spark.version}</version> </dependency> <!-- spark sql --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_${scala.version.simple}</artifactId> <version>${spark.version}</version> </dependency> <!-- spark graphx --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-graphx_${scala.version.simple}</artifactId> <version>${spark.version}</version> </dependency> -
<font color=red>导入存储引擎的依赖(可省略)</font>
<dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-jdbc</artifactId> <exclusions> <exclusion> <groupId>org.apache.hive</groupId> <artifactId>hive-service-rpc</artifactId> </exclusion> <exclusion> <groupId>org.apache.hive</groupId> <artifactId>hive-service</artifactId> </exclusion> </exclusions> <version>${hive.version}</version> </dependency> -
导入工具依赖
<!-- 用于IP地址转换(经度、维度) --> <dependency> <groupId>com.maxmind.geoip</groupId> <artifactId>geoip-api</artifactId> <version>${geoip.version}</version> </dependency> <dependency> <groupId>com.maxmind.geoip2</groupId> <artifactId>geoip2</artifactId> <version>${geoip2.version}</version> </dependency> <!-- 将经纬度转换为编码 --> <dependency> <groupId>ch.hsr</groupId> <artifactId>geohash</artifactId> <version>${geoip.version}</version> </dependency> <!-- scala解析json --> <dependency> <groupId>org.json4s</groupId> <artifactId>json4s-jackson_${scala.version.simple}</artifactId> <version>3.6.5</version> </dependency> <!-- 管理配置文件 --> <dependency> <groupId>com.typesafe</groupId> <artifactId>config</artifactId> <version>${config.version}</version> </dependency>
-
<font color=red>导入编译配置(可省略)</font>
<build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> <plugin> <artifactId>maven-assembly-plugin</artifactId> <executions> <execution> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> <configuration> <archive> <manifest> <addClasspath>true</addClasspath> <mainClass>cn.itcast.dmp.processing.App</mainClass> </manifest> </archive> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> </plugin> </plugins> </build>
3.3 创建scala代码包
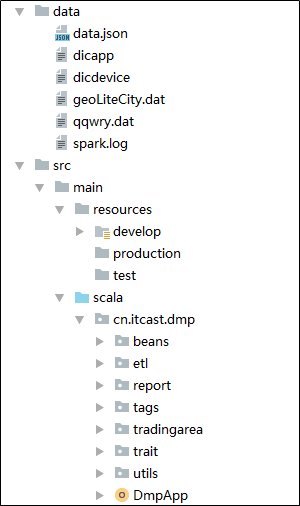
在 src/main/ 下 创建scala代码包
在scala包中创建 cn.itbigdata.dmp 包
-
在 cn.itbigdata.dmp 包下创建
- beans(存放类的定义)
- etl(etl相关处理)
- report(报表处理)
- tradingarea(商圈库)
- tags(标签处理)
- customtrait(存放接口定义)
- utils(存放工具类)
在整个工程中建立data目录,存放要处理的数据
3.4 DmpApp 主程序(初始化部分)
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
// 项目的主程序,在这里完成相关的任务
object DmpApp {
def main(args: Array[String]): Unit = {
// 初始化
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("DmpApp")
.set("spark.worker.timeout", "600s")
.set("spark.cores.max", "10")
.set("spark.rpc.askTimeout", "600s")
.set("spark.network.timeout", "600s")
.set("spark.task.maxFailures", "5")
.set("spark.speculation", "true")
.set("spark.driver.allowMultipleContexts", "true")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.set("spark.buffer.pageSize", "8m")
.set("park.debug.maxToStringFields", "200")
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
// 关闭资源
spark.close()
}
}
3.5 spark相关参数解释
| 参数名 | 默认值 | 定义值 |
|---|---|---|
| spark.worker.timeout | 60 | 500 |
| spark.network.timeout | 120s | 600s |
| spark.rpc.askTimeout | spark.network.timeout | 600s |
| spark.cores.max | 10 | |
| spark.task.maxFailures | 4 | 5 |
| spark.speculation | false | true |
| spark.driver.allowMultipleContexts | false | true |
| spark.serializer | org.apache.spark.serializer.JavaSerializer | org.apache.spark.serializer.KryoSerializer |
| spark.buffer.pageSize | 1M - 64M,系统计算 | 8M |
- spark.worker.timeout: 网络故障导致心跳长时间不上报给master,经过spark.worker.timeout(秒)时间后,master检测到worker异常,标识为DEAD状态,同时移除掉worker信息以及其上面的executor信息;
- spark.network.timeout:所有网络交互的默认超时。由网络或者 gc 引起,worker或executor没有接收到executor或task的心跳反馈。提高 spark.network.timeout 的值,根据情况改成300(5min)或更高;
- spark.rpc.askTimeout: rpc 调用的超时时间;
- spark.cores.max:每个应用程序所能申请的最大CPU核数;
- spark.task.maxFailures:当task执行失败时,并不会直接导致整个应用程序down掉,只有在重试了 spark.task.maxFailures 次后任然失败的情况下才会使程序down掉;
- spark.speculation:推测执行是指对于一个Stage里面运行慢的Task,会在其他节点的Executor上再次启动这个task,如果其中一个Task实例运行成功则将这个最先完成的Task的计算结果作为最终结果,同时会干掉其他Executor上运行的实例,从而加快运行速度;
- spark.driver.allowMultipleContexts: SparkContext默认只有一个实例,设置为true允许有多个实例;
- spark.serializer:在Spark的架构中,在网络中传递的或者缓存在内存、硬盘中的对象需要进行序列化操作【发给Executor上的Task;需要缓存的RDD(前提是使用序列化方式缓存);广播变量;shuffle过程中的数据缓存等】;默认的Java序列化方式性能不高,同时序列化后占用的字节数也较多;官方也推荐使用Kryo的序列化库。官方文档介绍,Kryo序列化机制比Java序列化机制性能提高10倍左右;
- spark.buffer.pageSize: spark内存分配的单位,无默认值,大小在1M-64M之间,spark根据jvm堆内存大小计算得到;值过小,内存分配效率低;值过大,造成内存的浪费;
3.6 开发环境参数配置文件
application.conf
// 开发环境参数配置文件
# App 信息
spark.appname="dmpApp"
# spark 信息
spark.master="local[*]"
spark.worker.timeout="120"
spark.cores.max="10"
spark.rpc.askTimeout="600s"
spark.network.timeout="600s"
spark.task.maxFailures="5"
spark.speculation="true"
spark.driver.allowMultipleContexts="true"
spark.serializer="org.apache.spark.serializer.KryoSerializer"
spark.buffer.pageSize="8m"
# kudu 信息
kudu.master="node1:7051,node2:7051,node3:7051"
# 输入数据的信息
addata.path="data/dataset_main.json"
ipdata.geo.path="data/dataset_geoLiteCity.dat"
qqwrydat.path="data/dataset_qqwry.dat"
installDir.path="data"
# 对应ETL输出信息
ods.prefix="ods"
ad.data.tablename="adinfo"
# 输出报表对应:地域统计、广告地域、APP、设备、网络、运营商、渠道 7个分析
report.region.stat.tablename="RegionStatAnalysis"
report.region.tablename="AdRegionAnalysis"
report.app.tablename="AppAnalysis"
report.device.tablename="DeviceAnalysis"
report.network.tablename="NetworkAnalysis"
report.isp.tablename="IspAnalysis"
report.channel.tablename="ChannelAnalysis"
# 高德API
gaoDe.app.key="a94274923065a14222172c9b933f4a4e"
gaoDe.url="https://restapi.amap.com/v3/geocode/regeo?"
# GeoHash (key的长度)
geohash.key.length=10
# 商圈库
trading.area.tablename="tradingArea"
# tags
non.empty.field="imei,mac,idfa,openudid,androidid,imeimd5,macmd5,idfamd5,openudidmd5,androididmd5,imeisha1,macsha1,idfasha1,openudidsha1,androididsha1"
appname.dic.path="data/dic_app"
device.dic.path="data/dic_device"
tags.table.name.prefix="tags"
# 标签衰减系数
tag.coeff="0.92"
# es 相关参数
es.cluster.name="cluster_es"
es.index.auto.create="true"
es.Nodes="192.168.40.164"
es.port="9200"
es.index.reads.missing.as.empty="true"
es.nodes.discovery="false"
es.nodes.wan.only="true"
es.http.timeout="2000000"
3.7 配置文件解析类
// 解析参数文件帮助类
import com.typesafe.config.ConfigFactory
object ConfigHolder {
private val config = ConfigFactory.load()
// App Info
lazy val sparkAppName: String = config.getString("spark.appname")
// Spark parameters
lazy val sparkMaster: String = config.getString("spark.master")
lazy val sparkParameters: List[(String, String)] = List(
("spark.worker.timeout", config.getString("spark.worker.timeout")),
("spark.cores.max", config.getString("spark.cores.max")),
("spark.rpc.askTimeout", config.getString("spark.rpc.askTimeout")),
("spark.network.timeout", config.getString("spark.network.timeout")),
("spark.task.maxFailures", config.getString("spark.task.maxFailures")),
("spark.speculation", config.getString("spark.speculation")),
("spark.driver.allowMultipleContexts", config.getString("spark.driver.allowMultipleContexts")),
("spark.serializer", config.getString("spark.serializer")),
("spark.buffer.pageSize", config.getString("spark.buffer.pageSize"))
)
// kudu parameters
lazy val kuduMaster: String = config.getString("kudu.master")
// input dataset
lazy val adDataPath: String = config.getString("addata.path")
lazy val ipsDataPath: String = config.getString("ipdata.geo.path")
def ipToRegionFilePath: String = config.getString("qqwrydat.path")
def installDir: String = config.getString("installDir.path")
// output dataset
private lazy val delimiter = "_"
private lazy val odsPrefix: String = config.getString("ods.prefix")
private lazy val adInfoTableName: String = config.getString("ad.data.tablename")
// lazy val ADMainTableName = s"$odsPrefix$delimiter$adInfoTableName$delimiter${DateUtils.getTodayDate()}"
// report
lazy val Report1RegionStatTableName: String = config.getString("report.region.stat.tablename")
lazy val ReportRegionTableName: String = config.getString("report.region.tablename")
lazy val ReportAppTableName: String = config.getString("report.app.tablename")
lazy val ReportDeviceTableName: String = config.getString("report.device.tablename")
lazy val ReportNetworkTableName: String = config.getString("report.network.tablename")
lazy val ReportIspTableName: String = config.getString("report.isp.tablename")
lazy val ReportChannelTableName: String = config.getString("report.channel.tablename")
// GaoDe API
private lazy val gaoDeKey: String = config.getString("gaoDe.app.key")
private lazy val gaoDeTempUrl: String = config.getString("gaoDe.url")
lazy val gaoDeUrl: String = s"$gaoDeTempUrl&key=$gaoDeKey"
// GeoHash
lazy val keyLength: Int = config.getInt("geohash.key.length")
// 商圈库
lazy val tradingAreaTableName: String =config.getString("trading.area.tablename")
// tags
lazy val idFields: String = config.getString("non.empty.field")
lazy val filterSQL: String = idFields
.split(",")
.map(field => s"$field is not null ")
.mkString(" or ")
lazy val appNameDic: String = config.getString("appname.dic.path")
lazy val deviceDic: String = config.getString("device.dic.path")
lazy val tagsTableNamePrefix: String = config.getString("tags.table.name.prefix") + delimiter
lazy val tagCoeff: Double = config.getDouble("tag.coeff")
// 加载 elasticsearch 相关参数
lazy val ESSparkParameters = List(
("cluster.name", config.getString("es.cluster.name")),
("es.index.auto.create", config.getString("es.index.auto.create")),
("es.nodes", config.getString("es.Nodes")),
("es.port", config.getString("es.port")),
("es.index.reads.missing.as.empty", config.getString("es.index.reads.missing.as.empty")),
("es.nodes.discovery", config.getString("es.nodes.discovery")),
("es.nodes.wan.only", config.getString("es.nodes.wan.only")),
("es.http.timeout", config.getString("es.http.timeout"))
)
def main(args: Array[String]): Unit = {
println(ConfigHolder.sparkParameters)
println(ConfigHolder.installDir)
}
}
3.8 DmpApp主程序(使用配置文件)
import cn.itbigdata.dmp.utils.ConfigHolder
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object DmpApp {
def main(args: Array[String]): Unit = {
// 1、初始化(SparkConf、SparkSession)
val conf = new SparkConf()
.setAppName(ConfigHolder.sparkAppName)
.setMaster(ConfigHolder.sparkMaster)
.setAll(ConfigHolder.sparkParameters)
val spark: SparkSession = SparkSession.builder()
.config(conf)
.getOrCreate()
spark.sparkContext.setLogLevel("warn")
println("OK!")
// 1、ETL
// 2、报表
// 3、生成商圈库
// 4、标签化
// 关闭资源
spark.close()
}
}
4、ETL开发
需求:
-
将数据文件每一行中的 ip 地址,转换为经度、维度、省、市的信息;
ip => 经度、维度、省、市
保存转换后的数据文件(每天一个文件)
处理步骤:
- 读数据
- 数据处理
- 找出每一行数据中的ip地址
- 根据ip地址,算出对应的省、市、经度、纬度,添加到每行数据的尾部
- 保存数据
- 其他需求:数据每日加载一次,每天的数据单独存放在一个文件中
难点问题:处理数据(IP地址如何转化为省、市、经度、纬度)
4.1 搭建ETL架构
新建trait(Processor),为数据处理提供一个统一的接口类
import org.apache.spark.sql.SparkSession
// 数据处理接口
// SparkSession 用于数据的加载和处理
// KuduContext 用于数据的保存
trait Processor {
def process(spark: SparkSession)
}
新建 ETLProcessor ,负责ETL处理
import cn.itbigdata.dmp.customtrait.Processor
import org.apache.kudu.spark.kudu.KuduContext
import org.apache.spark.sql.SparkSession
object ETLProcessor extends Processor{
override def process(spark: SparkSession): Unit = {
// 定义参数
val sourceDataFile = ConfigHolder.adLogPath
val sinkDataPath = ""
// 1 读数据
val sourceDF: DataFrame = spark.read.json(sourceDataFile)
// 2 处理数据
// 2.1 找到ip
// 2.2 将ip 转为 省、市、经度、维度
val rdd = sourceDF.rdd
.map(row => {
val ip: String = row.getAs[String]("ip")
ip
})
// 2.3 将省、市、经度、维度放在原数据的最后
// 3 保存数据
}
}
4.2 IP地址转换为经纬度
- 使用GeoIP,将ip地址转为经纬度
- GeoIP,是一套含IP数据库的软件工具
- Geo根据来访者的IP, 定位该IP所在经纬度、国家/地区、省市、和街道等位置信息
- GeoIP有两个版本,一个免费版,一个收费版本
- 收费版本的准确率高一些,更新频率也更频繁
- 因为GeoIP读取的是本地的二进制IP数据库,所以效率很高
4.3 IP地址转换为省市
- 纯真数据库,将ip转为省、市
- 纯真数据库收集了包括中国电信、中国移动、中国联通、长城宽带、聚友宽带等 ISP 的 IP 地址数据
- 纯真数据库是二进制文件,有开源的java代码,简单的修改,调用就可以了
case class Location(ip: String, region: String, city: String, longitude: Float, latitude: Float)
private def ipToLocation(ip: String): Location ={
// 1 获取service
val service = new LookupService("data/geoLiteCity.dat")
// 2 获取Location
val longAndLatLocation = service.getLocation(ip)
// 3 获取经度、维度
val longitude = longAndLatLocation.longitude
val latitude = longAndLatLocation.latitude
// 4 利用纯真数据库获取省市
val ipService = new IPAddressUtils
val regeinLocation: IPLocation = ipService.getregion(ip)
val region = regeinLocation.getRegion
val city = regeinLocation.getCity
Location(ip, region, city, longitude, latitude)
}
需要实现帮助类:
-
计算当天日期
import java.util.{Calendar, Date} import org.apache.commons.lang.time.FastDateFormat object DateUtils { def getToday: String = { val now = new Date FastDateFormat.getInstance("yyyyMMdd").format(now) } def getYesterday: String = { val calendar: Calendar = Calendar.getInstance calendar.set(Calendar.HOUR_OF_DAY, -24) FastDateFormat.getInstance("yyyyMMdd").format(calendar.getTime()) } def main(args: Array[String]): Unit = { println(getToday) println(getYesterday) } }
4.4 ETL完整实现
import java.util.Calendar
import cn.itbigdata.dmp.customtrait.Processor
import cn.itbigdata.dmp.util.iplocation.{IPAddressUtils, IPLocation}
import com.maxmind.geoip.LookupService
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
object ETLProcessor extends Processor{
// 定义参数
private val sourceDataFile: String = "data/data.json"
private val sinkDataPath: String = s"outputdata/maindata.${getYesterday}"
private val geoFilePath: String = "data/geoLiteCity.dat"
override def process(spark: SparkSession): Unit = {
// 1 读数据
val sourceDF: DataFrame = spark.read.json("data/data.json")
// 2 处理数据
// 2.1 找到ip
// 2.2 将ip 转为 省、市、经度、维度
import spark.implicits._
val ipDF: DataFrame = sourceDF.rdd
.map { row =>
val ip = row.getAs[String]("ip")
// 将ip转换为 省、市、经度、纬度
ip2Location(ip)
}.toDF
// 2.2 ipDF 与 sourceDF 做join,给每一行增加省、市、经纬度
val sinkDF: DataFrame = sourceDF.join(ipDF, Seq("ip"), "inner")
// 3 保存数据
sinkDF.write.mode(SaveMode.Overwrite).json(sinkDataPath)
}
case class Location(ip: String, region: String, city: String, longitude: Float, latitude: Float)
private def ip2Location(ip: String): Location ={
// 1 获取service
val service = new LookupService(geoFilePath)
// 2 获取Location
val longAndLatLocation = service.getLocation(ip)
// 3 获取经度、维度
val longitude = longAndLatLocation.longitude
val latitude = longAndLatLocation.latitude
// 4 利用纯真数据库获取省市
val ipService = new IPAddressUtils
val regionLocation: IPLocation = ipService.getregion(ip)
val region = regionLocation.getRegion
val city = regionLocation.getCity
Location(ip, region, city, longitude, latitude)
}
private def getYesterday: String = {
val calendar: Calendar = Calendar.getInstance
calendar.set(Calendar.HOUR_OF_DAY, -24)
FastDateFormat.getInstance("yyyyMMdd").format(calendar.getTime())
}
}
5、报表开发(数据分析--SparkSQL)
需要处理的报表
- 统计各地域的数量分布情况(RegionStatProcessor)
- 广告投放的地域分布情况统计(RegionAnalysisProcessor)
- APP分布情况统计(AppAnalysisProcessor)
- 手机设备类型分布情况统计(DeviceAnalysisProcessor)
- 网络类型分布情况统计(NetworkAnalysisProcessor)
- 网络运营商分布情况统计(IspAnalysisProcessor)
- 渠道分布情况统计(ChannelAnalysisProcessor)
5.1 数据地域分布
- 报表处理的步骤
- 了解业务需求:根据省、市分组,求数据量的分布情况
- 源数据:为每天的日志数据,即ETL的结果数据;
- 目标数据:保存在本地文件中,每个报表对应目录;
- 编写SQL,并测试
- 代码实现
- 定义 RegionStatProcessor 继承自Processor,实现process方法。具体实现步骤如下:
import cn.itbigdata.dmp.customtrait.Processor
import cn.itbigdata.dmp.utils.{ConfigHolder, DateUtils}
import org.apache.spark.sql.{SaveMode, SparkSession}
object RegionStatProcessor extends Processor{
override def process(spark: SparkSession): Unit = {
// 定义参数
val sourceDataPath = s"outputdata/maindata-${DateUtils.getYesterday}"
val sinkDataPath = "output/regionstat"
// 读文件
val sourceDF = spark.read.json(sourceDataPath)
sourceDF.createOrReplaceTempView("adinfo")
// 处理数据
val RegionSQL1 =
"""
|select to_date(now()) as statdate, region, city, count(*) as infocount
| from adinfo
|group by region, city
|""".stripMargin
val sinkDF = spark.sql(RegionSQL1)
sinkDF.show()
// 写文件
sinkDF.coalesce(1).write.mode(SaveMode.Append).json(sinkDataPath)
}
}
5.2 广告投放地域分布
按照需求,完成以下模式的报表

备注:要求3个率:竞价成功率、广告点击率,媒体点击率
指标计算逻辑
| 指标 | 说明 | adplatformproviderid | requestmode | processnode | iseffective | isbilling | isbid | iswin | adorderid | adcreativeid |
|---|---|---|---|---|---|---|---|---|---|---|
| 原始请求 | 发来的所有原始请求数 | 1 | >=1 | |||||||
| 有效请求 | 满足有效体检的数量 | 1 | >=2 | |||||||
| 广告请求 | 满足广告请求的请求数量 | 1 | 3 | |||||||
| 参与竞价数 | 参与竞价的次数 | >=100000 | 1 | 1 | 1 | !=0 | ||||
| 竞价成功数 | 成功竞价的次数 | >=100000 | 1 | 1 | 1 | |||||
| (广告主)展示数 | 针对广告主统计:广告最终在终端被展示的数量 | 2 | 1 | |||||||
| (广告主)点击数 | 针对广告主统计:广告被展示后,实际被点击的数量 | 3 | 1 | |||||||
| (媒介)展示数 | 针对媒介统计:广告在终端被展示的数量 | 2 | 1 | 1 | ||||||
| (媒介)点击数 | 针对媒介统计:展示的广告实际被点击的数量 | 3 | 1 | 1 | ||||||
| DSP广告消费 | winprice/1000 | >=100000 | 1 | 1 | 1 | >200000 | >200000 | |||
| DSP广告成本 | Adptment/1000 | >=100000 | 1 | 1 | 1 | >200000 | >200000 |
DSP广告消费 = DSP的RTB的钱
DSP广告成本 = 广告主付给DSP的钱
DSP的盈利 = DSP广告成本 - DSP广告消费
备注:对应字段:
OriginalRequest、ValidRequest、adRequest
bidsNum、bidsSus、bidRate
adDisplayNum、adClickNum、adClickRate
MediumDisplayNum、MediumClickNum、MediumClickRate
adconsume、adcost
代码实现
import cn.itbigdata.dmp.customtrait.Processor
import cn.itbigdata.dmp.utils.DateUtils
import org.apache.spark.sql.{SaveMode, SparkSession}
object RegionAnalysisProcessor extends Processor{
override def process(spark: SparkSession): Unit = {
// 定义参数
val sourceDataPath = s"outputdata/maindata-${DateUtils.getYesterday}"
val sinkDataPath = "outputdata/regionanalysis"
// 读文件
val sourceDF = spark.read.json(sourceDataPath)
sourceDF.createOrReplaceTempView("adinfo")
// 处理数据
val RegionSQL1 =
"""
|select to_date(now()) statdate, region, city,
| sum(case when requestmode=1 and processnode>=1 then 1 else 0 end) as OriginalRequest,
| sum(case when requestmode=1 and processnode>=2 then 1 else 0 end) as ValidRequest,
| sum(case when requestmode=1 and processnode=3 then 1 else 0 end) as adRequest,
| sum(case when adplatformproviderid>=100000 and iseffective=1 and isbilling=1 and isbid=1 and adorderid!=0
| then 1 else 0 end) as bidsNum,
| sum(case when adplatformproviderid>=100000 and iseffective=1 and isbilling=1 and iswin=1
| then 1 else 0 end) as bidsSus,
| sum(case when requestmode=2 and iseffective=1 then 1 else 0 end) as adDisplayNum,
| sum(case when requestmode=3 and iseffective=1 then 1 else 0 end) as adClickNum,
| sum(case when requestmode=2 and iseffective=1 and isbilling=1 then 1 else 0 end) as MediumDisplayNum,
| sum(case when requestmode=3 and iseffective=1 and isbilling=1 then 1 else 0 end) as MediumClickNum,
| sum(case when adplatformproviderid>=100000 and iseffective=1 and isbilling=1
| and iswin=1 and adorderid>200000 and adcreativeid>200000
| then winprice/1000 else 0 end) as adconsume,
| sum(case when adplatformproviderid>=100000 and iseffective=1 and isbilling=1
| and iswin=1 and adorderid>200000 and adcreativeid>200000
| then adpayment/1000 else 0 end) as adcost
| from adinfo
|group by region, city
| """.stripMargin
spark.sql(RegionSQL1).createOrReplaceTempView("tabtemp")
val RegionSQL2 =
"""
|select statdate, region, city,
| OriginalRequest, ValidRequest, adRequest,
| bidsNum, bidsSus, bidsSus/bidsNum as bidRate,
| adDisplayNum, adClickNum, adClickNum/adDisplayNum as adClickRate,
| MediumDisplayNum, MediumClickNum, MediumClickNum/MediumDisplayNum as mediumClickRate,
| adconsume, adcost
| from tabtemp
""".stripMargin
val sinkDF = spark.sql(RegionSQL2)
// 写文件
sinkDF.coalesce(1).write.mode(SaveMode.Append).json(sinkDataPath)
}
}
6、数据标签化
6.1 什么是数据标签化
-
为什么要给数据打标签
- 分析数据的需求
- 用户对与数据搜索的需求,支持定向人群的条件筛选。如:
- 地域,甚至是商圈
- 性别
- 年龄
- 兴趣
- 设备
-
数据格式
目标数据:(用户id, 所有标签)。标签如下所示:
(CH@123485 -> 1.0, KW@word -> 1.0, CT@Beijing -> 1.0, GD@女 -> 1.0, AGE@40 -> 1.0, TA@北海 -> 1.0, TA@沙滩 -> 1.0)
- Tag 数据组织形式Map[String, Double]
- 前缀+标签;1.0为权重
-
需要制作的标签
- 广告类型
- 渠道
- App名称
- 性别
- 地理位置
- 设备
- 关键词
- 年龄
- 商圈(暂时不管)
-
日志数据的标签化
- 计算标签(广告类型、渠道、AppName、性别 ... ...)
- 提取用户标识
- 统一用户识别
- 标签数据落地
6.2 搭建框架
object TagProcessor extends Processor{
override def process(spark: SparkSession, kudu: KuduContext): Unit = {
// 定义参数
val sourceTableName = ConfigHolder.ADMainTableName
val sinkTableName = ""
val keys = ""
// 1 读数据
val sourceDF = spark.read
.option("kudu.master", ConfigHolder.kuduMaster)
.option("kudu.table", sourceTableName)
.kudu
// 2 处理数据
sourceDF.rdd
.map(row => {
// 广告类型、渠道、App名称
val adTags = AdTypeTag.make(row)
// 性别、地理位置、设备
// 关键词、年龄、商圈
})
// 3 保存数据
}
}
定义接口类:
import org.apache.spark.sql.Row
trait TagMaker {
def make(row: Row, dic: collection.Map[String, String]=null): Map[String, Double]
}
6.3 打标签
6.3.1 广告类型(AdTypeTag)
字段意义 1:banner; 2:插屏; 3:全屏
import cn.itbigdata.dmp.customtrait.TagMaker
import org.apache.spark.sql.Row
object AdTypeTag extends TagMaker{
private val adPrefix = "adtype@"
override def make(row: Row, dic: collection.Map[String, String]): Map[String, Double] = {
// 1 取值
val adType: Long = row.getAs[Long]("adspacetype")
// 1:banner; 2:插屏; 3:全屏
// 2 计算标签
adType match {
case 1 => Map(s"${adPrefix}banner" -> 1.0)
case 2 => Map(s"${adPrefix}插屏" -> 1.0)
case 3 => Map(s"${adPrefix}全屏" -> 1.0)
case _ => Map[String, Double]()
}
}
}
6.3.2 渠道(ChannelTag)
字段:channelid
import cn.itbigdata.dmp.customtrait.TagMaker
import org.apache.commons.lang3.StringUtils
import org.apache.spark.sql.Row
object ChannelTag extends TagMaker{
private val channelPrefix = "channel@"
override def make(row: Row, dic: collection.Map[String, String]=null): Map[String, Double] = {
// 1 取值
val channelid = row.getAs[String]("channelid")
// 2 计算标签
if (StringUtils.isNotBlank(channelid)){
Map(s"${channelPrefix}channelid" -> 1.0)
}
else
Map[String, Double]()
}
def main(args: Array[String]): Unit = {
// 判断某字符串是否不为空,且长度不为0,且不由空白符(空格)构成
if (!StringUtils.isNotBlank(null)) println("blank1 !")
if (!StringUtils.isNotBlank("")) println("blank2 !")
if (!StringUtils.isNotBlank(" ")) println("blank3 !")
}
}
6.3.3 App名称(AppNameTag)
字段:appid;要将 appid 转为 appname
查给定的字典表:dicapp
import cn.itbigdata.dmp.customtrait.TagMaker
import org.apache.commons.lang3.StringUtils
import org.apache.spark.sql.Row
object AppNameTag extends TagMaker{
// 获取前缀
private val appNamePrefix = "appname@"
override def make(row: Row, dic: collection.Map[String, String]): Map[String, Double] = {
// 1 获取地段信息
val appId = row.getAs[String]("appid")
// 2 计算并返回标签
val appName = dic.getOrElse(appId, "")
if (StringUtils.isNotBlank(appName))
Map(s"${appNamePrefix}$appName" -> 1.0)
else
Map[String, Double]()
}
}
6.3.4 性别(SexTag)
字段:sex;
import cn.itbigdata.dmp.customtrait.TagMaker
import org.apache.commons.lang3.StringUtils
import org.apache.spark.sql.Row
object SexTag extends TagMaker{
private val sexPrefix: String = "sex@"
override def make(row: Row, dic: collection.Map[String, String]=null): Map[String, Double] = {
// 获取标签信息
val sexid: String = row.getAs[String]("sex")
val sex = sexid match {
case "1" => "男"
case "2" => "女"
case _ => "待填写"
}
// 计算返回标签
if (StringUtils.isNotBlank(sex))
Map(s"$sexPrefix$sex" -> 1.0)
else
Map[String, Double]()
}
}
6.3.5 地理位置(GeoTag)
字段:region、city
import cn.itbigdata.dmp.customtrait.TagMaker
import org.apache.commons.lang3.StringUtils
import org.apache.spark.sql.Row
object GeoTag extends TagMaker{
private val regionPrefix = "region@"
private val cityPrefix = "city@"
override def make(row: Row, dic: collection.Map[String, String]=null): Map[String, Double] = {
// 获取标签信息
val region = row.getAs[String]("region")
val city = row.getAs[String]("city")
// 计算并返回标签信息
val regionTag = if (StringUtils.isNotBlank(region))
Map(s"$regionPrefix$region" -> 1.0)
else
Map[String, Double]()
val cityTag = if (StringUtils.isNotBlank(city))
Map(s"$cityPrefix$city" -> 1.0)
else
Map[String, Double]()
regionTag ++ cityTag
}
}
6.3.6 设备(DeviceTag)
字段:client、networkmannername、ispname;
数据字典:dicdevice
- client:设备类型 (1:android 2:ios 3:wp 4:others)
- networkmannername:联网方式名称(2G、3G、4G、其他)
- ispname:运营商名称(电信、移动、联通...)
import cn.itbigdata.dmp.customtrait.TagMaker
import org.apache.commons.lang3.StringUtils
import org.apache.spark.sql.Row
object DeviceTag extends TagMaker{
val clientPrefix = "client@"
val networkPrefix = "network@"
val ispPrefix = "isp@"
override def make(row: Row, dic: collection.Map[String, String]): Map[String, Double] = {
// 获取标签信息
val clientName: String = row.getAs[Long]("client").toString
val networkName: String = row.getAs[Long]("networkmannername").toString
val ispName: String = row.getAs[Long]("ispname").toString
// 计算并返回标签
val clientId = dic.getOrElse(clientName, "D00010004")
val networkId = dic.getOrElse(networkName, "D00020005")
val ispId = dic.getOrElse(ispName, "D00030004")
val clientTag = if (StringUtils.isNotBlank(clientId))
Map(s"$clientPrefix$clientId" -> 1.0)
else
Map[String, Double]()
val networkTag = if (StringUtils.isNotBlank(networkId))
Map(s"$networkPrefix$networkId" -> 1.0)
else
Map[String, Double]()
val ispTag = if (StringUtils.isNotBlank(ispId))
Map(s"$ispPrefix$ispId" -> 1.0)
else
Map[String, Double]()
clientTag ++ networkTag ++ ispTag
}
}
6.3.7 关键词(KeywordTag)
字段:keywords
import cn.itbigdata.dmp.customtrait.TagMaker
import org.apache.commons.lang3.StringUtils
import org.apache.spark.sql.Row
object KeywordsTag extends TagMaker{
private val keywordPrefix = "keyword@"
override def make(row: Row, dic: collection.Map[String, String]): Map[String, Double] = {
row.getAs[String]("keywords")
.split(",")
.filter(word => StringUtils.isNotBlank(word))
.map(word => s"$keywordPrefix$word" -> 1.0)
.toMap
}
}
6.3.8 年龄(AgeTag)
字段:age
import cn.itbigdata.dmp.customtrait.TagMaker
import org.apache.commons.lang3.StringUtils
import org.apache.spark.sql.Row
object AgeTag extends TagMaker{
private val agePrefix = "age@"
override def make(row: Row, dic: collection.Map[String, String]): Map[String, Double] = {
val age = row.getAs[String]("age")
if (StringUtils.isNotBlank(age))
Map(s"$agePrefix$age" -> 1.0)
else
Map[String, Double]()
}
}
6.3.9 主处理程序(TagProcessor)
import cn.itbigdata.dmp.customtrait.Processor
import cn.itbigdata.dmp.utils.DateUtils
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.sql.SparkSession
object TagProcessor extends Processor{
override def process(spark: SparkSession): Unit = {
// 定义参数
val sourceTableName = s"outputdata/maindata-${DateUtils.getYesterday}"
val appdicFilePath = "data/dicapp"
val deviceFilePath = "data/dicdevice"
val sinkTableName = ""
// 1 读数据
val sourceDF = spark.read.json(sourceTableName)
// 读app信息(文件),转换为广播变量(优化)
val appdicMap = spark.sparkContext.textFile(appdicFilePath)
.map(line => {
val arr: Array[String] = line.split("##")
(arr(0), arr(1))
}).collectAsMap()
val appdicBC: Broadcast[collection.Map[String, String]] = spark.sparkContext.broadcast(appdicMap)
// 读字典信息(文件),转换为广播变量(优化)
val deviceMap = spark.sparkContext.textFile(deviceFilePath)
.map(line => {
val arr: Array[String] = line.split("##")
(arr(0), arr(1))
}).collectAsMap()
val deviceBC: Broadcast[collection.Map[String, String]] = spark.sparkContext.broadcast(deviceMap)
// 2 处理数据
sourceDF.printSchema()
sourceDF.rdd
.map(row => {
// 广告类型、渠道、App名称
val adTags: Map[String, Double] = AdTypeTag.make(row)
val channelTags: Map[String, Double] = ChannelTag.make(row)
val appNameTags: Map[String, Double] = AppNameTag.make(row, appdicBC.value)
// 性别、地理位置、设备类型
val sexTags = SexTag.make(row)
val geoTags = GeoTag.make(row)
val deviceTags = DeviceTag.make(row, deviceBC.value)
// 关键词、年龄
val keywordsTags = KeywordsTag.make(row)
val ageTags = AgeTag.make(row)
// 将所有数据组成一个大的 Map 返回
val tags = adTags ++ channelTags ++ appNameTags ++ sexTags ++ geoTags ++ deviceTags ++ keywordsTags ++ ageTags
tags
}).collect.foreach(println)
// 3 保存数据
}
}
6.4 提取用户标识
日志数据针对某个用户单次特定的浏览行为
一个用户一天可能存在多条数据
标签是针对人的
-
存在的问题:
- 在数据集中抽出人的概念、让一个人能对应一条数据
- 在日志信息中找不到可用的用户id,只能退而求其次,找设备的信息,用设备的信息标识用户:
- IMEI:国际移动设备识别码(International Mobile Equipment Identity,IMEI),即通常所说的手机序列号、手机“串号”,用于在移动电话网络中识别每一部独立的手机等移动通信设备,相当于移动电话的身份证。IMEI是写在主板上的,重装APP不会改变IMEI。Android 6.0以上系统需要用户授予read_phone_state权限,如果用户拒绝就无法获得;
- IDFA:于iOS 6 时面世,可以监控广告效果,同时保证用户设备不被APP追踪的折中方案。可能发生变化,如系统重置、在设置里还原广告标识符。用户可以在设置里打开“限制广告跟踪”;
- mac地址:硬件标识符,包括WiFi mac地址和蓝牙mac地址。iOS 7 之后被禁止;
- OpenUDID:在iOS 5发布时,UDID被弃用了,这引起了广大开发者需要寻找一个可以替代UDID,并且不受苹果控制的方案。由此OpenUDID成为了当时使用最广泛的开源UDID替代方案。OpenUDID在工程中实现起来非常简单,并且还支持一系列的广告提供商;
- Android ID:在设备首次启动时,系统会随机生成一个64位的数字,并把这个数字以16进制字符串的形式保存下来,这个16进制的字符串就是ANDROID_ID,当设备被wipe后该值会被重置;
- 日志数据中可用于标识用户的字段包括:
- imei、mac、idfa、openudid、androidid
- imeimd5、macmd5、idfamd5、openudidmd5、androididmd5
- imeisha1、macsha1、idfasha1、openudidsha1、androididsha1
- 什么是无效数据:以上15个字段全部为空,那么这条数据不能与任何用户发生关联,这条数据对我们来说没有任何用处,它是无效数据。这些数据需要除去。
// 15个字段同时为空时需要过滤 lazy val filterSQL: String = idFields .split(",") .map(field => s"$field != ''") .mkString(" or ") // 抽取用户标识 val userIds = getUserIds(row) // 返回标签 (userIds.head, (userIds, tags)) // 提取用户标识 private def getUserIds(row: Row): List[String] = { val userIds: List[String] = idFields.split(",") .map(field => (field, row.getAs[String](field))) .filter { case (key, value) => StringUtils.isNotBlank(value) } .map { case (key, value) => s"$key::$value" }.toList userIds }
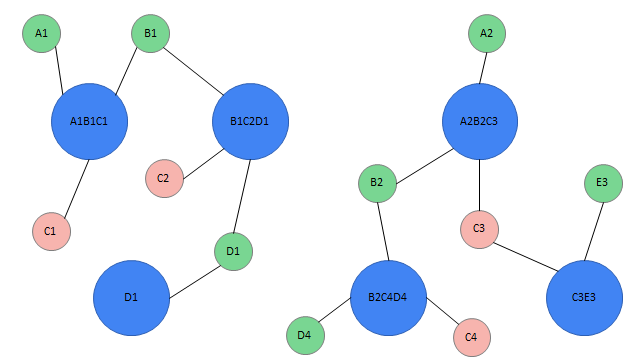
6.5 用户识别
- 使用十五个字段(非空)联合标识用户
- 数据采集过程中:
- 每次采集的数据可能是不同的字段
- 某些字段还可能发生变化
- 如何识别相同用户的数据?
6.6 用户识别&数据聚合与合并
// 统一用户识别;数据聚合与合并
private def graphxAnalysis(rdd: RDD[(List[String], List[(String, Double)])]): RDD[(List[String], List[(String, Double)])] ={
// 1 定义顶点(数据结构:Long, ""; 算法:List中每个元素都可作为顶点,List本身也可作为顶点)
val dotsRDD: RDD[(String, List[String])] = rdd.flatMap{ case (lst1, _) => lst1.map(elem => (elem, lst1)) }
val vertexes: RDD[(Long, String)] = dotsRDD.map { case (id, ids) => (id.hashCode.toLong, "") }
// 2 定义边(数据结构: Edge(Long, Long, 0))
val edges: RDD[Edge[Int]] = dotsRDD.map { case (id, ids) => Edge(id.hashCode.toLong, ids.mkString.hashCode.toLong, 0) }
// 3 生成图
val graph = Graph(vertexes, edges)
// 4 强连通图
val idRDD: VertexRDD[VertexId] = graph.connectedComponents()
.vertices
// 5 定义数据(ids与tags)
val idsRDD: RDD[(VertexId, (List[String], List[(String, Double)]))] =
rdd.map { case (ids, tags) => (ids.mkString.hashCode.toLong, (ids, tags)) }
// 6 步骤4的结果 与 步骤5的结果 做join,将全部的数据做了分类【一个用户一个分类】
val joinRDD: RDD[(VertexId, (List[String], List[(String, Double)]))] = idRDD.join(idsRDD)
.map { case (key, value) => value }
// 7 数据的聚合(相同用户的数据放在一起)
val aggRDD: RDD[(VertexId, (List[String], List[(String, Double)]))] = joinRDD.reduceByKey { case ((bufferIds, bufferTags), (ids, tags)) =>
(bufferIds ++ ids, bufferTags ++ tags)
}
// 8 数据的合并(对于id,去重;对tags,合并权重)
val resultRDD: RDD[(List[String], List[(String, Double)])] = aggRDD.map { case (key, (ids, tags)) =>
val newTags = tags.groupBy(x => x._1)
.mapValues(lst => lst.map { case (word, weight) => weight }.sum)
.toList
(ids.distinct, newTags)
}
resultRDD
}
6.7 标签落地
数据保存到kudu中,请注意:
1、每天保存一张表(需要新建),表名:usertags_当天日期
2、数据类型转换 RDD [(List[String], List[(String, Double)])] => RDD[(String, String)] => DataFrame
- 将 List[String] 转为 String;分隔符的定义要注意
- 将 List[(String, Double)] 转为String,分隔符的定义要注意
- 分隔符:不能与数据中的符号重复;分隔符保证要能加上,还要能去掉。
// 3 数据落地(kudu)
// 将List数据类型变为String
import spark.implicits._
val resultDF = mergeRDD.map{ case (ids, tags) =>
(ids.mkString("||"), tags.map{case (key, value) => s"$key->$value"}.mkString("||"))
}.toDF("ids", "tags")
DBUtils.appendData(kudu, resultDF, sinkTableName, keys)
}
// 获取昨天日期
6.8 标签处理代码(TagProcessor)
package cn.itcast.dmp.tags
import cn.itcast.dmp.Processor
import cn.itcast.dmp.utils.ConfigHolder
import org.apache.commons.lang3.StringUtils
import org.apache.kudu.spark.kudu.{KuduContext, KuduDataFrameReader}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{Row, SparkSession}
object TagProcessor extends Processor{
override def process(spark: SparkSession, kudu: KuduContext): Unit = {
// 定义参数
val sourceTableName = ConfigHolder.ADMainTableName
val sinkTableName = ""
val keys = ""
val dicAppPath = ConfigHolder.appNameDic
val dicDevicePath = ConfigHolder.deviceDic
val tradingAreaTableName = ConfigHolder.tradingAreaTableName
val filterSQL = ConfigHolder.filterSQL
val idFields = ConfigHolder.idFields
// 1 读数据
val sc = spark.sparkContext
val sourceDF = spark.read
.option("kudu.master", ConfigHolder.kuduMaster)
.option("kudu.table", sourceTableName)
.kudu
// 读app字典信息
val appDic = sc.textFile(dicAppPath)
.map(line => {
val arr = line.split("##")
(arr(0), arr(1))
})
.collect()
.toMap
val appDicBC = sc.broadcast(appDic)
// 读device字典信息
val deviceDic = sc.textFile(dicDevicePath)
.map(line => {
val arr = line.split("##")
(arr(0), arr(1))
})
.collect()
.toMap
val deviceDicBC = sc.broadcast(deviceDic)
// 读商圈信息(读;过滤;转为rdd;取数;收集数据到driver;转为map)
// 限制条件:商圈表的信息不能过大(过滤后的大小小于20M为宜)
val tradingAreaDic: Map[String, String] = spark.read
.option("kudu.master", ConfigHolder.kuduMaster)
.option("kudu.table", tradingAreaTableName)
.kudu
.filter("areas!=''")
.rdd
.map { case Row(geohash: String, areas: String) => (geohash, areas) }
.collect()
.toMap
val tradingAreaBC = sc.broadcast(tradingAreaDic)
// 2 处理数据
// 过滤15个标识字段都为空的数据
val userTagsRDD: RDD[(List[String], List[(String, Double)])] = sourceDF.filter(filterSQL)
.rdd
.map(row => {
// 广告类型、渠道、App名称
val adTags = AdTypeTag.make(row)
val channelTags = ChannelTag.make(row)
val appNameTags = AppNameTag.make(row, appDicBC.value)
// 性别、地理位置、设备
val sexTags = SexTag.make(row, appDicBC.value)
val geoTags = GeoTag.make(row, appDicBC.value)
val deviceTags = DeviceTag.make(row, deviceDicBC.value)
// 关键词、年龄、商圈
val keywordTags = KeywordTag.make(row, appDicBC.value)
val ageTags = AgeTag.make(row, appDicBC.value)
val tradingAreaTags = tradingAreaTag.make(row, tradingAreaDic.value)
// 标签合并
val tags = adTags ++ channelTags ++ appNameTags ++ sexTags ++ geoTags ++ deviceTags ++ keywordTags ++ ageTags ++ tradingAreaTags
// 抽取用户标识
val userIds: List[String] = idFields.split(",")
.map(field => (field, row.getAs[String](field)))
.filter { case (key, value) => StringUtils.isNotBlank(value) }
.map { case (key, value) => s"$key::$value" }.toList
// 返回标签
(userIds, tags)
})
userTagsRDD.foreach(println)
// 3 统一用户识别,合并数据
val mergeRDD: RDD[(List[String], List[(String, Double)])] = graphxAnalysis(logTagsRDD)
// 4 数据落地(kudu)
// 将List数据类型变为String
import spark.implicits._
val resultDF = mergeRDD.map{ case (ids, tags) =>
(ids.mkString("|||"), tags.map{case (key, value) => s"$key->$value"}.mkString("|||"))
}.toDF("ids", "tags")
DBUtils.createTableAndsaveData(kudu, resultDF, sinkTableName, keys)
// 关闭资源
sc.stop()
}
}
7、Spark GraphX
7.1 图计算基本概念
图是用于表示对象之间模型关系的数学结构。图由顶点和连接顶点的边构成。顶点是对象,而边是对象之间的关系。

有向图是顶点之间的边是有方向的。有向图的例子如 Twitter 上的关注者。用户 Bob 关注了用户 Carol ,而 Carol 并没有关注 Bob。

就是图,通过点(对象)和边(路径),构成了不同对象之间的关系
7.2 图计算应用场景
1)最短路径
最短路径在社交网络里面,有一个六度空间的理论,表示你和任何一个陌生人之间所间隔的人不会超过五个,也就是说,最多通过五个中间人你就能够认识任何一个陌生人。这也是图算法的一种,也就是说,任何两个人之间的最短路径都是小于等于6。
2)社群发现
社群发现用来发现社交网络中三角形的个数(圈子),可以分析出哪些圈子更稳固,关系更紧密,用来衡量社群耦合关系的紧密程度。一个人的社交圈子里面,三角形个数越多,说明他的社交关系越稳固、紧密。像Facebook、Twitter等社交网站,常用到的的社交分析算法就是社群发现。
3)推荐算法(ALS)
推荐算法(ALS)ALS是一个矩阵分解算法,比如购物网站要给用户进行商品推荐,就需要知道哪些用户对哪些商品感兴趣,这时,可以通过ALS构建一个矩阵图,在这个矩阵图里,假如被用户购买过的商品是1,没有被用户购买过的是0,这时我们需要计算的就是有哪些0有可能会变成1
GraphX 通过弹性分布式属性图扩展了 Spark RDD。
通常,在图计算中,基本的数据结构表达是:
-
Graph = (Vertex,Edge)
- Vertex (顶点/节点) (VertexId: Long, info: Any)
- Edge (边)Edge(srcId: VertexId, dstId: VertexId, attr) 【attr 权重】
7.3 Spark GraphX例子一(强连通体)

| ID | 关键词 | AppName |
|---|---|---|
| 1 | 卡罗拉 | 团车 |
| 2 | 印度尼西亚,巴厘岛 | 去哪儿旅游 |
| 3 | 善导大师 | 知乎 |
| 4 | 王的女人,美人无泪 | 优酷 |
| 5 | 世界杯 | 搜狐 |
| 6 | 刘嘉玲,港台娱乐 | 凤凰网 |
| 7 | 日韩娱乐 | 花椒直播 |
| 9 | AK47 | 绝地求生:刺激战场 |
| 10 | 搞笑 | YY直播 |
| 11 | 文学,时政 | 知乎 |
| ID | IDS |
|---|---|
| 1 | 43125 |
| 2 | 43125 |
| 3 | 43125 |
| 4 | 43125 |
| 5 | 43125 |
| 4 | 4567 |
| 5 | 4567 |
| 6 | 4567 |
| 7 | 4567 |
| 9 | 91011 |
| 10 | 91011 |
| 11 | 91011 |
Connected Components算法(连通体算法):
1、定义顶点
2、定义边
3、生成图
4、用标注图中每个连通体,将连通体中序号最小的顶点的id作为连通体的id
任务:
- 定义顶点
- 定义边
- 生成图
- 生成强连通图
import org.apache.spark.graphx.{Edge, Graph, VertexId}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object GraphXDemo1 {
def main(args: Array[String]): Unit = {
// 1、初始化sparkcontext
val conf = new SparkConf()
.setAppName("GraphXDemo1")
.setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("ERROR")
// 2、定义顶点 (VertexId: Long, info: Any)
val vertexes: RDD[(VertexId, Map[String, Double])] = sc.makeRDD(List(
(1L, Map("keyword:卡罗拉" -> 1.0, "AppName:团车" -> 1.0)),
(2L, Map("keyword:印度尼西亚" -> 1.0, "keyword:巴厘岛" -> 1.0, "AppName:去哪儿旅游" -> 1.0)),
(3L, Map("keyword:善导大师" -> 1.0, "AppName:知乎" -> 1.0)),
(4L, Map("keyword:王的女人" -> 1.0, "keyword:美人无泪" -> 1.0, "AppName:优酷" -> 1.0)),
(5L, Map("keyword:世界杯" -> 1.0, "AppName:搜狐" -> 1.0)),
(6L, Map("keyword:刘嘉玲" -> 1.0, "keyword:港台娱乐" -> 1.0, "AppName:凤凰网" -> 1.0)),
(7L, Map("keyword:日韩娱乐" -> 1.0, "AppName:花椒直播" -> 1.0)),
(9L, Map("keyword:AK47" -> 1.0, "AppName:绝地求生:刺激战场" -> 1.0)),
(10L, Map("keyword:搞笑" -> 1.0, "AppName:YY直播" -> 1.0)),
(11L, Map("keyword:文学" -> 1.0, "keyword:时政" -> 1.0, "AppName:知乎" -> 1.0))
))
// 3、定义边 Edge(srcId: VertexId, dstId: VertexId, attr)
val edges: RDD[Edge[Int]] = sc.makeRDD(List(
Edge(1L, 42125L, 0),
Edge(2L, 42125L, 0),
Edge(3L, 42125L, 0),
Edge(4L, 42125L, 0),
Edge(5L, 42125L, 0),
Edge(4L, 4567L, 0),
Edge(5L, 4567L, 0),
Edge(6L, 4567L, 0),
Edge(7L, 4567L, 0),
Edge(9L, 91011, 0),
Edge(10L, 91011, 0),
Edge(11L, 91011, 0)
))
// 4、生成图;生成强联通图
Graph(vertexes, edges)
.connectedComponents()
.vertices
.sortBy(_._2)
.collect()
.foreach(println)
// 5、资源释放
sc.stop()
}
}
7.4 Spark GraphX例子二(用户识别&数据合并)
根据前面的例子,我们已经知道根据规则如何识别用户,程序如何处理呢?
数据的定义:
备注:
1、这里定义的数据格式与我们程序中的数据格式完全一致
2、RDD中是一个元组,第一个元素代表用户的各种 id ;第二个元素代表用户的标签
任务:
1、6条数据代表多少个用户
2、合并相同用户的数据
val dataRDD: RDD[(List[String], List[(String, Double)])] = sc.makeRDD(List(
(List("a1", "b1", "c1"), List("keyword$北京" -> 1.0, "keyword$上海" -> 1.0, "area$中关村" -> 1.0)),
(List("b1", "c2", "d1"), List("keyword$上海" -> 1.0, "keyword$天津" -> 1.0, "area$回龙观" -> 1.0)),
(List("d1"), List("keyword$天津" -> 1.0, "area$中关村" -> 1.0)),
(List("a2", "b2", "c3"), List("keyword$大数据" -> 1.0, "keyword$spark" -> 1.0, "area$西二旗" -> 1.0)),
(List("b2", "c4", "d4"), List("keyword$spark" -> 1.0, "area$五道口" -> 1.0)),
(List("c3", "e3"), List("keyword$hive" -> 1.0, "keyword$spark" -> 1.0, "area$西二旗" -> 1.0))
))
完整的处理步骤:
- 定义顶点
- 定义边
- 生成图
- 找强连通体
- 找需要合并的数据
- 数据聚合
- 数据合并
处理程序:
import org.apache.spark.graphx.{Edge, Graph, VertexId, VertexRDD}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object GraphXDemo {
def main(args: Array[String]): Unit = {
// 初始化
val conf: SparkConf = new SparkConf().setAppName("GraphXDemo").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("error")
// 定义数据
val dataRDD: RDD[(List[String], List[(String, Double)])] = sc.makeRDD(List(
(List("a1", "b1", "c1"), List("kw$北京" -> 1.0, "kw$上海" -> 1.0, "area$中关村" -> 1.0)),
(List("b1", "c2", "d1"), List("kw$上海" -> 1.0, "kw$天津" -> 1.0, "area$回龙观" -> 1.0)),
(List("d1"), List("kw$天津" -> 1.0, "area$中关村" -> 1.0)),
(List("a2", "b2", "c3"), List("kw$大数据" -> 1.0, "kw$spark" -> 1.0, "area$西二旗" -> 1.0)),
(List("b2", "c4", "d4"), List("kw$spark" -> 1.0, "area$五道口" -> 1.0)),
(List("c3", "e3"), List("kw$hive" -> 1.0, "kw$spark" -> 1.0, "area$西二旗" -> 1.0))
))
val value: RDD[(String, List[String], List[(String, Double)])] = dataRDD.flatMap { case (allIds: List[String], tags: List[(String, Double)]) => {
allIds.map { case elem: String => (elem, allIds, tags) }
}
}
// 1 将标识信息中的每一个元素抽取出来,作为id
// 备注1、这里使用了flatMap,将元素压平;
// 备注2、这里丢掉了标签信息,因为这个RDD主要用于构造顶点、边,tags信息用不
// 备注3、顶点、边的数据要求Long,所以这里做了数据类型转换
val dotRDD: RDD[(VertexId, VertexId)] = dataRDD.flatMap { case (allids, tags) =>
// 方法一:好理解,不好写
// for (id <- allids) yield {
// (id.hashCode.toLong, allids.mkString.hashCode.toLong)
// }
// 方法二:不好理解,好写。两方法等价
allids.map(id => (id.hashCode.toLong, allids.mkString.hashCode.toLong))
}
// 2 定义顶点
val vertexesRDD: RDD[(VertexId, String)] = dotRDD.map { case (id, ids) => (id, "") }
// 3 定义边(id: 单个的标识信息;ids: 全部的标识信息)
val edgesRDD: RDD[Edge[Int]] = dotRDD.map { case (id, ids) => Edge(id, ids, 0) }
// 4 生成图
val graph = Graph(vertexesRDD, edgesRDD)
// 5 找到强连通体
val connectRDD: VertexRDD[VertexId] = graph.connectedComponents()
.vertices
// 6 定义中心点的数据
val centerVertexRDD: RDD[(VertexId, (List[String], List[(String, Double)]))] = dataRDD.map { case (allids, tags) =>
(allids.mkString.hashCode.toLong, (allids, tags))
}
// 7 步骤5、6的数据做join,获取需要合并的数据
val allInfoRDD = connectRDD.join(centerVertexRDD)
.map { case (id1, (id2, (allIds, tags))) => (id2, (allIds, tags)) }
// 8 数据聚合(即将同一个用户的标识、标签放在一起)
val mergeInfoRDD: RDD[(VertexId, (List[String], List[(String, Double)]))] = allInfoRDD.reduceByKey { case ((bufferList, bufferMap), (allIds, tags)) =>
val newList = bufferList ++ allIds
// map 的合并
val newMap = bufferMap ++ tags
(newList, newMap)
}
// 9 数据合并(allIds:去重;tags:合并权重)
val resultRDD: RDD[(List[String], Map[String, Double])] = mergeInfoRDD.map { case (key, (allIds, tags)) =>
val newIds = allIds.distinct
// 按照key做聚合;然后对聚合得到的lst第二个元素做累加
val newTags = tags.groupBy(x => x._1).mapValues(lst => lst.map(x => x._2).sum)
(newIds, newTags)
}
resultRDD.foreach(println)
sc.stop()
}
// def main(args: Array[String]): Unit = {
// val lst = List(
// ("kw$大数据",1.0),
// ("kw$spark",1.0),
// ("area$西二旗",1.0),
// ("kw$spark",1.0),
// ("area$五道口",1.0),
// ("kw$hive",1.0),
// ("kw$spark",1.0),
// ("area$西二旗",1.0)
// )
//
// lst.groupBy(x=> x._1).map{case (key, value) => (key, value.map(x=>x._2).sum)}.foreach(println)
// println("************************************************************")
//
// lst.groupBy(x=> x._1).mapValues(lst => lst.map(x=>x._2).sum).foreach(println)
// println("************************************************************")
}










