1 垃圾
1.1 前言
众所周知,JVM拥有着垃圾回收器,自动回收内存,让开发人员只专注于编程,而不需要手动进行内存管理。
那么到底什么样的对象才会被定义为垃圾,且被JVM的垃圾回收器回收掉
1.2 定位
1.2.1 简介
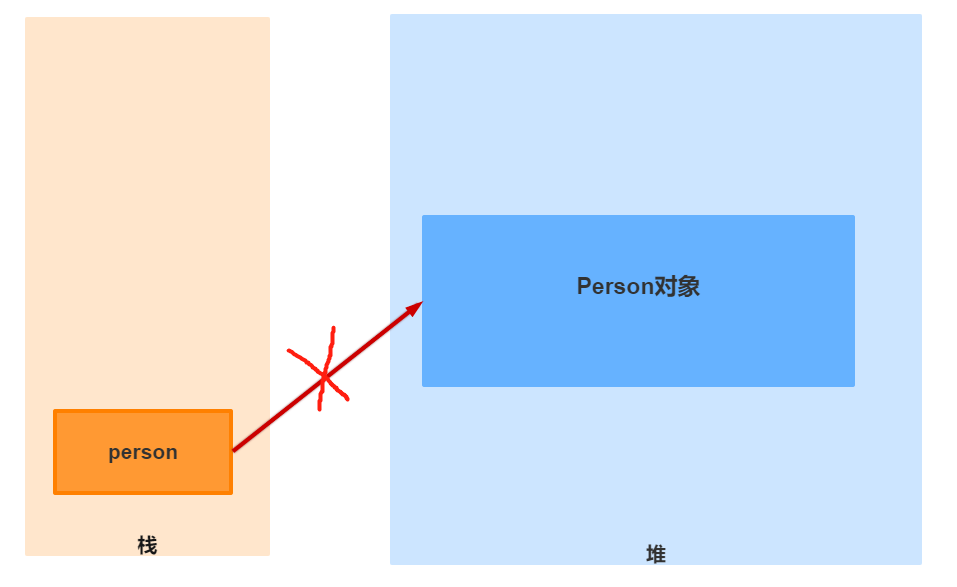
在JVM中当一个对象没有任何引用指向他的时候就会被认为是一个垃圾,例如下图中
当栈里面的person引用不再指向堆里面的Person对象时,Person对象就会被认为是一个垃圾对象,那么就会被回收掉
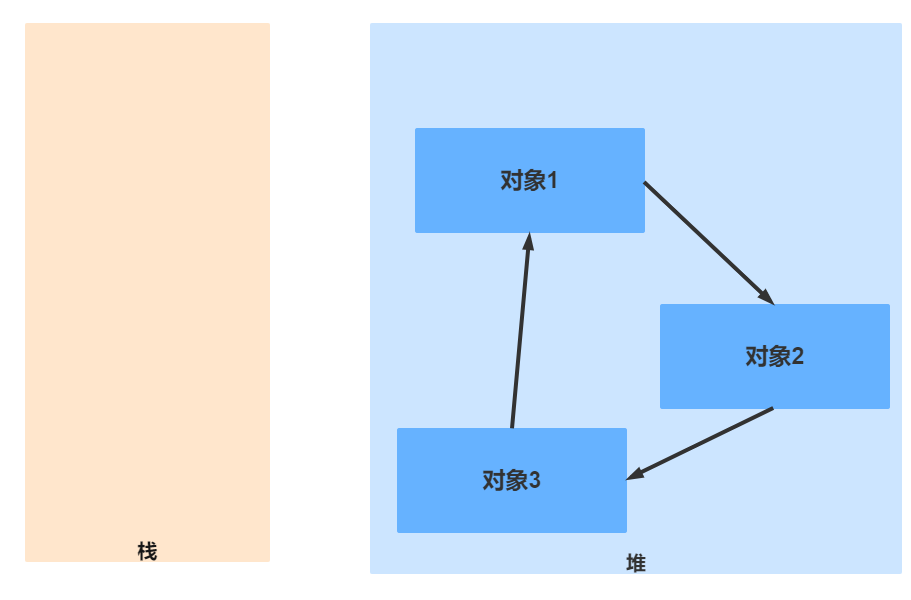
但有时候在堆里面,对象相互指向,但是栈里面并没有任何一个引用指向对象,那么那些对象会被认为是一堆垃圾。如下图所示
1.2.2 寻找
那么JVM是如何寻找到垃圾对象,并且进行回收掉的呢? 在JVM有两种算法去定位垃圾的存在:
- 引用计数算法
- 根可达算法
接下来就来仔细探讨这两种算法的区别是什么
引用计数
所谓的引用计数指的的就是记录一个对象有多少个引用指向该对象。当引用为0,即没有任何引用指向该对象时,就认为该对象为垃圾。
如图


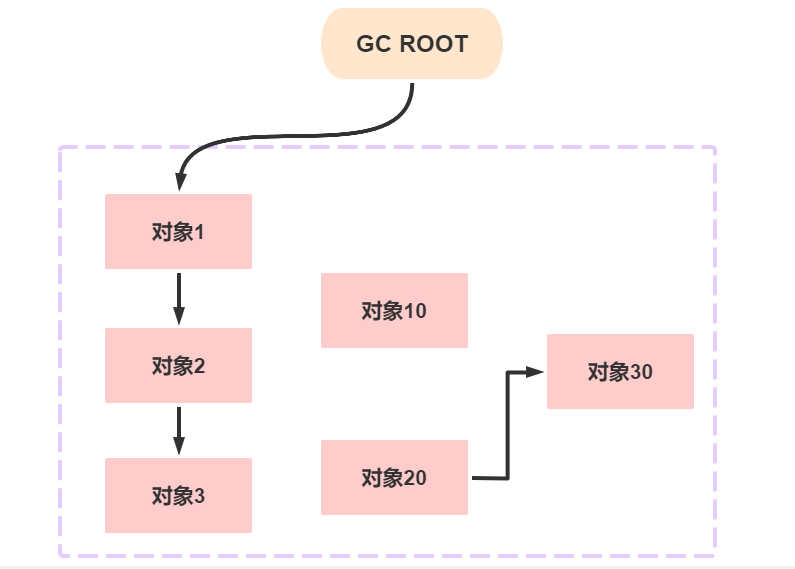
根可达算法
所谓的根可达算法就是一系列称为GCRoots的根对象作为起始节点集,从这些节点开始,根据引用关系向下搜索,搜索过程所走过的路径称为“引用链”(ReferenceChain)。
如果某个对象到GCRoots间没有任何引用链相连,或者用图论的话来说就是从GCRoots到这个对象不可达时,则证明此对象是不可能再被使用的
如图所示
在JVM规范中以下对象会认为是根:
- 在虚拟机栈(栈帧中的本地变量表)中引用
- 在本地方法栈中
JNI(即通常所说的Native方法)引用 - 运行常量池引用
- 方法区的静态引用
-
Class类型引用还有一些常驻对象引用(NullPointerException)
2. 回收
在JVM中关于常见垃圾回收的算法,一共有三个:
- 标记清除算法(
Mark-Sweep) - 复制算法(
Copy) - 标记压缩算法(
Mark-Compact)
下面是对这三种算法的详细描述和对比
2.1 Mark-Sweep
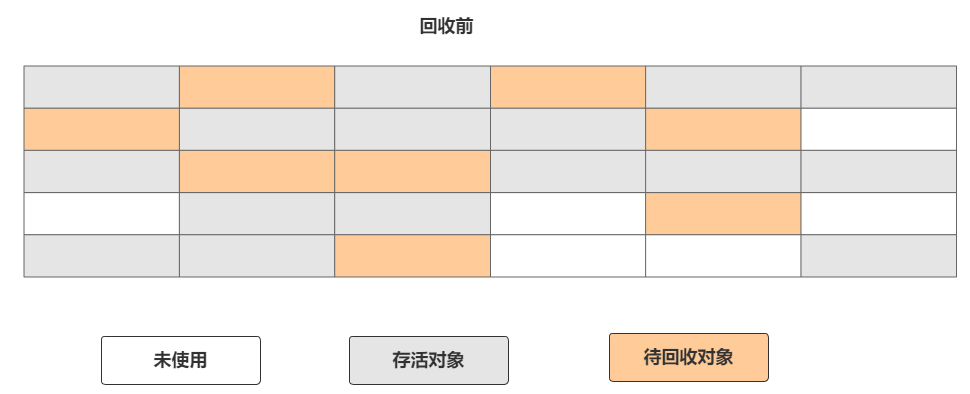
JVM中最早出现的垃圾回收算法,算法主要分为标记和清除两部分,简单了解就是先标记所有的垃圾对象,然后统一回收掉所有的标记对象。如下图所示
2.2 Mark-Copying
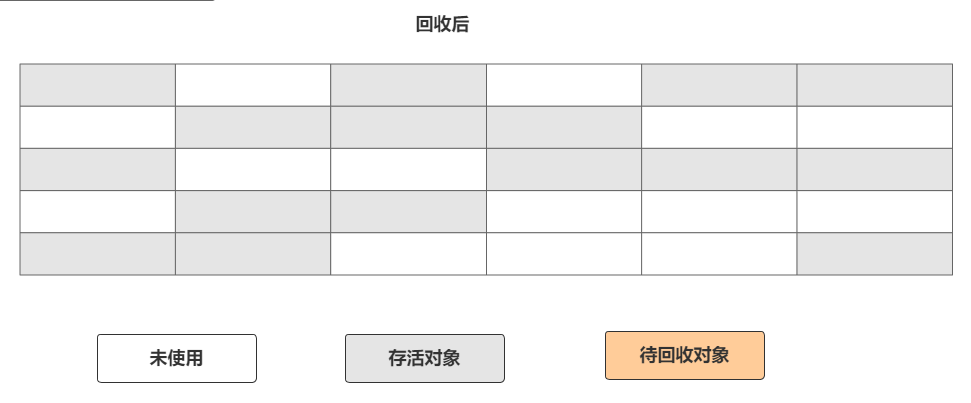
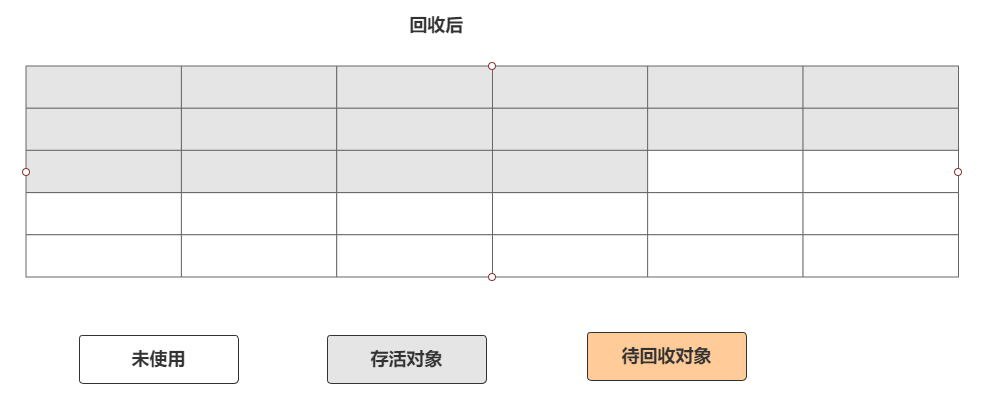
标记-复制算法也叫复制算法,这种算法的出现主要是为了解决标记-清除算法的缺陷。标记-复制算法就是将一个可用内存划分为两块等同的区域。
每次都使用其中某一块区域,当一块区域(A)使用完毕就会把存活的对象复制到另外一块区域(B),复制完成,再将之前的区域(A)进行清空。如图
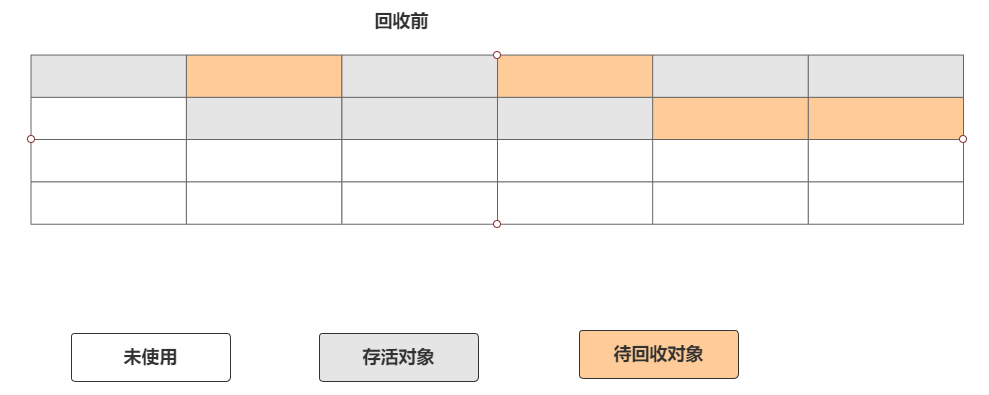
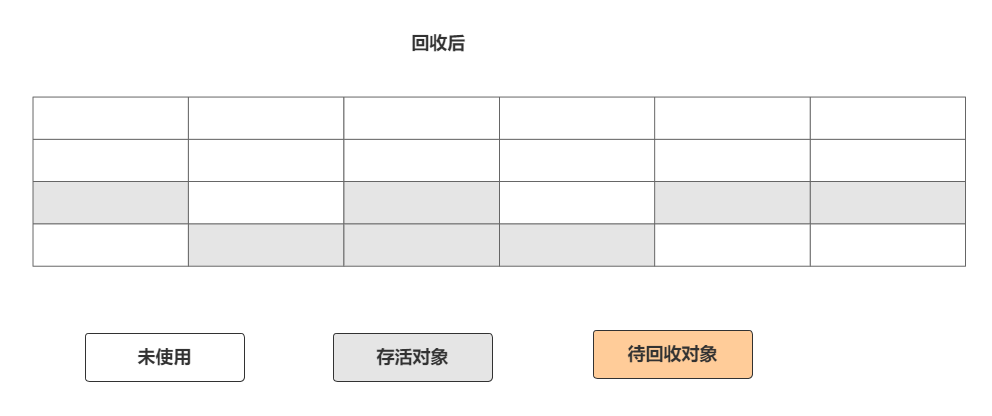
这种算法好处如下:
- 实现简单,运行高效
- 可以为一个对象分配一个连续的内存空间,不用考虑碎片化内存
- 回收时只需要对半个内存空间全部清空即可
但是缺点也显而易见,如下:
- 存在内存空间的复制开销
- 可使用的内存缩小为原来的一半,存在空间浪费
2.3 Mark-Compact
标记-压缩算法也是针对标记-清除算法,进行改进,当标记的对象清除以后,存货的对象进行移动,从而防止碎片化的内存出现。具体如下:

这种算法与之前的标记-清除算法本质的区别就是,标记-清除算法只是清除,而不会移动存活的对象。标记-压缩则是清除后会进行移动,从而防止碎片化的内存出现
这种算法也有很大的缺陷:
移动存活对象操作必须全程暂停用户程序才能进行。
这种算法主要是针对老年代,老年代存活对象较多,如果频繁对老年代进行垃圾回收,会导致程序卡顿,因此这种现象称为
STW(Stop The World)
3. 分代
在经典的垃圾回收器中,JVM采用了分代模型(主要是针对jdk1.7 - jdk1.9),JVM将堆分为了两部分
-
新生代
- 新出生的对象都在新生代
- 新生代的对象朝生夕死
- 采用标记-复制算法进行垃圾回收
-
老年代
- 垃圾较少,存活对象较多
- 一般采用标记-压缩算法,如果采用的是G1垃圾回收器则采用标记-复制算法
-
永久代
- 在
JDK1.8之后没有永久代了,取而代之的是元数据区(Metaspace) - 永久代 和 元数据区都是用来存放 Class对象
- 永久代可以指定大小,元数据区则不需要指定大小,而是直接依赖物理内存
- 在
堆内存模型图如下:
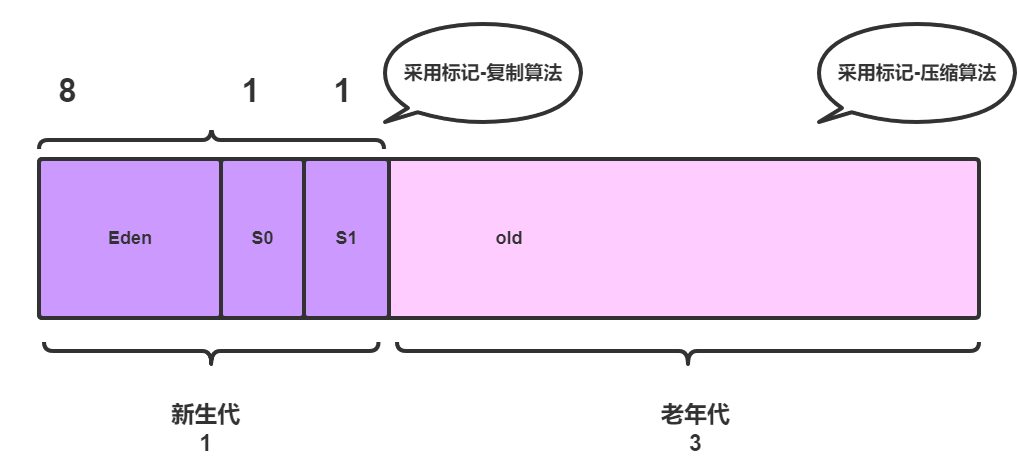
3.1 新生代
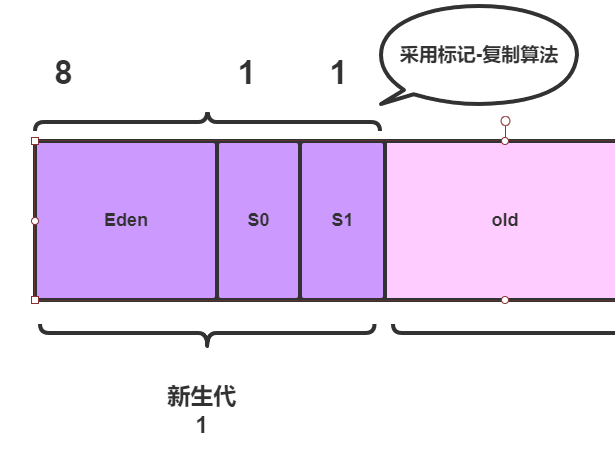
新生代主要分为三个区域:
- 伊甸区(
eden) - 幸存0区(
survivor0) - 幸存1区(
survivor1)
其中他们的比例为 8 :1 : 1,同时,新生代采用的是复制算法进行垃圾回收。如下:
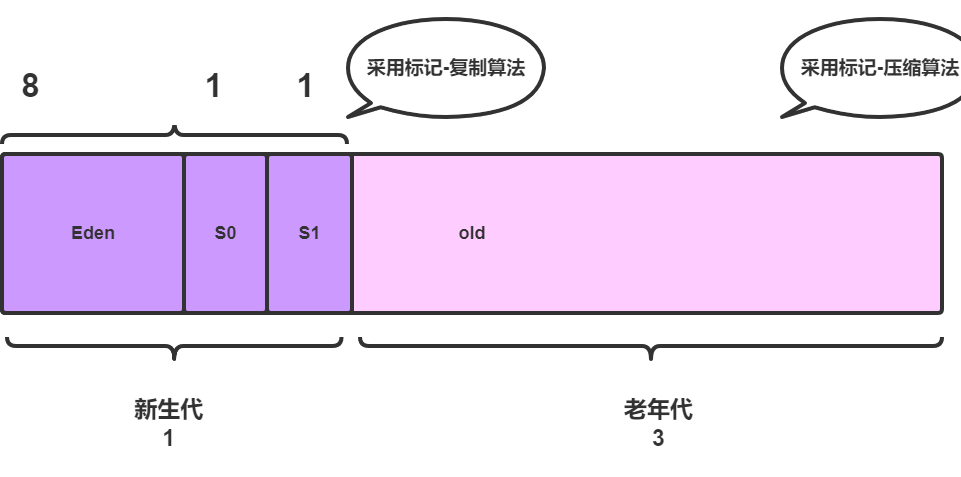
3.2 老年代
老年代与新生代比例为3:1,如下:
4. 回收器
上述都是对JVM进行理论阐述,而垃圾回收器则是对上述理论的实现。在《JVM规范》中没有对垃圾回收器做各种规定,因此不同的厂商的不同虚拟机会存在不同的区别。
在这里主要是探讨HotSpot虚拟机的垃圾回收器,关于所有垃圾回收器(jdk1.0-jdk13)如下图

图中的G1,ZGC,Shenandoah回收器不再区分新生代和老年代,Epsilon是JDK内部调试的回收器
在目前的环境中,向后面三个用的还是比较少的,因此主要是还是集中讨论新生代和老年代的垃圾回收
4.1 新生代
4.1.1 Serial
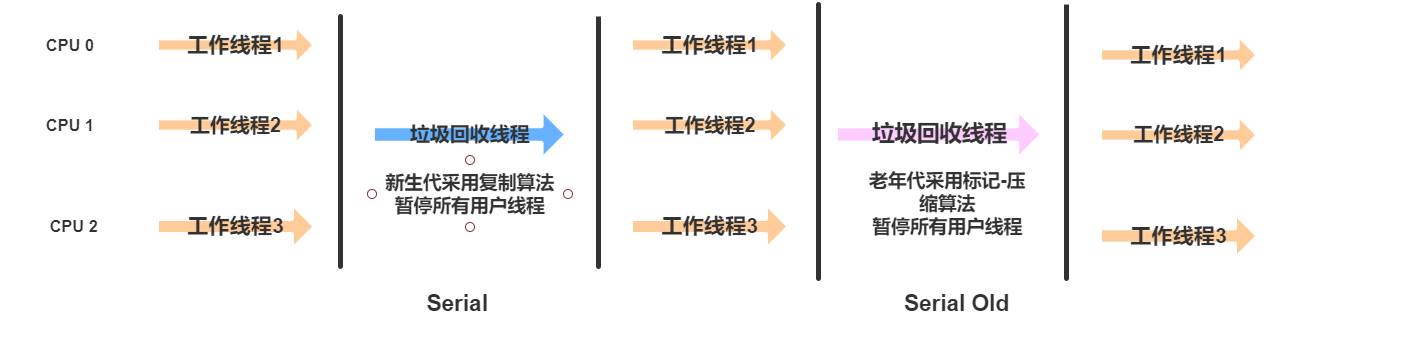
Serial回收器是一个用来新生代垃圾回收器,Serial old是一个用在老年代的垃圾回收器
这个回收器是一个单线程工程的垃圾回收器,这个“单线程”回收器是指使用一个处理器或者一条收集线程去执行。
当进行垃圾回收的时候,必须暂停其他所有的工作线程,直到回收结束。当然这样就会产生STW现象。如下:
4.1.2 ParNew
ParNew垃圾回收器本质上相当于Serial垃圾回收器的多线程并行版本,除了在回收的时候使用多线程并行回收,其他的与Serial回收器一摸一样。
具体工作流程如下:

4.1.3 Parallel Scavenge
Parallel Scavenge与ParNew回收器类似,也是一个新生代的垃圾回收器,也是基于标记-复制算法实现的垃圾回收器。同时也是一款并行的垃圾回收器,
只不过Parallel Scavenge更加专注于一个可以达到的吞吐量
吞吐量越高就意味着垃圾回收时间越短,例如用户代码运行时间是20s,垃圾回收时间1s,那么意味着吞吐量为20/21 =95%
当然也可以通过一些参数去设置用户的吞吐量:
-
-XX: MaxGCPauseMillis设置最大垃圾收集停顿时间 -
-XX: GCTimeRatio设置吞吐量大小
工作流程图如下:
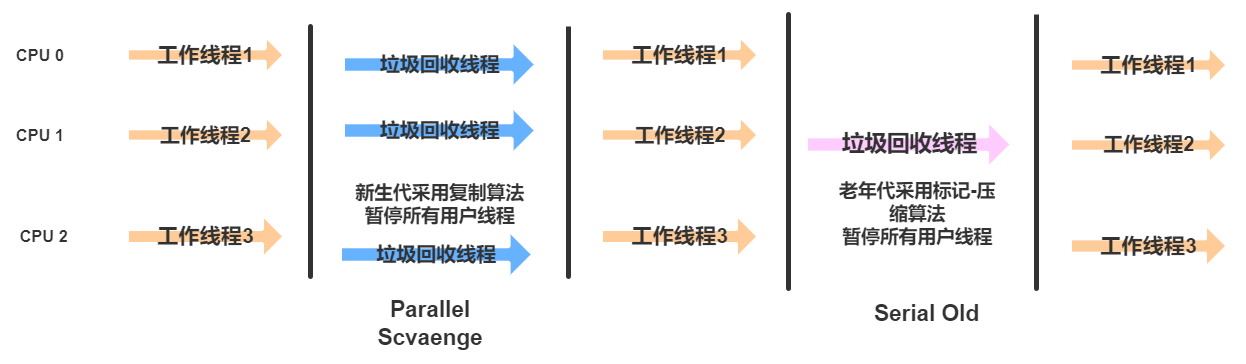
4.2 老年代
4.2.1 Serial Old
Serial Old就相当于Serial垃圾回收器的老年代版本,同样的是单线程,采用标记-压缩算法。这里就不再追诉了
4.2.2 Parallel Old
Parallel Old 回收器相当于是Parallel Scavenge回收器的老年代版本,这个回收器同样是一个基于标记-压缩算的多线程垃圾回收器。
这个垃圾回收器是在jdk1.6以后才开始提供,之前Parallel Scavenge垃圾回收器都是于Serial Old垃圾回收器配合使用。
直到Parallel Old垃圾回收器的出现,老年代才慢慢开始以吞吐量优先饿垃圾回收器
工作流程图如下:
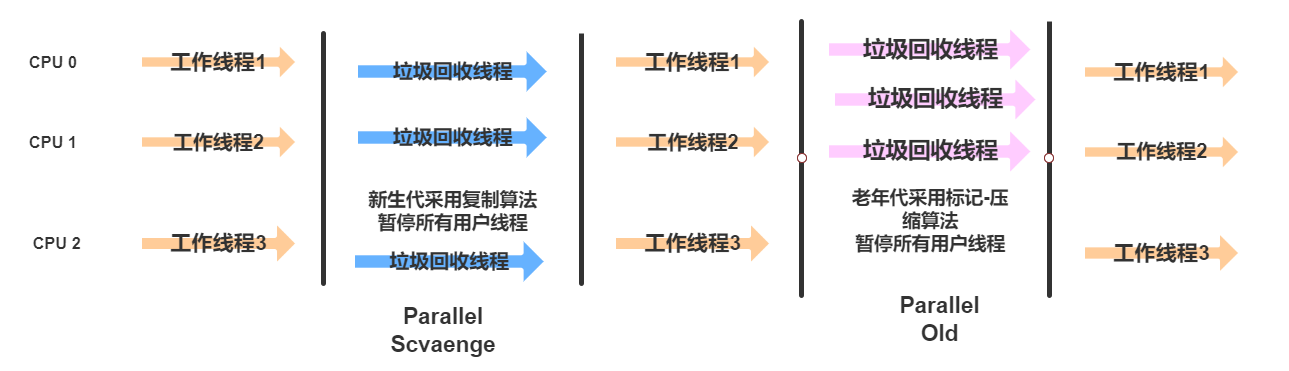
4.2.3 CMS
-
简介
CMS(Concurrent Mark Sweep)回收器是一个老年代的垃圾回收器,从名字可以看到是一个并发的,标记-清除垃圾回收器。
这个回收器是以最短回收停顿时间 为目标的垃圾回收器,从上述的介绍中可以得到老年代的的垃圾回收器,都需要暂停用户线程在进行垃圾回收,因此都会产生STW现象
而当今大部分Java程序都是以B/S架构为主,在开发这类程序时,更加关注服务端的响应时间,也就说尽量减少系统的停顿时间。
那么CMS回收器就是一个尽量减少停顿时间的的垃圾回收器。
-
工作原理
与之前的标记-压缩算法不用,
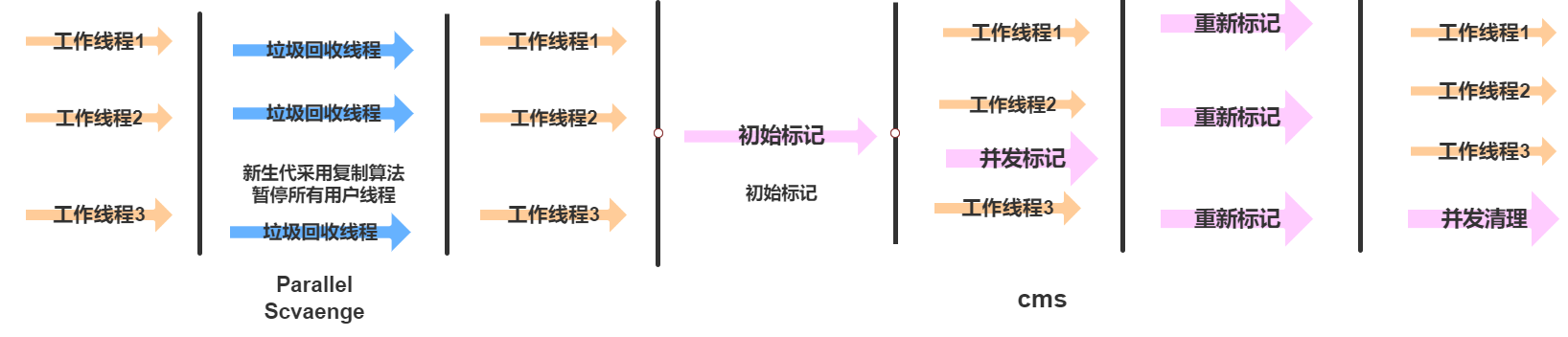
CMS垃圾回收器则是基于标记-清除算法,该垃圾回收器主要基于以下几部分:- 初始标记
- 并发标记
- 重新标记
- 并发清除
其中初始标记,重新标记还是会产生
STW,但是这个时间非常短,不会占据特别长的时间初始标记只是标记以下
GC ROOT能够直接关联的对象,如下图,初始标记就是标记对象1 和 对象11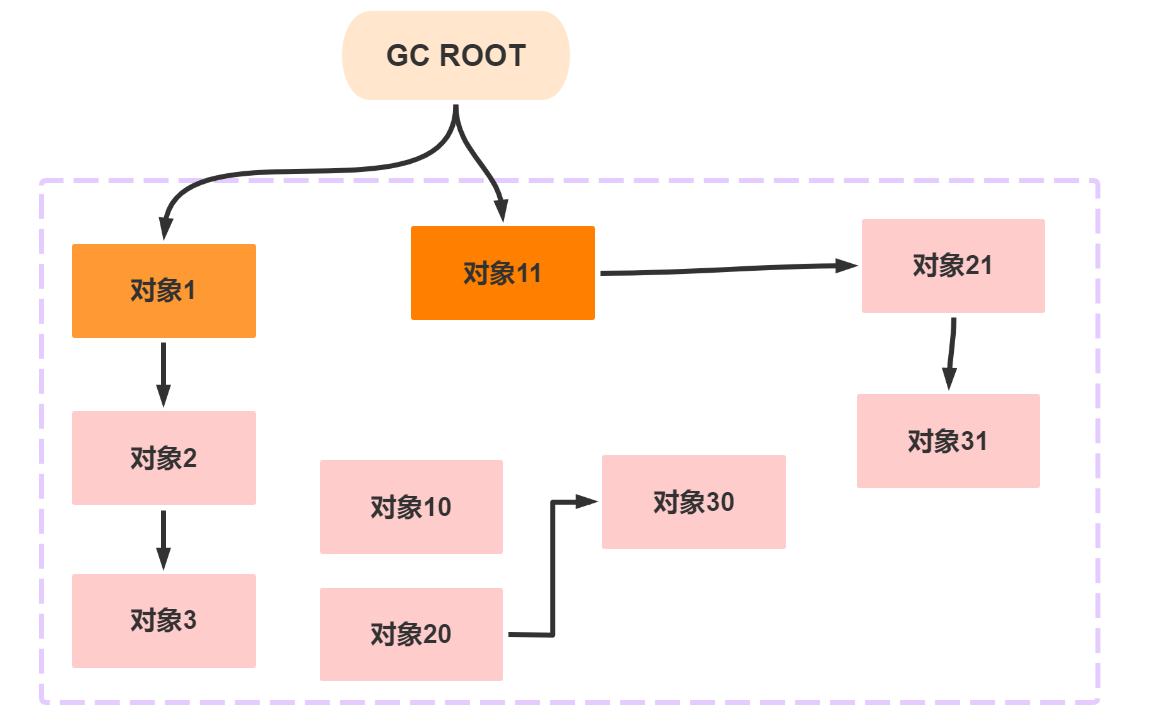
并发标记 是从
GC Root遍历整个对象的过程,这个速度需要的时间较长,但是不会暂停用户所有的线程,而是和用户线程一起执行,这样也不会产生停顿的现象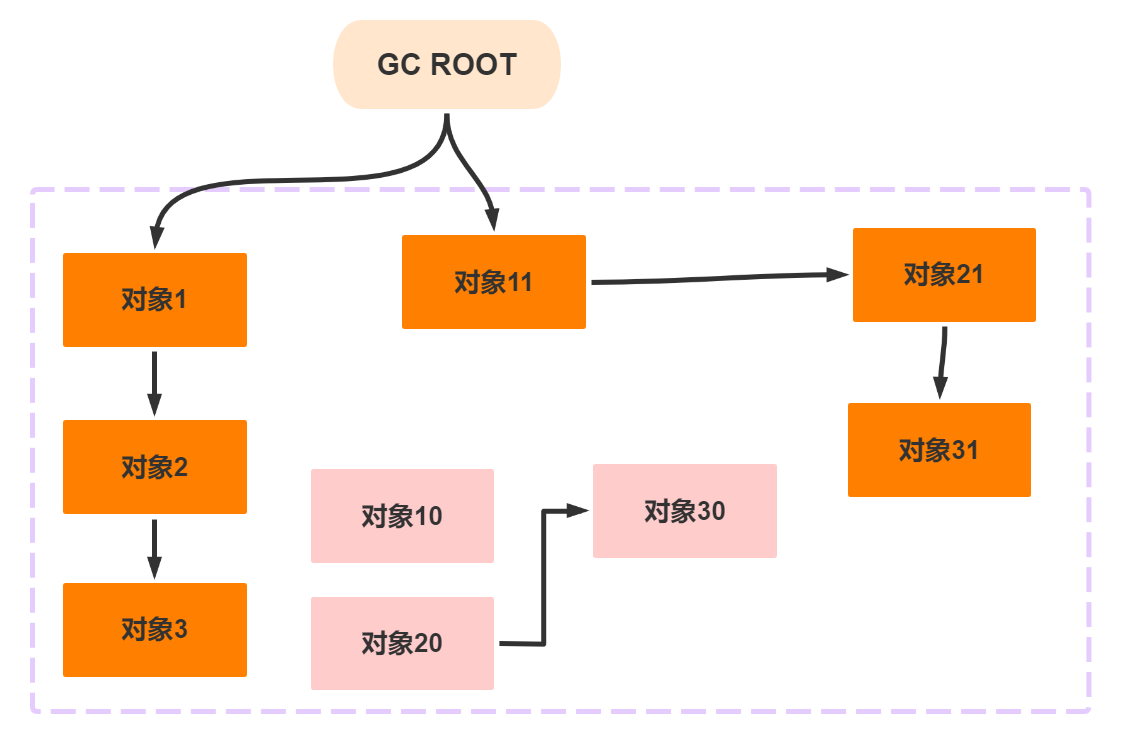
重新标记则是修改并发标记期间,因为用户程序的运行,从而导致标记的对象发生变量
例如:上图中有可能在程序运行过程中
GC ROOT不再指向对象11,因此需要重新标记但是这个标记时间比初始标记长,但是比并发标记时间短。
并发清理清除上述标记中需要清除的垃圾对象,由于是采用标记-清除算法,因此也不需要向标记-压缩算法一样,移动存活的对象,所以这个时间也是比较快的。
同时这个过程也不需要暂停用户所有线程,而是与用户线程一起运行,如下图所示:
当然这个垃圾收器也有一些缺点,例如最明显由于采用标记-清除算法,所以就会导致会产生过多的随便化空间,这样会给大对象分配带来很大的麻烦。
当没有足够大的空间为大内存,不得不提前触发一次FullGC的情况。为了解决这个问题,CMS收集器提供了一个
-XX:+UseCMS-CompactAtFullCollection开关参数用于在CMS收集器不得不进行FullGC时开启内存碎片的合并整理过程,由于这个内存整理必须移动存活对象,所以就会导致停顿时间过长等
5. 指令
JVM的指令主要分为三大类:
-
标准指令
以
-开头,所有版本的HotSpot的都支持 -
非标准指令
以
-X开头 特定版本的HotSpot都支持 -
高级运行时指令
以
-XX开头,可能下个版本会取消的指令
所有详细命令可以参考以下网址:
http://www.oracle.com/technetwork/java/javase/documentation/index.html
5.1 非标准
输入java -X即可看到常用的非标准指令,如下:
-Xmixed 混合模式执行 (默认)
-Xint 仅解释模式执行
-Xbootclasspath:<用 ; 分隔的目录和 zip/jar 文件>
设置搜索路径以引导类和资源
-Xbootclasspath/a:<用 ; 分隔的目录和 zip/jar 文件>
附加在引导类路径末尾
-Xbootclasspath/p:<用 ; 分隔的目录和 zip/jar 文件>
置于引导类路径之前
-Xdiag 显示附加诊断消息
-Xnoclassgc 禁用类垃圾收集
-Xincgc 启用增量垃圾收集
-Xloggc:<file> 将 GC 状态记录在文件中 (带时间戳)
-Xbatch 禁用后台编译
-Xms<size> 设置初始 Java 堆大小
-Xmx<size> 设置最大 Java 堆大小
-Xss<size> 设置 Java 线程堆栈大小
-Xprof 输出 cpu 配置文件数据
-Xfuture 启用最严格的检查, 预期将来的默认值
-Xrs 减少 Java/VM 对操作系统信号的使用 (请参阅文档)
-Xcheck:jni 对 JNI 函数执行其他检查
-Xshare:off 不尝试使用共享类数据
-Xshare:auto 在可能的情况下使用共享类数据 (默认)
-Xshare:on 要求使用共享类数据, 否则将失败。
-XshowSettings 显示所有设置并继续
-XshowSettings:all
显示所有设置并继续
-XshowSettings:vm 显示所有与 vm 相关的设置并继续
-XshowSettings:properties
显示所有属性设置并继续
-XshowSettings:locale
显示所有与区域设置相关的设置并继续
-X 选项是非标准选项, 如有更改, 恕不另行通知。
例如在这里可以设置堆的初始化内存大小和最大堆
java -Xms128m -Xmx1024m
5.2 高级运行时指令
常用的高级指令如下:
-XX:+PrintFlagsFinal
# 设置最终生效值
-XX:+PrintFlagsInitial
# 查看默认值
-XX:+PrintCommandLineFlags
# 查看命令行参数
例如输入
java -XX:PrintCommandLineFlags

上图中选中的代表现在HotSpot虚拟机采用的是Parallel Scavenage + Parallel Old垃圾回收器










