一、先在本地安装jdk
我这里安装的jdk1.8,具体的安装过程这里不作赘述
二、部署安装maven
下载maven安装包,并解压
设置环境变量,MAVEN_HOME=D:\SoftWare\Maven\apache-maven-3.6.1
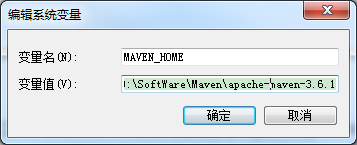
在path路径添加;%MAVEN_HOME%\bin
打开本地终端验证
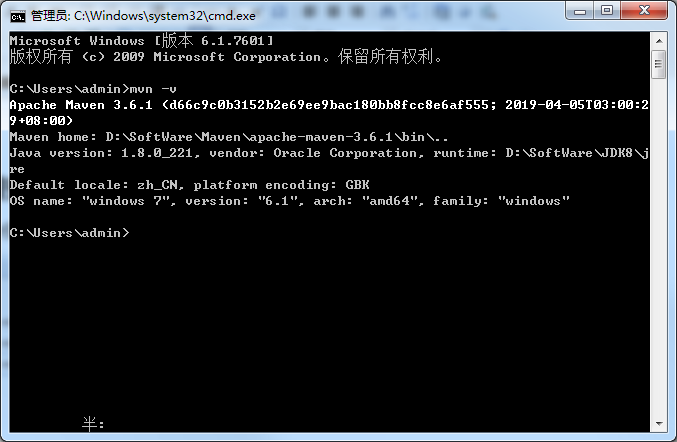
三、安装hadoop
先下载hadoop压缩包 下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-2.6.0/
下载后解压到本地
配置环境变量
计算机 –>属性 –>高级系统设置 –>高级选项卡 –>环境变量 –> 单击新建HADOOP_HOME
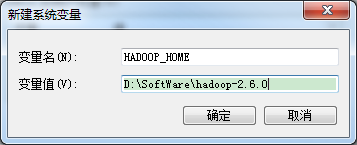
HADOOP_HOME=D:\SoftWare\hadoop-2.6.0
Path环境变量下配置【%HADOOP_HOME%\bin;】变量
打开终端验证一下hadoop是否安装成功
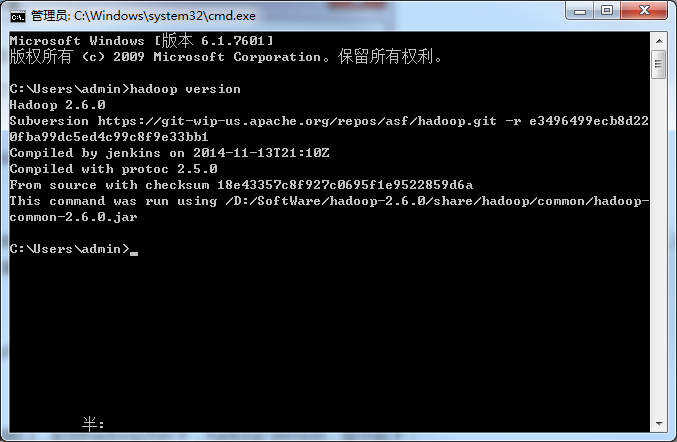
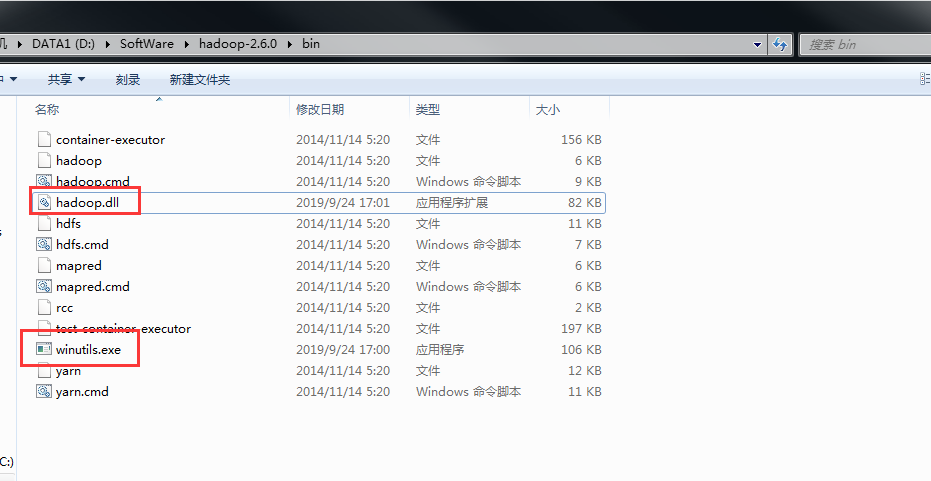
给hadoop添加插件,添加到hadoop/bin目录下
修改hadoop的配置文件,配置文件在路径D:\SoftWare\hadoop-2.6.0\etc\hadoop下
修改core-site.xml

<configuration>
<!--指定namenode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!--用来指定hadoop产生临时文件的目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/D:/SoftWare/hadoop-2.6.0/tmp/</value>
</property>
<!--用于设置检查点备份日志的最长时间-->
<property>
<name>fs.checkpoint.period</name>
<value>3600</value>
</property>
</configuration>
修改hdfs-site.xml
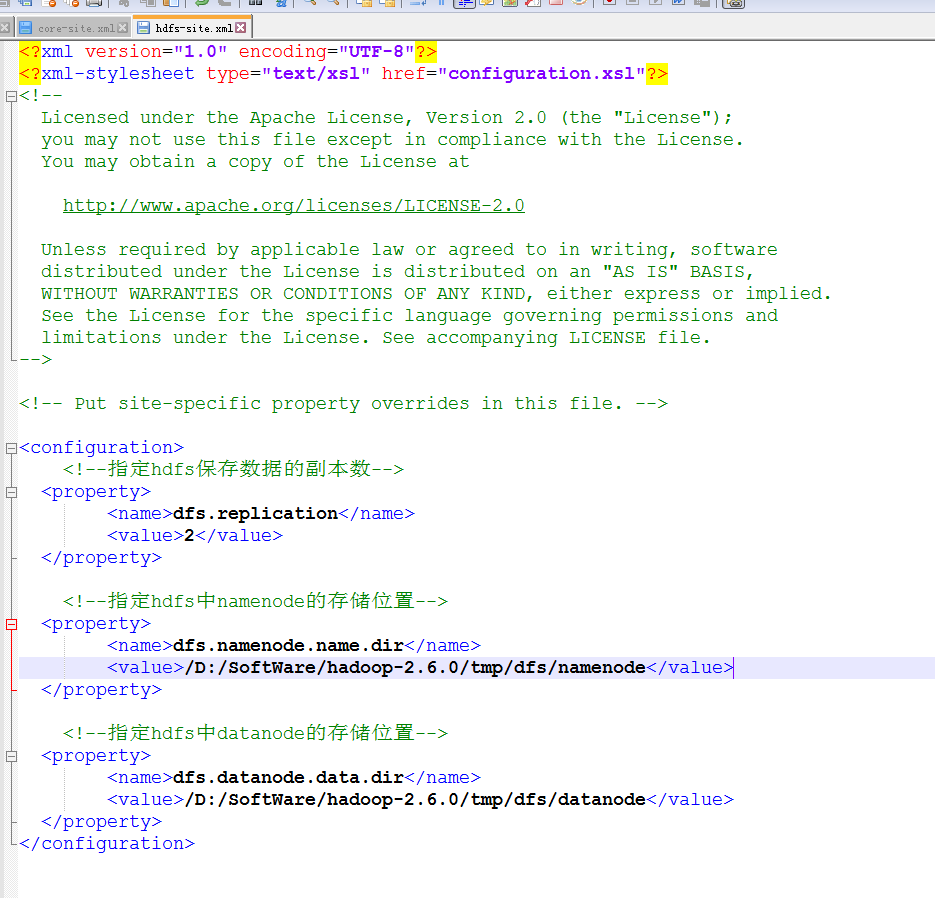
<configuration>
<!--指定hdfs保存数据的副本数-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!--指定hdfs中namenode的存储位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/D:/SoftWare/hadoop-2.6.0/tmp/dfs/namenode</value>
</property>
<!--指定hdfs中datanode的存储位置-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/D:/SoftWare/hadoop-2.6.0/tmp/dfs/datanode</value>
</property>
</configuration>
修改mapred-site.xml
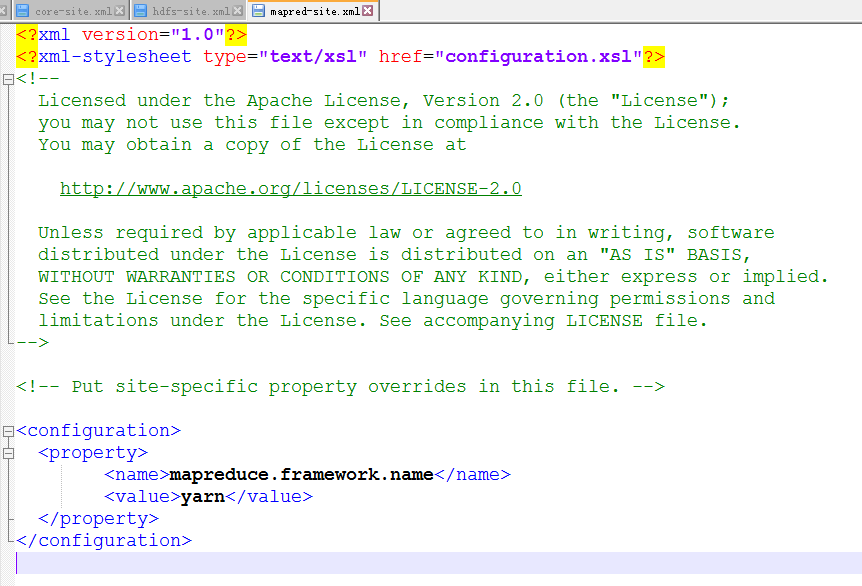
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改yarn-site.xml
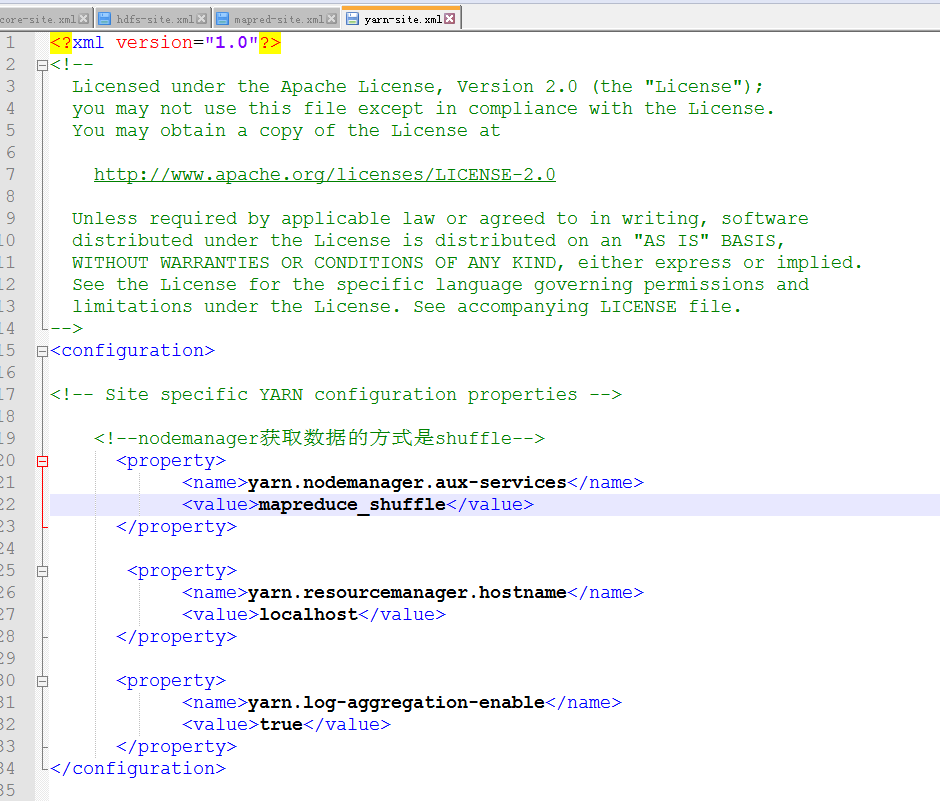
<configuration>
<!-- Site specific YARN configuration properties -->
<!--nodemanager获取数据的方式是shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
</configuration>
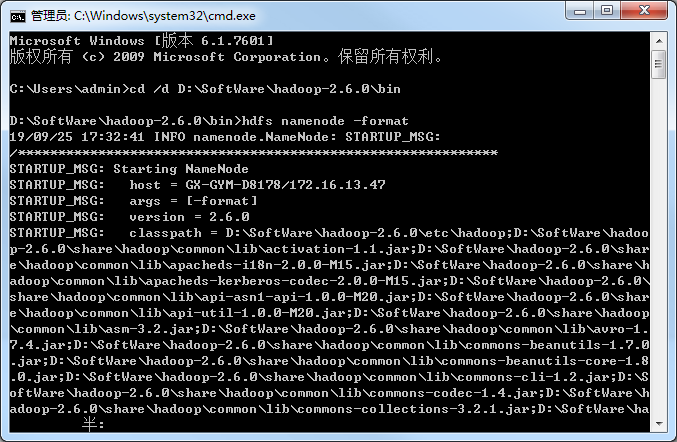
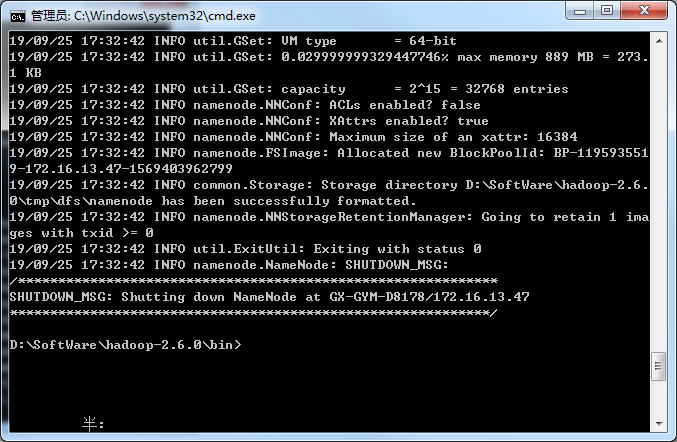
格式化系统文件
hadoop/bin下执行 hdfs namenode -format
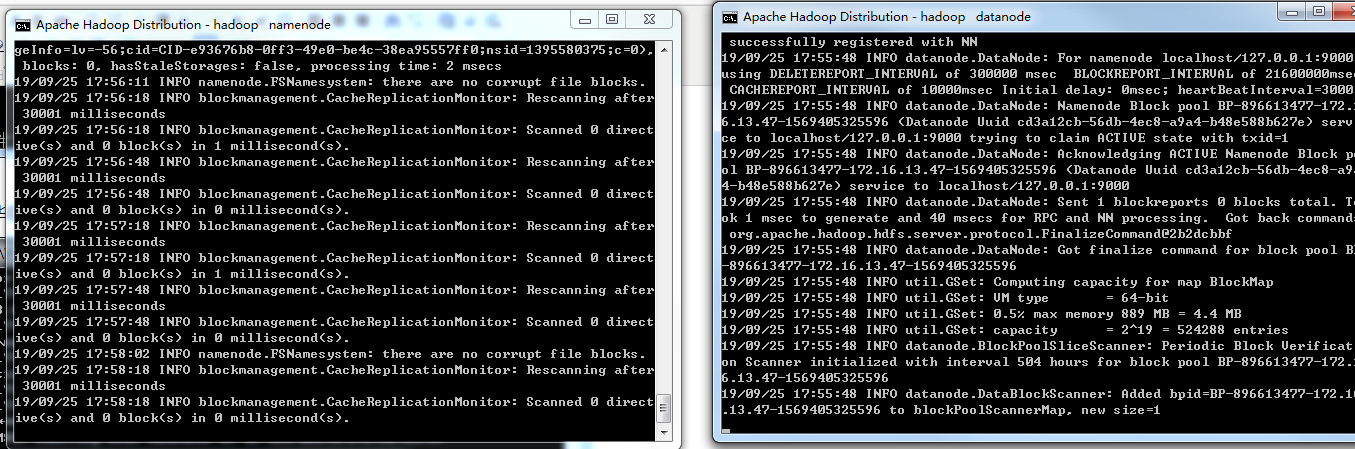
格式化完毕后启动hadoop,到hadoop/sbin下执行 start-dfs启动hadoop
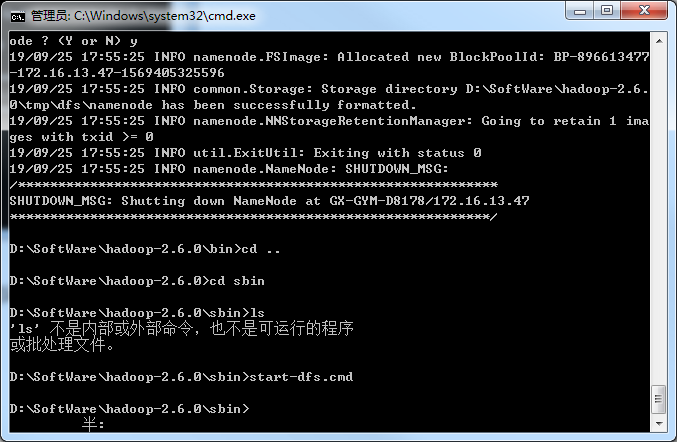
这个时候会自动打开另外两个终端窗口,日志没有报错就行了,
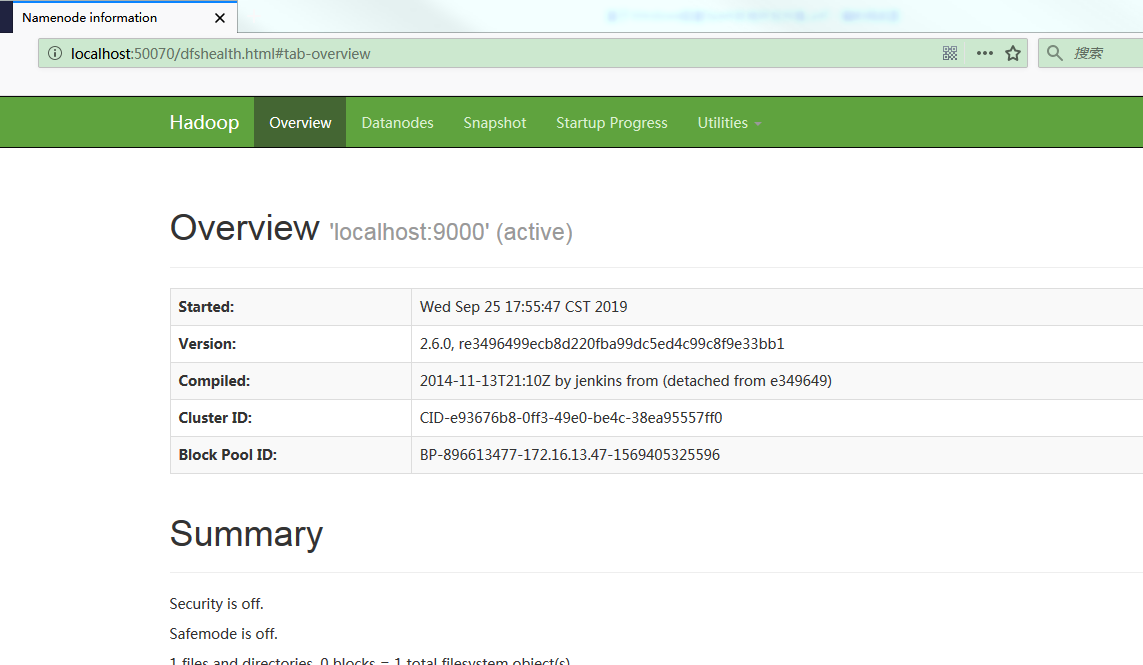
打开浏览器访问 http://localhost:50070
启动yarn
打开浏览器访问 http://localhost:8088
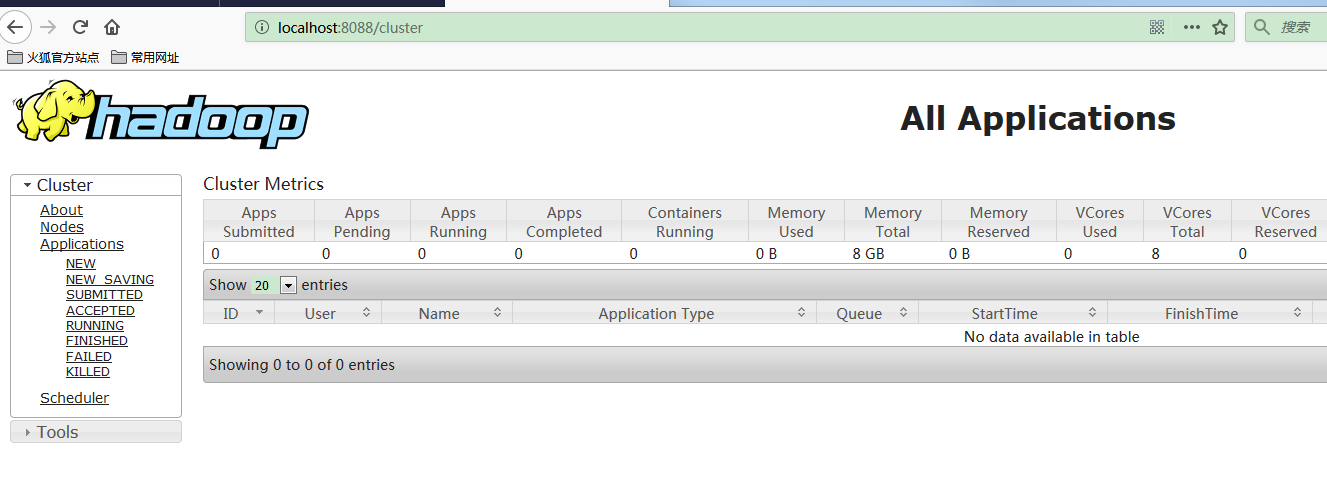
在hdfs创建文件夹

把本地的文本文件上传到hdfs


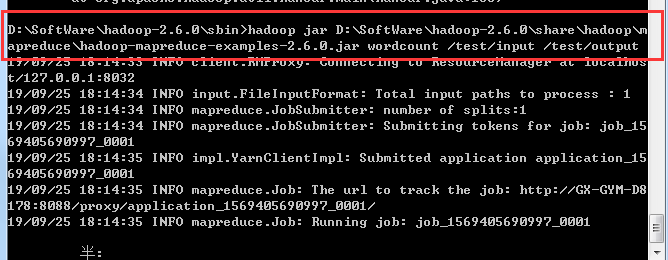
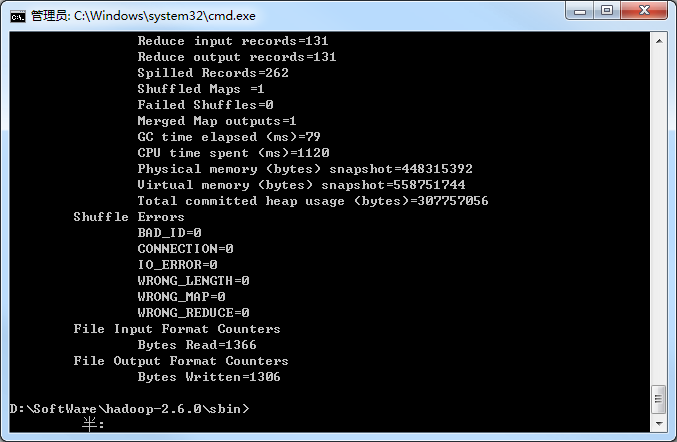
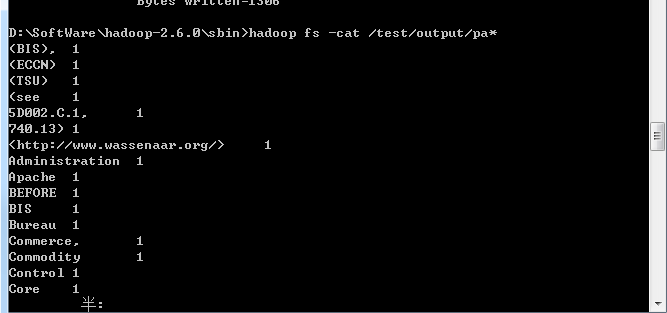
然后运行hadoop 提供的demo,计算单词数
四、安装scala
下载scala的安装包到本地
双击
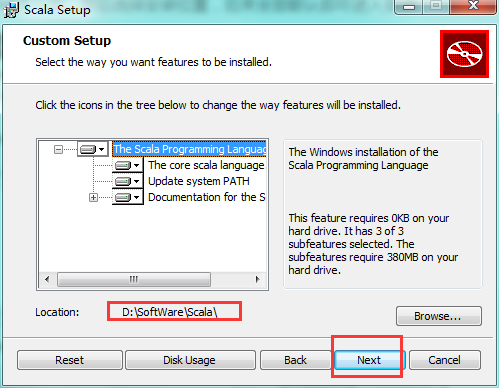
选择安装的路径
配置scala的环境变量
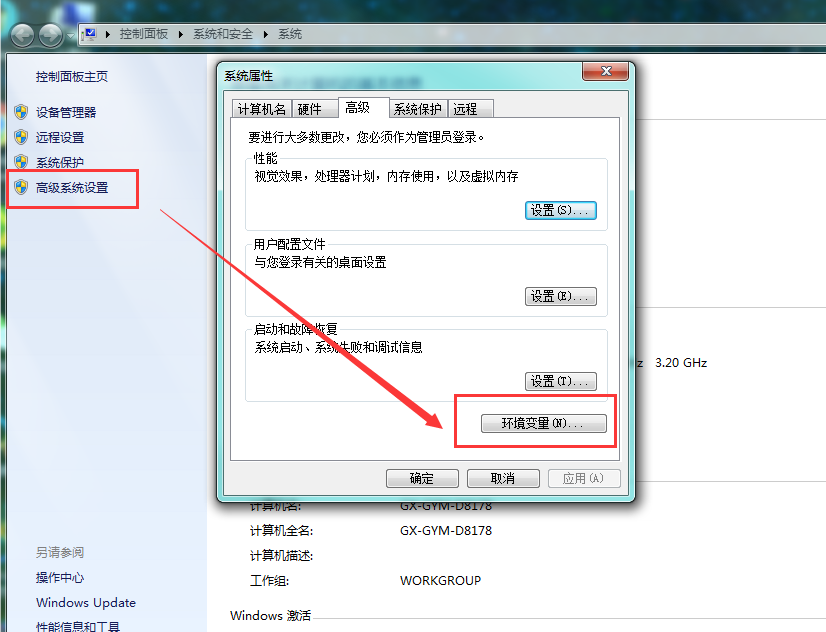
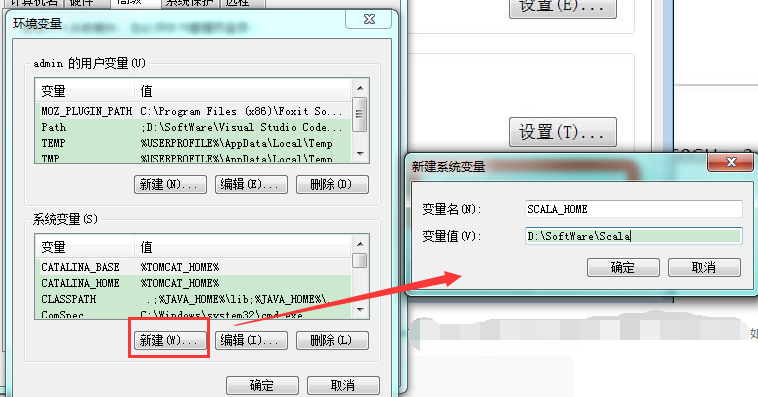
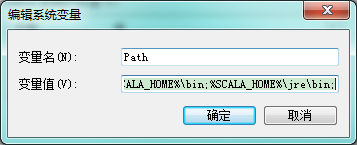
设置 Path 变量:找到系统变量下的"Path"如图,单击编辑。在"变量值"一栏的最前面添加如下的路径: %SCALA_HOME%\bin;%SCALA_HOME%\jre\bin;
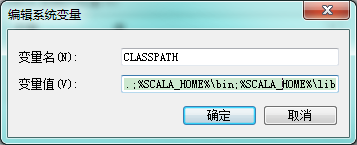
设置 Classpath 变量:找到找到系统变量下的"Classpath"如图,单击编辑,如没有,则单击"新建":
- "变量名":ClassPath
- "变量值":.;%SCALA_HOME%\bin;%SCALA_HOME%\lib\dt.jar;%SCALA_HOME%\lib\tools.jar.;
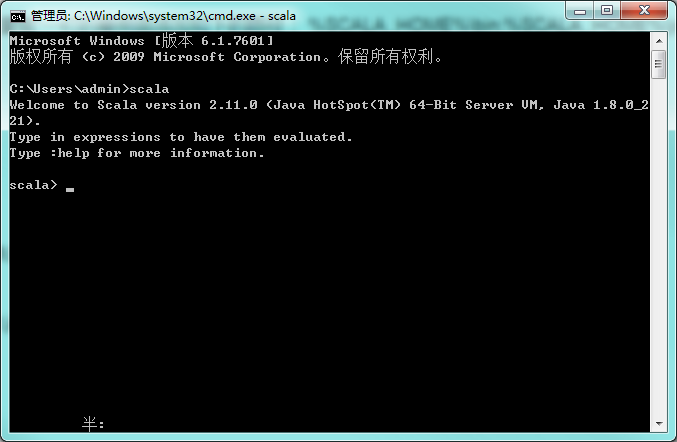
检查环境变量是否设置好了:调出"cmd"检查。单击 【开始】,在输入框中输入cmd,然后"回车",输入 scala,然后回车,如环境变量设置ok,你应该能看到这些信息
五、安装spark
下载安装包

解压到需要安装的路径下
配置spark的环境变量
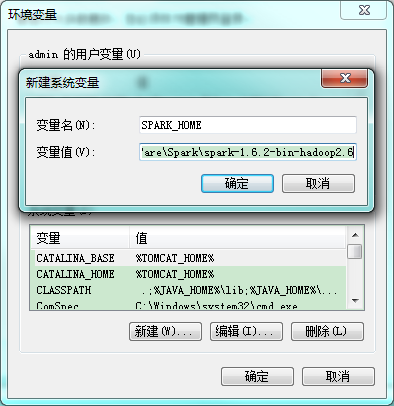
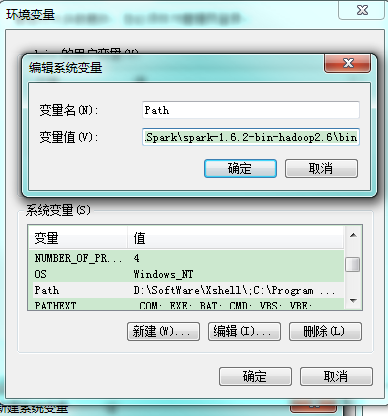
将spark的bin路径添加到path中
cmd输入spark-shell
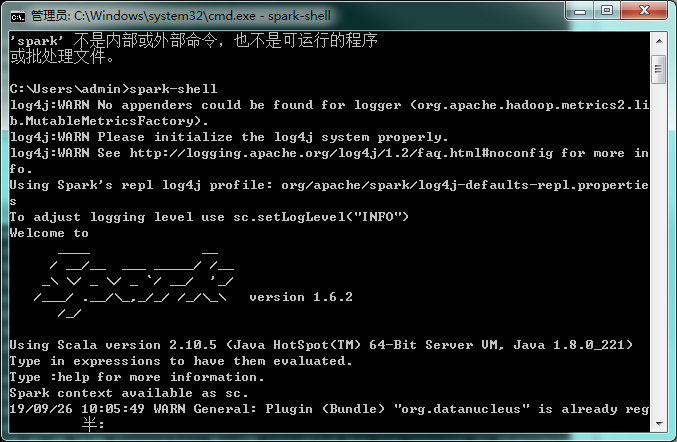
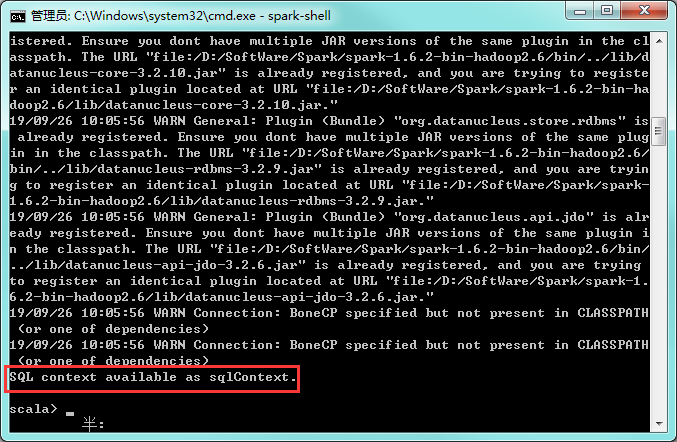
spark已经安装成功了!
六、在IDEA添加scala插件