哈夫曼树的定义:n个叶结点,权分别为w1,w2,···,wn的二叉树中,带权路径长度WPL最小的二叉树叫哈夫曼树(Huffman Tree ), 即:最优二叉树
哈夫曼原理:
1)将字符集中每个字符c出现的频率f(c)作为权值
2)根据给定的权值{w1,w2,···,wn}构造n个二叉树F={T1,T2,···,Tn}, 每个Ti只有一个根结点,权为wi。
3)在F中选取两棵根结点的权值最小的树构成一棵新的二叉树,其根的权值为左右子树根的权值的和。
4)F中删去这两棵树,加上新得的树。
5)重复2)3)直到只剩一棵树。
tips:在实际操作中步骤2其实只选取权值最小的两个构成一个新节点
编码实现:
1:在算法huffmanTree中,编码字符集中每一字符c的频率是f(c)。以f为键值的优先队列Q用在贪心选择时,有效地确定算法当前要合并的2棵具有最小频率的树。
2:一旦2棵具有最小频率的树合并后,产生一棵新树,频率为其合并频率之和,并将新树插入优先队列Q。
3:经过n-1次的合并后,优先队列中只剩下一棵树,即所要求的树T。
代码实现:
#include <bits/stdc++.h>
using namespace std;
const int inf = 0x3f3f3f;
typedef struct HTNode
{
char ch;
unsigned int weight;
unsigned int parent, lchild, rchild;
}HTNode, *HuffmanTree;
HuffmanTree HT;
int w[1024];//字符出现的次数
char str[1024];//存储输入的字符
char out[1024];//输出哈夫曼编码
int n;
//挑选两个出现频路最小且未使用的节点
void Select_Two_HTNode(int pos, int &pos1, int &pos2)
{
int value1, value2;
value1 = value2 = inf;
for(int i = 1; i < pos; ++i)
{
if(HT[i].parent == 0)
{
if(HT[i].weight < value1)
{
int temppos = pos1;
int tempvalue = value1;
pos1 = i;
value1 = HT[i].weight;
if(tempvalue < value2)
{
value2 = tempvalue;
pos2 = temppos;
}
}
else
{
if(HT[i].weight < value2)
{
pos2 = i;
value2 = HT[i].weight;
}
}
}
else
continue;
}
}
void HuffmanCoding()
{
int m = 2 * n - 1; //哈夫曼数节点的数量
HT = (HTNode *)malloc(sizeof(HTNode) * (m + 1));
HuffmanTree p = HT + 1; //第一个节点不用
//初始化已知的n个节点
for(int i = 1; i <= n; ++i, ++p)
{
p->weight = w[i];
p->ch = str[i];
p->parent = p->lchild = p->rchild = 0;
}
//初始化其余节点
for(int i = n + 1; i <= m; ++i, ++p)
p->weight = p->parent = p->lchild = p->rchild = 0;
p = HT + n + 1;//开始合并两个节点
for(int i = n + 1; i <= m; ++i, ++p)
{
int pos1, pos2;
Select_Two_HTNode(i, pos1, pos2);
p->weight = HT[pos1].weight + HT[pos2].weight;
p->lchild = pos1, p->rchild = pos2;
HT[pos1].parent = HT[pos2].parent = i;
}
}
void inPut()
{
scanf("%d", &n);
for(int i = 1; i <= n; ++i)
{
getchar();
scanf("%c %d", &str[i], &w[i]);
}
// for(int i = 1; i <= n; ++i)
// cout << str[i] << " " << w[i];
}
//深度搜索输出
void outPut(int pos, int i)
{
if(HT[pos].lchild == 0 && HT[pos].rchild == 0)
{
printf("字符 %c 的Huffman编码为 %s\n", HT[pos].ch, out);
}
else
{
out[i] = '0';
outPut(HT[pos].lchild, i + 1);
out[i] = '1';
outPut(HT[pos].rchild, i + 1);
strcpy(out + i, "");
}
}
int main()
{
inPut();
HuffmanCoding();
outPut(2 * n - 1, 0);
}测试样例:
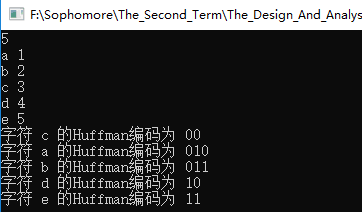
5
a 1
b 2
c 3
d 4
e 5
输出结果
字符 c 的Huffman编码为 00
字符 a 的Huffman编码为 010
字符 b 的Huffman编码为 011
字符 d 的Huffman编码为 10
字符 e 的Huffman编码为 11
例题:
一道例题 Huffman Coding










