Kang_Convolutional_Neural_Networks_2014_CVPR_paper
Convolutional Neural Networks for No-Reference Image Quality Assessment
摘要
在这项工作中,我们描述了一个卷积神经网络(CNN)准确预测图像质量,而不需要参考图像。CNN以图像patch作为输入,在空间域内工作,而不使用之前大多数方法所使用的手工制作的特征。该网络由一个具有最大池和最小池的卷积层、两个完全连接层和一个输出节点组成。在该网络结构中,将特征学习和回归集成到一个优化过程中,从而形成更有效的图像质量估计模型。该方法在LIVE数据集上达到了最好的性能,在跨数据集实验中显示了良好的泛化能力。对局部失真图像的进一步实验证明了我们的CNN具有估计局部质量的能力,这在之前的文献中很少报道。
1. Introduction
贡献一 就我们所知,CNN还没有被用于一般用途的NR-IQA。主要原因是原始的CNN不是为了捕捉图像质量特征而设计的。在目标识别领域,好的特征通常编码局部不变的部分,但对于NR-IQA任务,好的特征应该能够捕获NSS属性。NR-IQA与物体识别的区别使得CNN的应用具有非直观性。我们的贡献之一是改进了网络结构,使其能够更有效地学习图像质量特征,更准确地估计图像质量
贡献二 我们的论文的另一个贡献是,我们提出了一个新的框架,允许学习和预测图像质量的局部区域。以前的方法通常是在整个图像上累积特征,以获得统计数据来估计整体质量,很少显示出估计局部质量的能力,除了[18]中的一个简单例子。相比之下,我们的方法可以在小块(如32×32)上估计质量。局部质量估计对于图像去噪或重建问题很重要,只在需要的地方应用增强。
2. Related Work
3. CNN for NR-IQA

对比度归一化
局部对比度归一化(区别于全局对比度归一化)较小的归一化窗口可以提升性能
池化(最大池化、最小池化)
最小池化(在最大池化的基础上)性能提升
Relu
注意ReLUs只允许非负信号通过。由于这个特性,我们不使用ReLUs,而是在卷积层和池层上使用线性神经元(恒等变换)。原因是最小池通常产生负值,我们不希望阻塞这些负值池输出中的信息。
学习
划分成32*32的小块, 把原始图像的标签分配给每个小块。把原始图像分为小块可以增加数据量。
4. Experiment
4.1数据集
两个数据集。
(1) LIVE[15]:来自29张参考图像的779张失真图像,包括JP2k压缩(JP2k)、JPEG压缩(JPEG)、白高斯(WN)、高斯模糊(blur)和快速衰落(FF)五种不同的失真。
(2) TID2008[12]: 1700张具有17种不同畸变的图像,来自4个退化级别的25张参考图像。在我们的实验中,我们只考虑了四种常见的实时数据集共有的失真,即JP2k, JPEG, WN和模糊。每幅图像与一个范围为[0,9]的平均意见评分(MOS)相关联。
评价:采用两个指标来评价IQA算法的性能:1)线性相关系数(LCC)和2)Spearman秩序相关系数(SROCC)。LCC度量两个量之间的线性依赖关系,SROCC度量一个量如何被描述为另一个量的单调函数。我们报告了从100次训练测试迭代中获得的结果,在每次迭代中,我们随机选择60%的参考图像和它们的失真版本作为训练集,20%作为验证集,其余20%作为测试集。
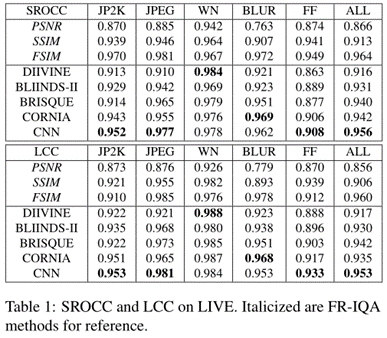
4.2 evaluate on LIVE
我们直观地检查了所学的卷积核,发现只有少数核具有明显的与失真类型相关的结构。图2分别显示了在JPEG和所有扭曲上学习到的内核。我们可以看到,块状模式是从JPEG中学习的,而一些模糊模式存在于从所有扭曲中学习的内核中。这并不奇怪,CNN学习的内核往往是噪声模式,而不是表现出与某些扭曲相关的强结构,如CORNIA[20]。这是因为CORNIA的feature learning是无监督的,属于生成模型,而我们的CNN是有监督训练的,学习discriminative feature。

4.3 参数的影响
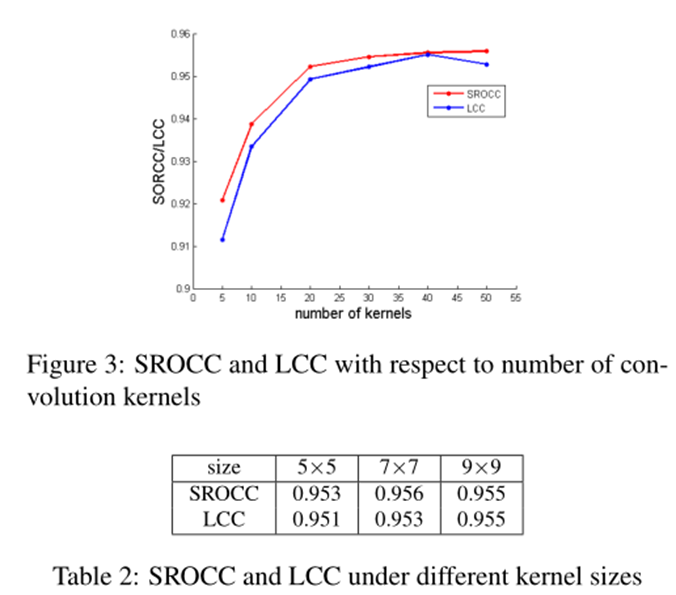
卷积核的数量
图3显示了性能如何随着卷积核的数量而变化。毫无疑问,过滤器的数量会显著影响性能。一般来说,使用更多的内核会带来更好的性能。但当内核数量超过40时,性能几乎没有提高。
卷积核的大小
表2显示了性能随内核大小的变化。我们可以从图2中看到,所有测试的内核大小都显示出类似的性能。该网络对内核大小不敏感。
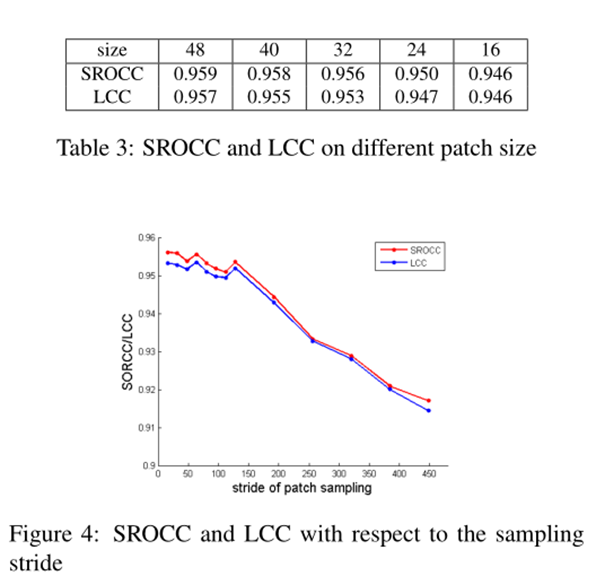
块大小
从表3可以看出,更大的补丁会带来更好的性能。随着补丁大小的增加,块大小从8至48性能略有提高。然而,较大的patch不仅会增加处理时间,还会降低空间质量分辨率。因此,我们更喜欢最小的补丁,以产生最先进的性能状态
采样步幅
为了观察补丁的数量如何影响总体性能,我们固定补丁的大小并改变步幅。改变步幅并不会改变网络的结构。为了简化100次迭代实验的每一次迭代,我们使用在stride 32时训练的相同模型,并使用不同的步幅值进行测试。图4显示了与步幅有关的性能变化。较大的步幅通常会导致较低的性能,因为用于总体估计的图像信息较少。但是值得注意的是,即使stride增加到128,仍然保持了art性能的状态,这大致相当于原始patch数量的1/16。这一结果与整个图像中实时数据的失真大致相同这一事实相一致,也表明我们的CNN能够准确预测小块图像的质量分数
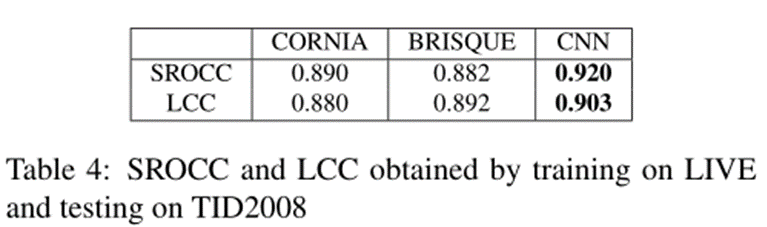
4.4 Cross Dataset Test
4.5 Local Quality Estimation

我们的CNN测量小图像块上的质量,所以它可以用来检测低质量/高质量的局部区域,以及给整个图像一个全局评分。我们从TID 2008 (LIVE中没有收录)中选取一幅未失真的参考图像,并将其分为四个垂直部分。然后我们用三个不同退化级别的扭曲版本替换第二到第四部分。以这种方式生成四幅合成图像,每一种类型的扭曲,包括WN,模糊,JPEG和JP2K。然后我们对这些合成图像执行局部质量估计使用我们的模型在现场训练。我们以8步扫描16×16个patch,并将预测的分数归一化到[0,255]范围内进行可视化。图5显示了合成图像上的估计质量地图。我们可以看到,我们的模型很好地区分了每个合成图像的干净部分和扭曲部分。

为了更好地检验我们模型的局部质量估计能力,我们考虑了TID2008中之前实验中未使用的几种类型的失真,并发现了三种只会影响局部区域的类型:JPEG传输、JPEG2000传输和块状失真。再次从TID2008中,我们挑选了一些没有被LIVE分享的图像,并使用上述三种扭曲对它们的扭曲版本进行测试。图6显示了局部质量评估结果。我们发现,我们的模型定位的失真区域有合理的精度,结果基本符合人类的判断。值得注意的是,我们的模型能够很好地定位块的扭曲,尽管这种类型的扭曲并不包含在训练类型中。
5. Conclusion
我们开发了一个CNN无参考图像质量评估。我们的算法结合了特征学习和回归作为一个完整的优化过程,这使我们能够使用现代训练技术来提高性能。我们的算法生成与人类感知良好相关的图像质量预测,并在标准IQA数据集上达到最佳的性能。此外,我们证明了我们的算法可以在局部区域估计质量,这在以往的文献中很少报道,但在图像重建或增强方面有很多潜在的应用。










