
结论:
执行效果上:
- count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL
- count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL
- count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计。
执行效率上:
- 列名为主键,count(列名)会比count(1)快 (待商榷)
- 列名不为主键,count(1)会比count(列名)快 (确定)
- 如果表多个列并且没有主键,则 count(1) 的执行效率优于 count(*) (待商榷)
- 如果有主键,则 select count(主键)的执行效率是最优的 (待商榷)
- 如果表只有一个字段,则 select count(*)最优。(待商榷)
测试:
建表
create database test;
use test;
create table t(id int primary key , age int , name varchar(18) );创建存储过程
create procedure sp_name()
begin
declare i int default 0;
start transaction;
while i<10000000 do
insert into t(id,age,name)values(i,i,'zhangsan');
set i=i+1;
end while;
commit;
end;调用存储过程
call sp_name();删除存储过程
drop procedure sp_name;注意事项
1)不能在一个存储过程中删除另一个存储过程,只能调用另一个存储过程
使用示例:
create procedure sp_name()
begin
declare i int default 0;
start transaction;
while i<10000000 do
insert into t(id,age,name)values(i,i,'zhangsan');
set i=i+1;
end while;
commit;
end;
Query OK, 0 rows affected
mysql> call sp_name();
Query OK, 0 rows affected
mysql> select count(*) from t;
+----------+
| count(*) |
+----------+
| 10000000 |
+----------+
1 row in set验证执行效果
cout(*)和count(1) 没区别,但是cout(列名) 不统计为 null 的
select count(name) from t;
+-------------+
| count(name) |
+-------------+
| 9999998 |
+-------------+
1 row in set
mysql> select count(*) from t;
+----------+
| count(*) |
+----------+
| 10000000 |
+----------+
1 row in set
mysql> select count(1) from t;
+----------+
| count(1) |
+----------+
| 10000000 |
+----------+
1 row in set验证执行效率
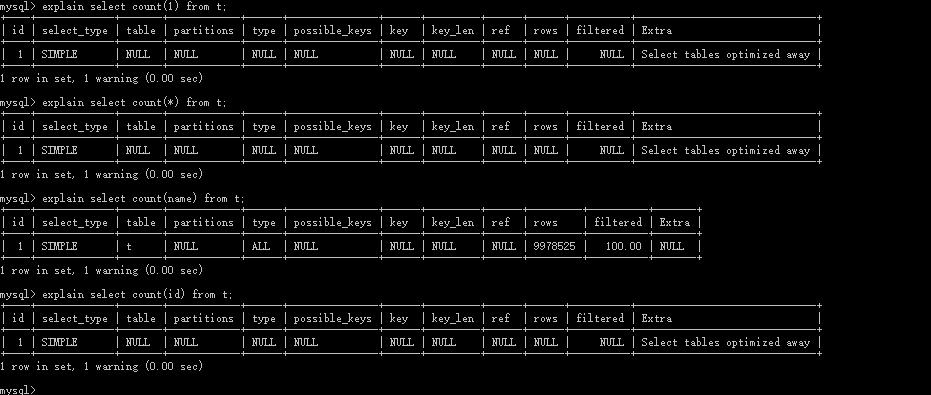
执行时间
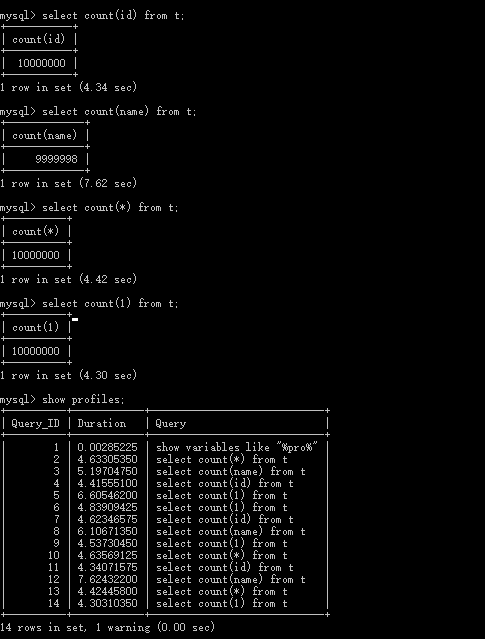
分析一下 执行计划,然后看下执行时间, 无条件查询情况下
可以得到结论
count(主键) count(*) count(1) 效率远高于 count(非主键列)
- count(*) count(1), count(列,主键) 执行计划基本上是一样的
- count(列名(非主键)) 比如 count*name 的执行计划 type = All 是进行的全表扫描,而count(*) count(1), count(列,主键) 的type 是null,执行时甚至不用访问表或索引
MySQL5.7文档中有一段话:
InnoDB handles SELECT COUNT(*) and SELECT COUNT(1) operations in the same way. There is no performance difference.
For MyISAM tables, COUNT(*) is optimized to return very quickly if the SELECT retrieves from one table, no other columns are retrieved, and there is no WHERE clause.This optimization only applies to MyISAM tables, because an exact row count is stored for this storage engine and can be accessed very quickly. COUNT(1) is only subject to the same optimization if the first column is defined as NOT NULL.
InnoDB以同样的方式处理SELECT COUNT(*)和SELECT COUNT(1)操作。两者没有性能差异。
对于MyISAM表,如果SELECT从一个表中检索,没有检索其他列,也没有WHERE子句,那么COUNT(*)被优化为快速返回。这种优化只适用于MyISAM表,因为这个存储引擎存储了准确的行数,并且可以非常快速地访问。COUNT(1)只有在第一列被定义为NOT NULL时才进行与COUNT(*)相同的优化
欢迎关注











