文章目录
- 前言
- Abstract (摘要)
- Introduction (引言)
- Related Work (文献综述)
- Architectural Choices(架构选择)
- 实验结果(Experimental Results)
- 思考和总结
前言
今天看一下inceptionV4,之前的版本:
- inceptionV1 & GoogleNet 精读
- inceptionV2 & BN 精读
- inceptionV3 精读
看这篇论文之前建议看一下inception之前的几个版本,以及ResNet论文。
- ResNet 精读+复现
本篇论文主要介绍inceptionV3的改进版本inceptionV4,以及将inception和resnet结合的俩版本 inception-resnetV1和inception-resnetV2。
Abstract (摘要)
摘要部分作者主要说,现如今深层的神经网络已经变成了CV领域的主流,已经有inception这样的高效结构,并且在写这篇论文的时候,Resnet横空出世,作者考虑是否可以将inception和ResNet相结合,作者在后续实验中证明,残差连接可以显著的加快inception的训练速度,且准确率也比没有残差模块的网络高一点,设计了三个模型,有残差连接的Inception-ResNetV1和V2版本 还有一个没有残差连接的InceptionV4。
在摘要的最后作者发现一个方法,将残差输出缩小(乘以一个缩小因子),可以防止网络不稳定现象。
Introduction (引言)
这一章介绍行业现状,就提了一堆的CV领域产业,这些产业都是可以得益于图像分类系统的发展。
然后提到残差连接,残差连接在深层网络中非常重要,而他们的inception模块堆叠的网络往往都比较深,然后作者就想着能不能将两者结合,就提出一个方法,将concatennate合并层替换成残差加法merge层。
残差连接没有引入额外的参数,但又加快了训练,可以让较深的inception得益。
后面就是作者说他设计的几个模型,有残差的和没有残差的在计算量复杂度上基本保持一致。
引言的最后作者提到了一个结论: 对于single frame(对输入图片不做处理,直接整个喂给模型) 多模型融合对比单模型并没有很大的性能提升。
Related Work (文献综述)
这一章开头又是介绍了一下当时前人的研究工作,并且对 ‘残差连接是深层网络所必不可少的’ 观点提出了质疑,这块作者质疑就是打个铺垫把,方便后面提出他自己的没有残差连接的inceptionV4。
随后作者给出的两张图,顺便可以回顾一下ResNet结构。
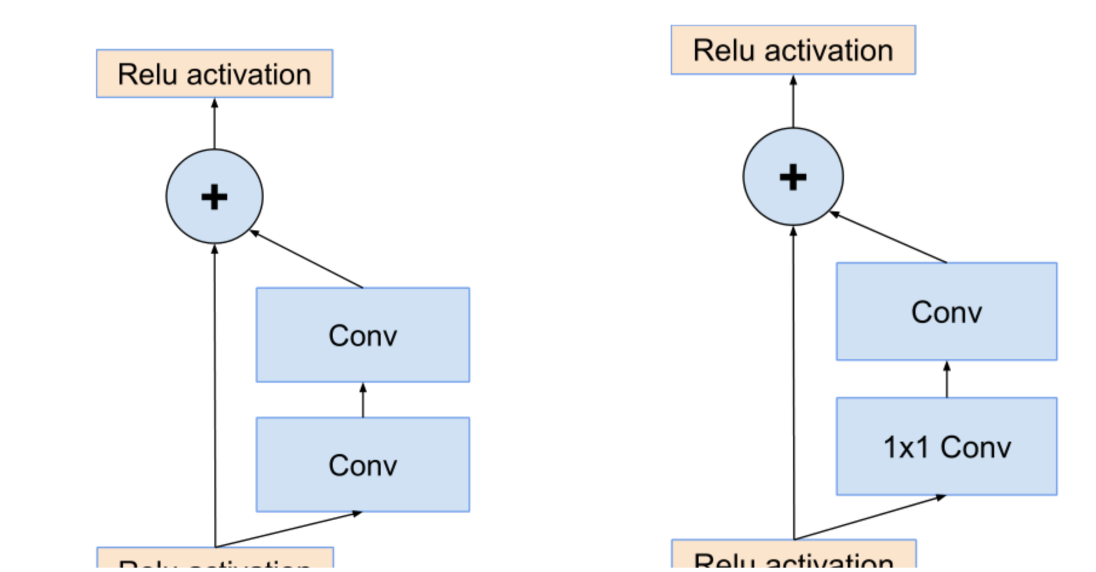
左边的图 就是原生的残差结构,输入进来的数据分成两路,一路不变,另一路去卷积训练,最后的输出就是两者的相加。
而右边这个图是对左边残差结构的优化,他在卷积之前使用 1 * 1卷积进行降维,减少了计算量和参数量。
Architectural Choices(架构选择)
本章节主要介绍了带残差的inception和不带残差的inception。
不带残差的inception:
因为之前没有tensorflow 所以在调试网络参数的时候需要每个inception模块内的每一个小网络都要很谨慎,因为内存有限,当出现了tf之后,因为tf有很好的内存管理机制,所以可以不用那么谨慎的对待每一个参数了,就用整个网络整体的去调整,
带残差的inception:
inception模块处理之后,使用不带激活函数的1 * 1 的卷积进行升维,扩展维度和通道数用来匹配输入维度,因为残差结构里最后需要相加嘛,所以维度和通道数要匹配上。
一般情况下BN应用在每一层的后面,但是在这里作者不在残差后面应用BN,只在传统层后面用BN,怕内存爆炸。(这里简单回顾一下 BN需要记录每一个神经元的方差和均值,所以会占用大量的内存)
所用模块架构图:
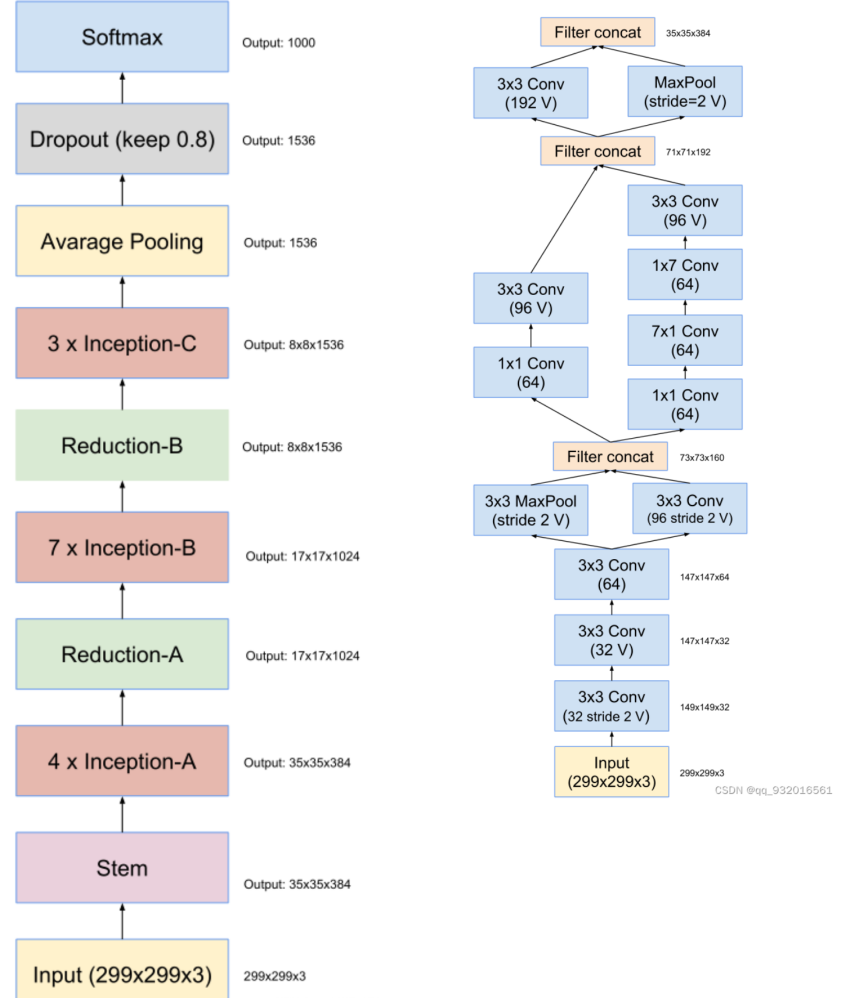
可以看到右边这个图 也就是左图中的stem展开的结构,主要工作就是长宽通道的变换,从299 *299 *3 -> 35 * 35 *384。
其中用到的各种inception模块:
inception-A模块:
5 * 5卷积 -> 3 * 3卷积

inception-B模块:
7 * 7 卷积 -> 7 * 1 和 1 * 7
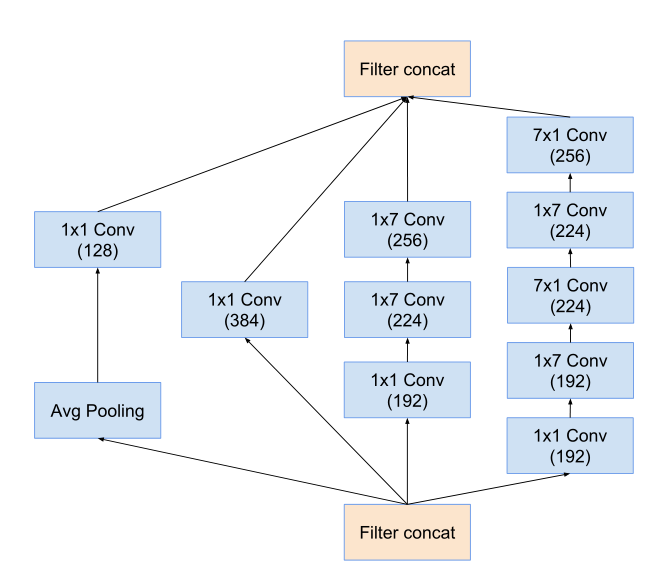
inception-C模块:
在宽度进行不对称卷积 扩展维度 通道数。
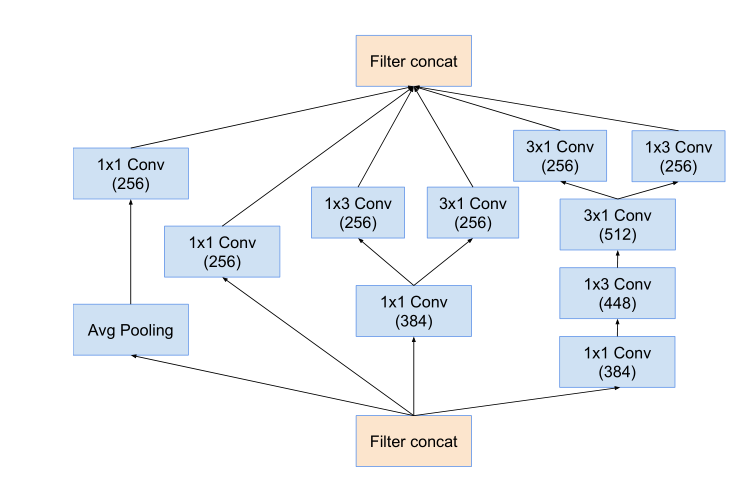
Reduction-B模块:
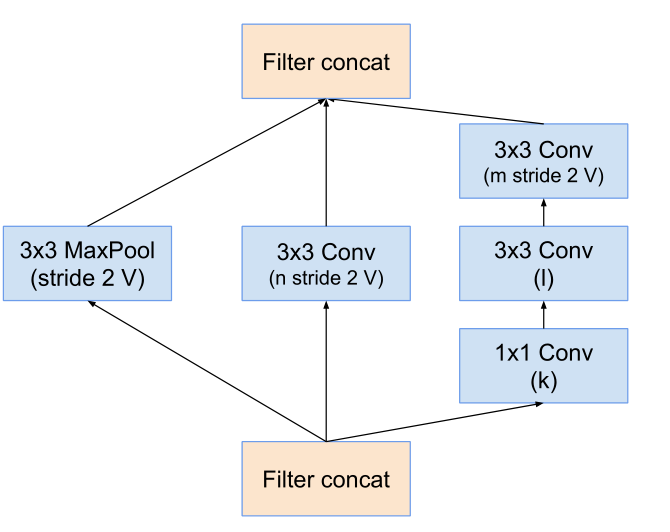
Reduction-C模块:
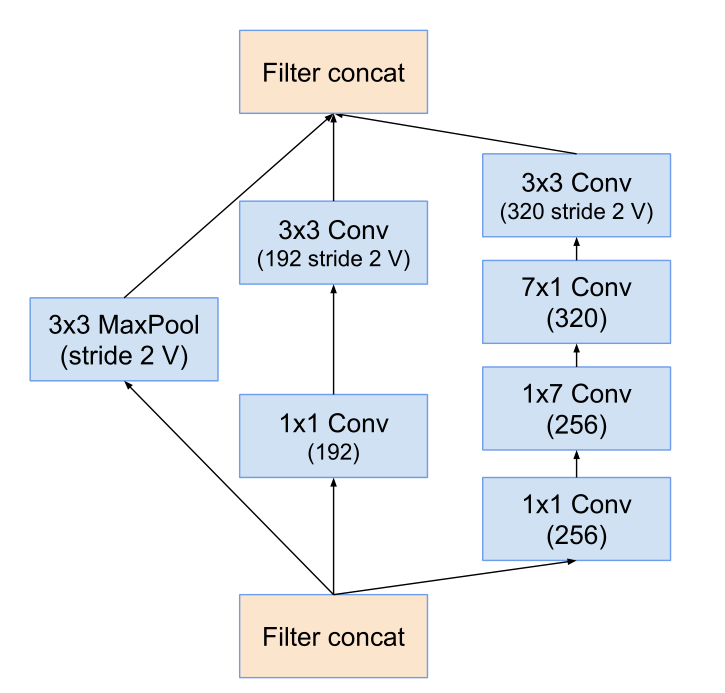
下面这个是Inception-Resnet V1的:
左起依次 inceptionA -> inceptionB -> inceptionC:
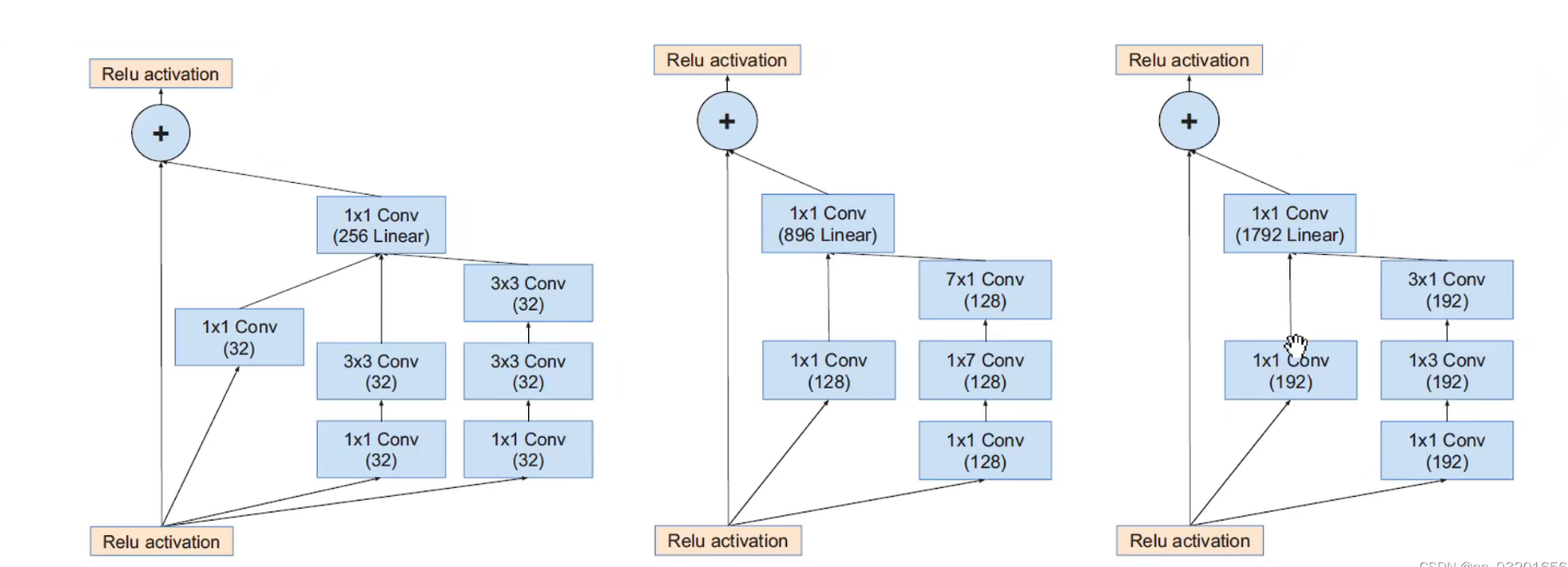
下面这个是Inception-Resnet V2的:
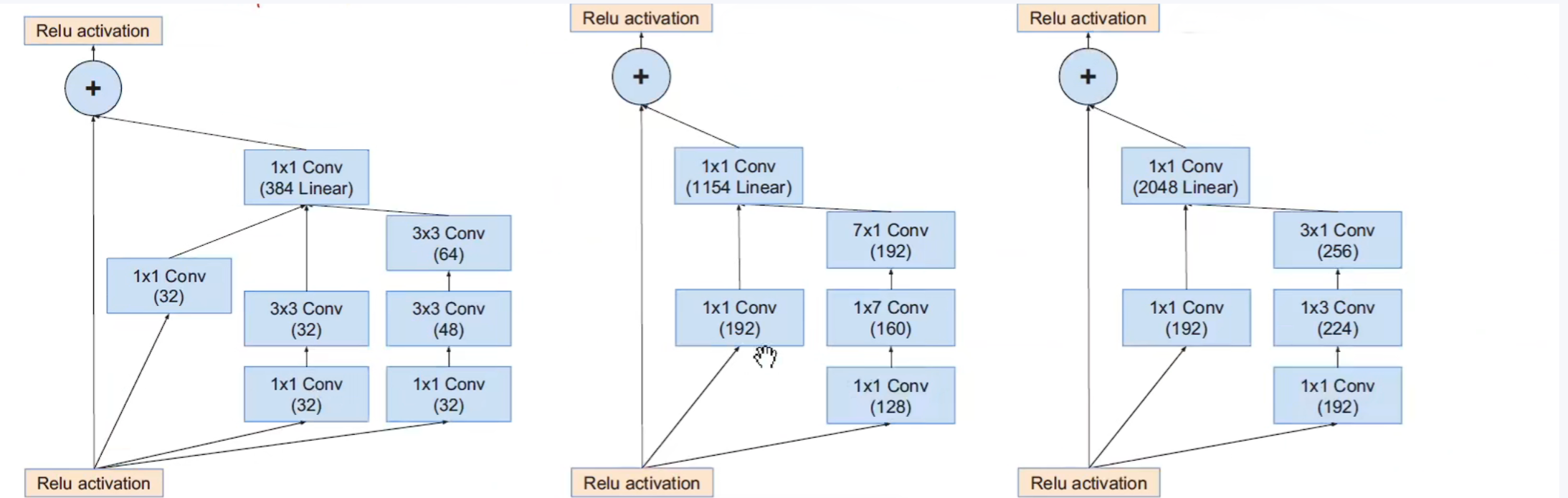
左边是inception-Resnet V1 和V2的主干网络,右边是 inception-Resnet V1的stem结构展开图。

残差块幅度(Scaling of the Residuals)
这一章主要介绍如何对残差块输出的幅度进行减小。
若卷积核的个数超过1000个,则残差模块会变得不稳定,这也在开头提到过,就是在训练早期的时候会有一些块‘死亡’,这里作者说死亡应该是其神经元的输出是0。在最后的全局平均池化层之前 feature map里有很多0,且作者说加入了BN和很小的lr后仍然不能解决这个问题。
后面作者提出了这个问题的解决办法,就是在残差映射做加法融合之前先乘以幅度缩小系数,该系数在0.1-0.3之间,层数越深该系数越小。
后一段作者说何凯明的那篇论文就是ResNet最开始的那篇论文中也有这种不稳定现象,但是他们的解决办法是先用超小学习率热身一边,然后再用大学习率,不过本篇论文作者打脸了这种方法,通过实验证明了他的无效,说明了自己的缩小幅度系数比较可靠。
幅度缩小方法结构图:

可以看到在inception之后经历了一个幅度缩小步骤然后再相加得到结果。
其实也就是输入进来的数据是前面很多层网络学习后的结果,如果我们想修改这些结果,则乘以一个缩小系数,让他小幅度的修改学习,一点一点的调整,防止网络训练不稳定的情况出现。
实验结果(Experimental Results)
后面作者介绍了一下他模型的超参数,其中基本都和inceptionV3一样,然后说了一下实验结果,总之就是非常好~
作者说他在测试集上表现不错,说明模型没有过拟合,然后还强调只提交了两次,一次是带BN的,一次不带。我在查资料的时候看到一个博主说这一块的一个小插曲就是,百度参加了2015年的 imagenet竞赛,但是提交的次数太多被判无效了(恶意刷榜 或者在猜验证集的数据?),我笑喷了,这果然很百度~~~~(我觉得我这篇文章可能会被和谐~~)。
实验结论:
- inceptionV3 和inception-Resnet V1的准确率差不多,但有残差模块的收敛更快。
- inceptionV4 和inception-ResnetV2的准确率差不多,同样的有残差模块的收敛更快。
最终性能 :
作者最后的也是用了多模型融合(包含144数据增强)的技术,3个inception-ResnetV2 加上1个inceptionV4 ,top-1 :16.4% top-5 :3.1%。
思考和总结
含有ResNet的模型为什么可以加速收敛?
实验中的Crops144怎么来的?
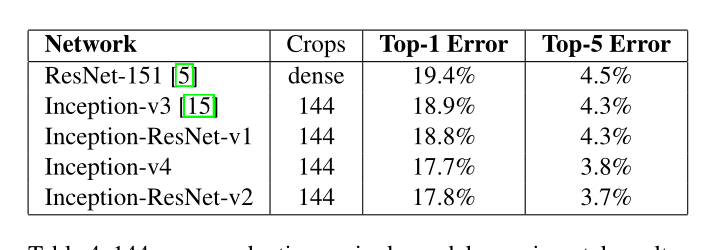
这是在实验那一章放出来的一张图,其中的crops是144,就是将一张图变成144张图,相当于数据增强,这个技术在googlenet 也就是inceptionV1的那篇论文里头出现的,我记着是吧哈哈,而且我在当时复现论文的时候也所过这个144是怎么来的,他们是为了打比赛搞的这种数据增强技术。
对于一张输入的 224 * 224 的图片进行如下操作:(224是Googlenet里,该论文中是299 * 299)
- 将原图缩放为256 288 320 352的四个尺度。
- 每个尺度裁剪出 左中右 或 上中下 的三张图。
- 每个图取四个角或者中央的 224 * 224 尺寸的五张图片。
- 取其水平镜像。
4 * 3 * 6 * 2 = 144个图片,最后融合144个图的结果作为这一张原图的最终结果。相当于为了准确率牺牲了大量的计算力。
小总结
- 对原残差模块的改造,卷积时先加入1 * 1的卷积降维减少运算量。
- 残差结构对于深层网络并非必不可少,比如inceptionV4。
- 通过实验表明之前的使用两段训练(小→大学习率)的方法并不能很好的解决残差块不稳定现象。
- 提出了缩小因子解决残差块的不稳定现象(在inception之后先乘以缩小因子,然后和恒等映射相加)。
- 残差结构对于网络训练的加速效果还不错。
- 最终Inception-ResNetV2模型效果最好。









