Storm提出了几个新的概念,理解这些概念对于学习Storm非常重要。Storm中核心概念如下:
1)Tuple:由一组可序列化的元素构成,每个元素可以是任意类型,包括Java原生类型、String、byte[]、自定义类型(必须是可序列化的)等。
2)Stream:无限的Tuple序列形成一个Stream。每个Stream由一个唯一ID、一个对Tuple中元素命名的Schema以及无限Tuple构成。
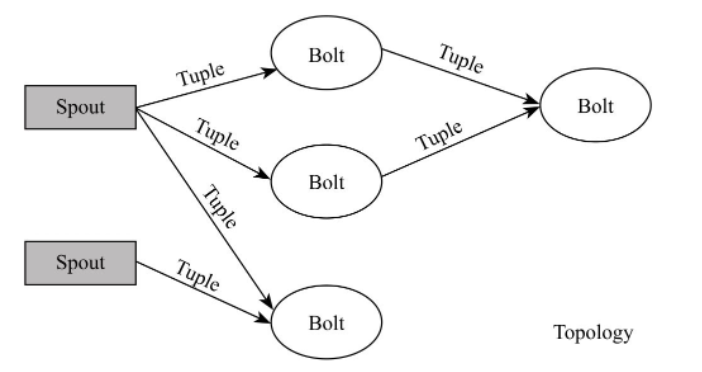
3)Topology:Storm中的用户应用程序被称为“Topology”,这类似于MapReduce中的“Job”。它是由一系列Spout和Blot构成的DAG,其中每个点表示一个Spout或Blot,每个边表示Tuple流动方向。
4)Spout:Stream的数据源,它通常从外部系统(比如消息队列)中读取数据,并发射到Topology中。Spout可将数据(Tuple)发射到一个或多个Stream中。
5)Bolt:消息处理逻辑,可以是对收到的消息的任意处理逻辑,包括过滤、聚集、与外部数据库通信、消息转换等。Blot可进一步将产生的数据(Tuple)发射到一个或多个Stream中。
在一个Topology中,每个Spout或Blot通常由多个Task构成,同一个Spout或Blot中的Task之间相互独立,它们可以并行执行,如图13-4所示。可类比MapReduce Job理解:一个MapReduce Job可看作一个两阶段的DAG,其中Map阶段可分解成多个Map Task, Reduce阶段可分解成多个Reduce Task,相比之下,Storm Topology是一个更加通用的DAG,可以有多个Spout和Blot阶段,每个阶段可进一步分解成多个Task。
6)Stream Grouping:Stream Grouping决定了Topology中Tuple在不同Task之间是的传递方式。Storm主要提供了多种Stream Grouping实现,常用的有:
- Shuffle Grouping:随机化的轮训方式,即Task产生的Tuple将采用轮训方式发送给下一类组件的Task。
- LocalOrShuffle Grouping:经优化的Shuffle Grouping实现,它使得同一Worker内部的Task优先将Tuple传递给同Worker的其他Task。
- Fields Grouping:某个字段值相同的Tuple将被发送给同一个Task,类似于MapReduce或Spark中的Shuffl e实现。
一个Storm集群由三类组件构成:Nimbus、Supervisor和ZooKeeper,它们的功能如下:
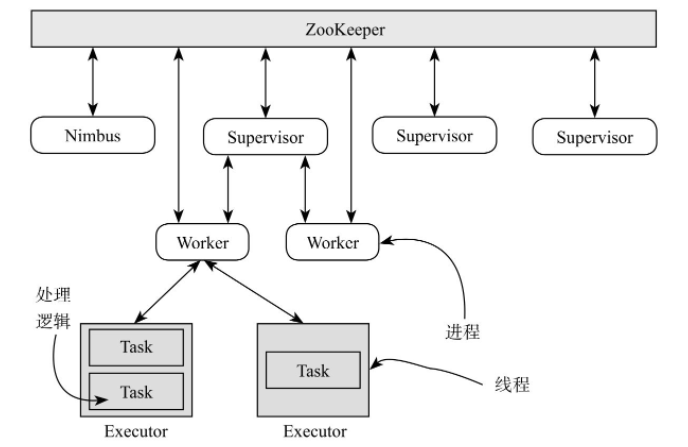
1)Nimbus:集群的管理和调度组件,通常只有一个,负责代码分发、任务调度、故障监控及容错(重新将失败的任务调度到其他机器上)等。Nimbus是无状态的,可通过“kill -9”杀掉它而不影响正常应用程序的运行。
2)Supervisor:计算组件,通常有多个,负责执行实际的计算任务根据Nimbus指令启动或停止Worker进程。与Nimbus类似,Supervisor也是无状态。
- Worker:实际的计算进程,每个Supervisor可启动多个Worker进程(需静态为每个Worker分配一个固定端口号),但每个Worker只属于特定的某个Topology。
- Executor:每个Worker内部可启动多个Executor线程,以运行实际的用户逻辑代码(Task)。每个Executor可以运行同类组件(同一个Topology内的Spout或Bolt)中一个或多个Task。
- Task:用户逻辑代码,由Executor线程根据上下文调用对应的Task计算逻辑。
3)ZooKeeper:Nimbus与Supervisor之间的协调组件,存储状态信息和运行时统计信息,具体包括:
- Supervisor的注册与发现,监控失败的Supervisor。
- Worker通过ZooKeeper向Nimbus发送包含Executor运行状态的心跳信息 。
- Supervisor通过ZooKeeper向Nimbus发送包含自己最新状态的心跳信息。










