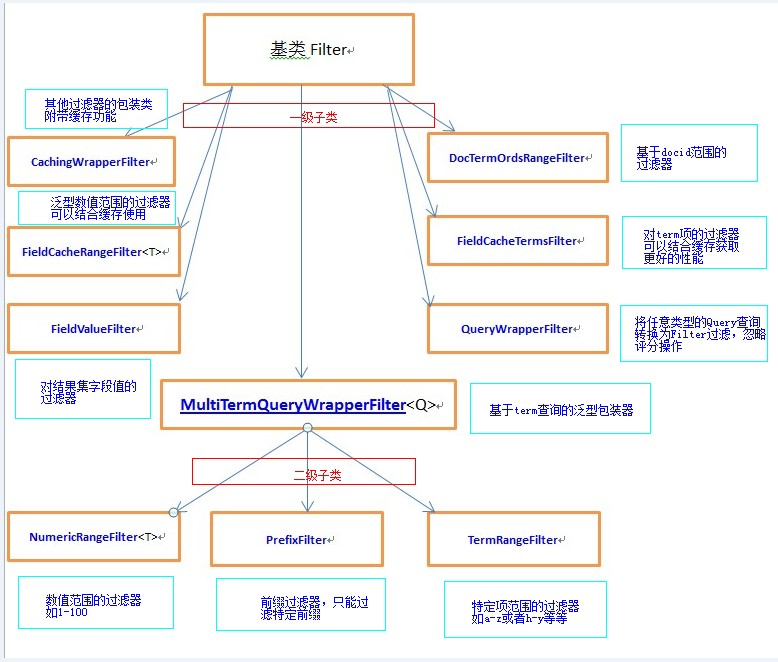
Lucene里面有关于Filter的整体知识
下面,我们来看下具体的在代码里怎么实现,先来看下我们的测试数据 Java代码

1. id score bookname ename type price date
2. 1 1 飘渺之旅 pmzl 小说 52.23 201005
3. 2 1 三国演义 sgyy 小说 36.13 201207
4. 3 1 数据库实战 sjksz 技术 77.13 200811
5. 4 1 编程宝典 bcbd 技术 100.3 200501
6. 5 1 职场关系论 zcgxl 职场 36.59 200501
7. 6 1 健康生活 jksh 生活 20.47 200008
8. 7 1 看清本质 kqbz 社会 10.37 201004
9. 8 1 编程,编程 bcbc 社会 10.37 201004核心代码
Java代码
1. //使用过滤器 最后一个为true时包含边界部分,为false时不包含边界部分
2. //倒数第二个为true时,包含查询边界,为false时不包含
3. TermRangeFilter filter=new TermRangeFilter("ename", new BytesRef("h"), new BytesRef("n"), true, true);
4. TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),filter,10000);//默认无排序方式输出结果
Java代码
1. 6 1 健康生活 jksh 生活 20.47 200008
2. 7 1 看清本质 kqbz 社会 10.37 201004核心代码
Java代码
1. NumericRangeFilter<Double> filter=NumericRangeFilter.newDoubleRange("price", 10D, 40D, true, false);
2. TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),filter,10000);//默认无排序方式输出结果
Java代码
1. 2 1 三国演义 sgyy 小说 36.13 201207
2. 5 1 职场关系论 zcgxl 职场 36.59 200501
3. 6 1 健康生活 jksh 生活 20.47 200008
4. 7 1 看清本质 kqbz 社会 10.37 201004
5. 8 1 编程,编程 bcbc 社会 10.37 201004
核心代码
Java代码
1. //使用缓存过滤
2. Filter filter=FieldCacheRangeFilter.newDoubleRange("price", 20D, 50D, true, true);
3. TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),filter,10000);//默认无排序方式输出结果
Java代码
1. 2 1 三国演义 sgyy 小说 36.13 201207
2. 5 1 职场关系论 zcgxl 职场 36.59 200501
3. 6 1 健康生活 jksh 生活 20.47 200008










