ClickHouse UBA 版本是字节跳动内部在开源版本基础上为火山引擎增长分析专门深度定制优化的版本。本文介绍在字典编码方向上的优化实践,作者系字节跳动数据平台研发工程师 Jet He,长期致力于 OLAP 引擎开发优化,在 OLAP 领域、用户行为在线分析等有丰富的经验。
背景
虽然 ClickHouse 列存已经有比较好的存储压缩率,但面对海量数据时,磁盘空间的占用跟常用的 Parquet 格式相比仍然有不少差距。特别是对于低基数列时,Parquet 的存储空间会更加有优势。
同时,大多这类数据的事件属性都有低基数的特征,例如事件属性中的城市、性别、品牌等等。Parquet 会自动对低基数列做字典编码,因此会获得更高的存储效率。
同时 ClickHouse 官方也提供了一种字典编码的解决方案即 LowCardinality 类型,网上也有一些测试 Benchmark 数据,效果不错,可以进一步降低存储空间和提升查询、IO 性能。
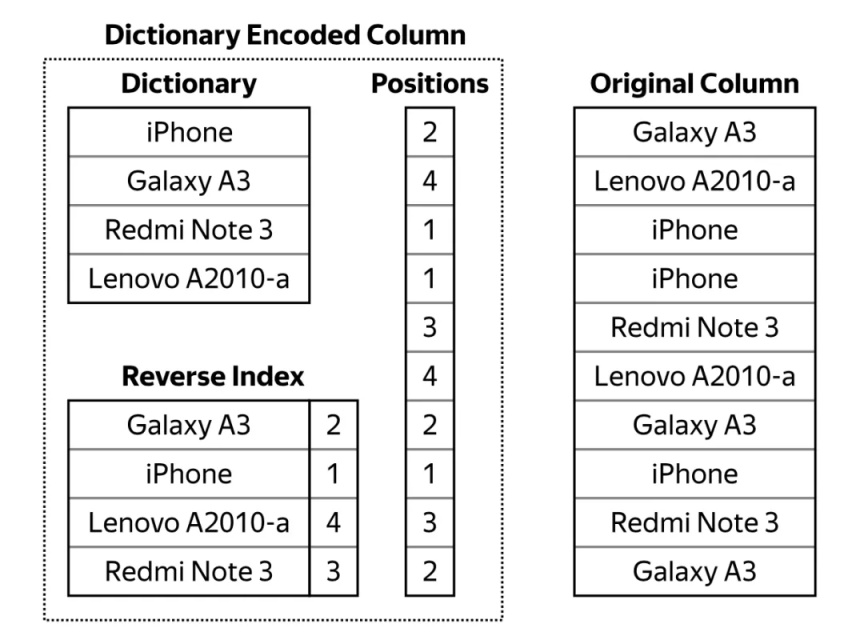
上图是内部 LowCardinality 的存储结构,写入过程中,会构建一个字典,列数据通过 Positions 表示,数值是字典中每个 Unique 值的 Index。其他更加详细的介绍可以参考官方文档。
但在内部环境中通过验证测试发现,原始的 LowCardinality 列存在以下两个致命问题:
- 在 LowCardinality 列比较多的情况下(平均 300+),Part Merge 耗时严重,在大量实时写入的场景下,Merge 速度跟不上写入速度,最终会导致集群不可用;
- 用户数据中事件属性多种多样,UBA 版本通过动态 Map 列实现用户属性的自由上报,也会导致某些属性基数非常大,不再适合做字典编码,否则会同时导致存储、计算性能下降。
如果以上两个问题得不到解决,那么字典编码功能就无法上线使用。需要一种解决方案,能够做到支持大量的列做字典编码的同时需要保证内部 Part 的 Merge 速度,另外就是面对高基数列时需要一个 Fall back 方案,让高基数列时不再做字典编码,改用原始列存储。原作者在做字典编码技术分享时也提到了针对高基数列时 Fall back 到原始列的构想,但社区版本中目前没有付诸实现。
解决方案
首先来看针对 LowCardinality 列 Part Merge 的优化方案。
这里先介绍下 ClickHouse 的 Part Merge 过程。ClickHouse 的数据组织是以 Part 形式存在的,每个 Part 对应磁盘的一个数据目录,每次写入都会生成一个 Part,Part 目录下包含各个列的数据文件。因此每次写入的时候最好是大批量的写入,才能有较好的写入吞吐。
ClickHouse 有常驻 Worker 线程不断的做 Part 的 Merge,将小 Part 不断地 Merge 成大 Part,从而提升查询性能。如果 Part 不能及时 Merge 会造成严重的性能问题,更有甚者还会造成 Inodes 耗尽。
当统一把事件属性列(Map 列)改为 LowCardinality 列时,发现 Part Merge 耗时严重,Part 数会不断增长,最终会导致集群不可用。通过 Profile 发现,在 LowCardinality 列 Part Merge 时,耗时主要发生在字典构造上,具体如下图灰色部分所示:
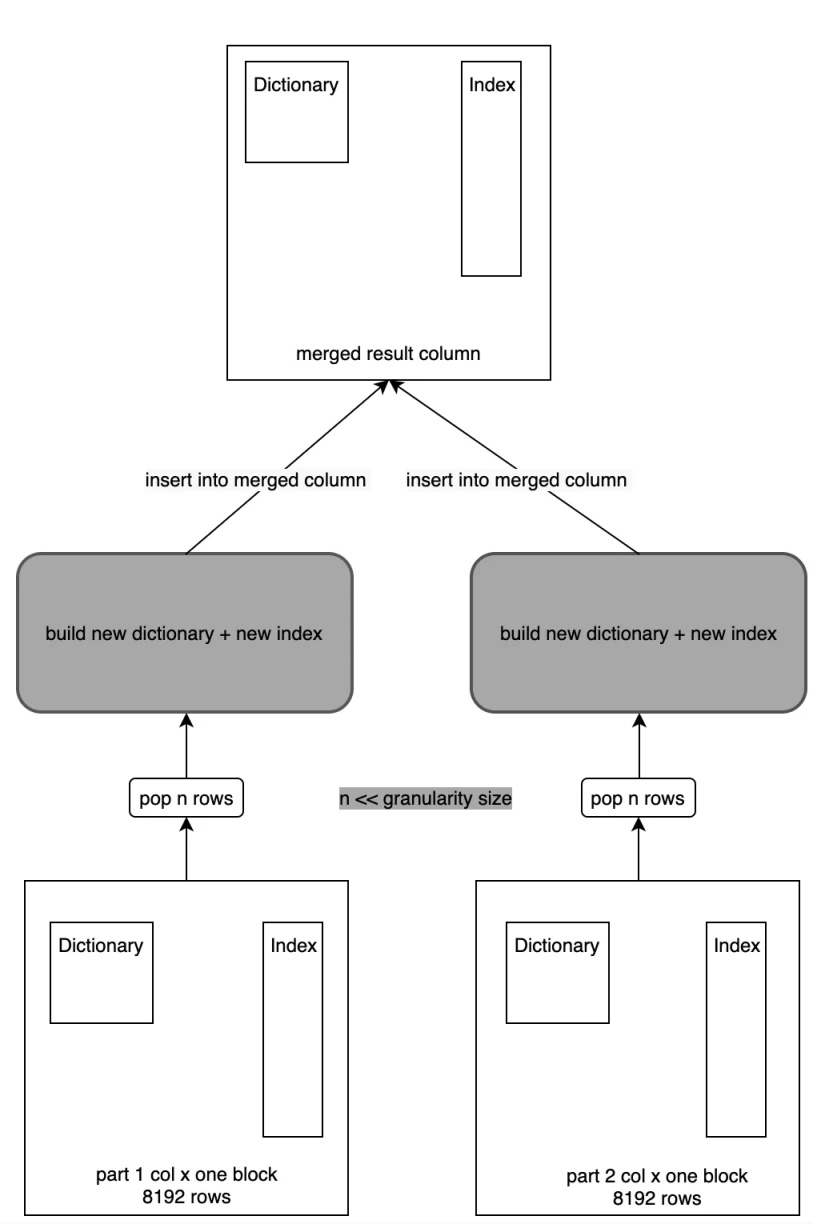
即在做 Part Merge 过程中,首先会通过 Primary Key 列做排序,然后从每个 Part 中获取对应的 Row 写入到一个新的 Part 中。例如一次从 Part1 中取 3 行写入到新 Part 中,下一次从 Part2 中取 5 行写入到新 Part 中,写入到新 Part 时,LowCardinality 首先做构建新的字典,并生成好倒排索引,形成一个新的 LowCardinality 列,然后通过 Column 的 Insert 接口完成写入。另外在构建字典的过程中,是通过一个 HashTable 实现,这样在做 Merge 时这块的性能损耗较大,所以优化的关键点就是在于字典的构建过程。
这里实现了一种先构建字典后做具体 Merge 的思路,即多个 Part 的 Merge 过程中,词典只需要构建一次,然后接下来的 Merge 只需要将 Index 直接 Append 写入到新 Part 即可。
整个过程可以分为两个过程:
01 -Dictionary Merge
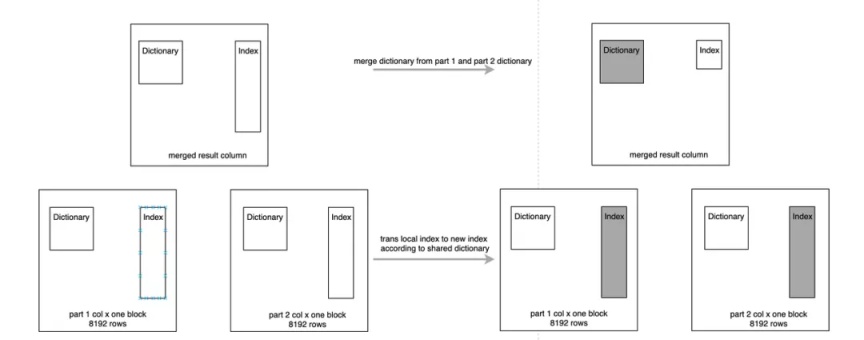
首先进行字典的 Merge,在 Merge 的过程中,先将待 Merge 的几个 Part 中的字典部分做 Merge,生成一个字典,同时记录下每个 Part 这个列中 Index 的变化,这个变化类似一个转换矩阵;
Index Merge 过程中将这个转换矩阵逐个 Apply 到 Part 中的 Index,有时这个转换矩阵为空,例如 Unique 值很少的列,基本可以保证每个 Part 的字典基本一样,如果转换矩阵为空这步操作会直接跳过。
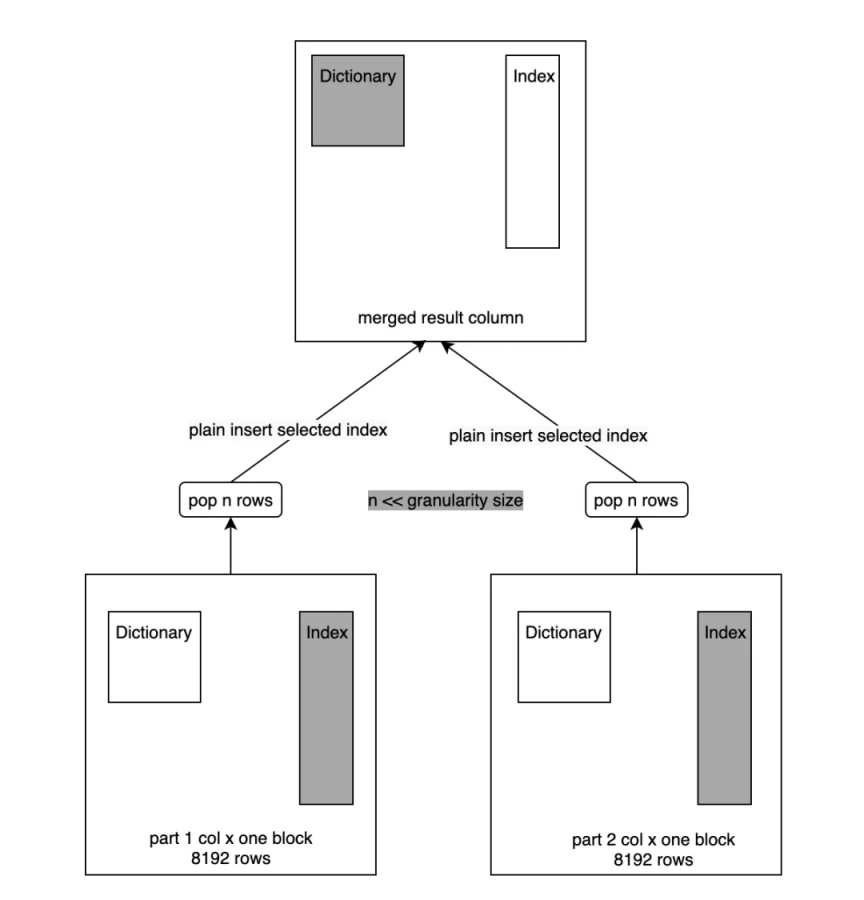
02 -Index Merge
Index Merge 过程跟之前的 Merge 过程一致,只不过这里不再做字典构建了,会直接将列中的 Index Append 到新列的 Index 中,如下图所示:
经过这个 Merge 优化后,LowCardinality 的 Merge 性能有明显提升,在大量写入的场景也能应付自如,写入的 Part 可以得到及时 Merge。
具体的性能优化测试数据如下表所示,Merge 速度的是在表写入过程中统计得出,写入大量大概 10 亿左右:

可以看出在基数 10 万以内时性能提升非常明显,当基数 100 万+时,性能提升不明显,并且在 1000 万时还会导致性能回退。这里也不难理解,因为当基数变大时,Merge 过程中转换矩阵会变得很大,转换矩阵的 Apply 的过程就会变成一个新的瓶颈点。解决这一问题的只有 Fall back 方案,即将高基数列自动不做字典编码。
Fall back 方案在内部做了很多讨论,也跟原作者讨论了可能的实现方案。
最终通过 LowCardinality 内部封装的方式实现。如下图所示:
Stream 可以理解为文件流,通过 Version 值标识该列是否是已经是 Fall back 的列。
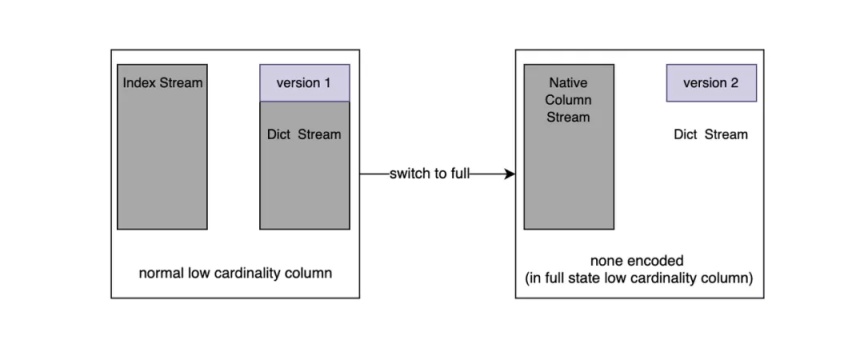
内部复用了 Index Stream,如果发生了 Fall back 那么这个 Stream 里面的值便是原始列的值。Fall back 可以发生在实时写入过程中和 Part Merge 过程中。如果此列发生了 Fall back 后续的所有 Part 都将是 Fall back 的。
Fall back 后,一个高基数列的 Merge 速度和存储性能对比,连续写入 1 亿条记录的统计:

从表中可以看出,Fall back 后的列基本跟原始列性能接近,至少保证 Merge 和存储性能没有退化。如果不做 Fall back,存储空间占用会比原始列还要多,Merge 性能无法支撑实时写入。
通过 Merge 优化和自动 Fall back 解决了 LowCardinality 列的两大绊脚石,接下来看下我们在内部一些大应用上的测试验证效果。
性能验证
下面是在内部某些大 APP 上的验证结果。
1、磁盘占用
数据表是内部某些 APP 某个时间段的数据。
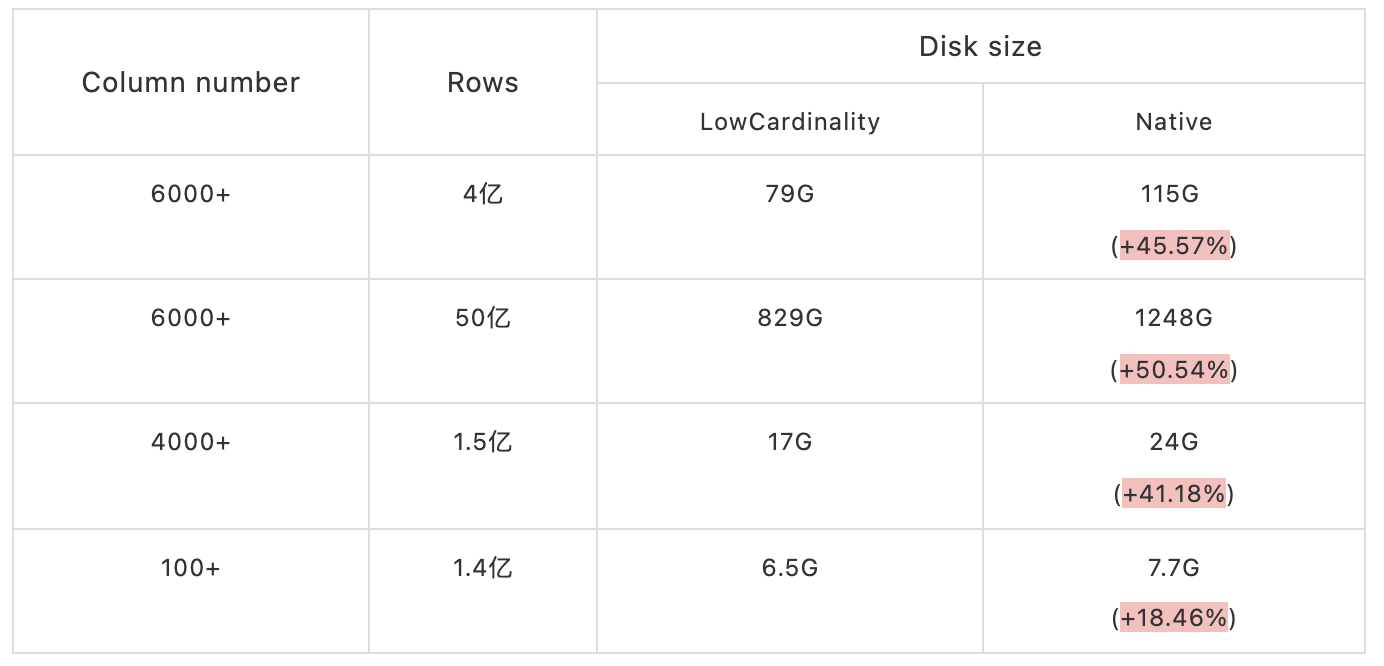
从上表中可以看出,列越多,数据量越大,存储空间下降就会越明显,最高可以节省一半的数据存储空间。在数据量非常的大 APP 场景下,上线 LowCardinality 后可以节省大量的存储资源。
2、针对某个 APP,获取其典型的 10 个业务 SQL,做查询性能测试。
下面是两个数据表分别查询的对比测试结果:
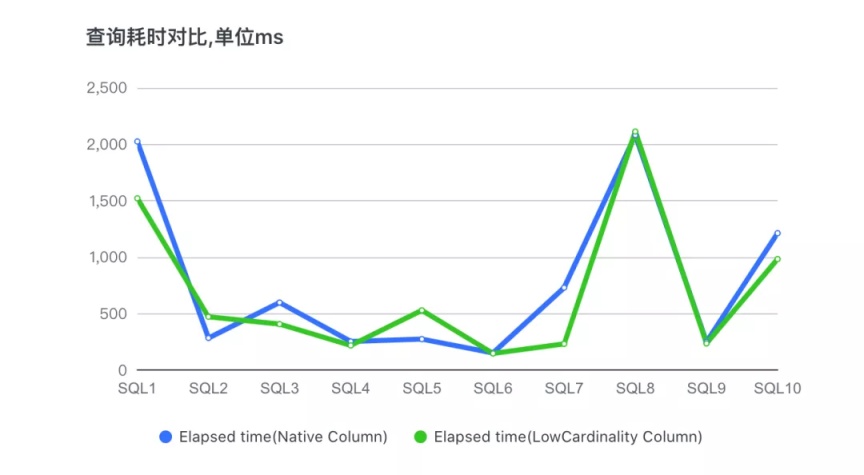
从上图可以看出,有两个 SQL 导致查询性能有回退现象,其余 SQL 都是 LowCardinality 的表查询性能更优,耗时更短。
3、10 个查询对应的磁盘数据读取量:
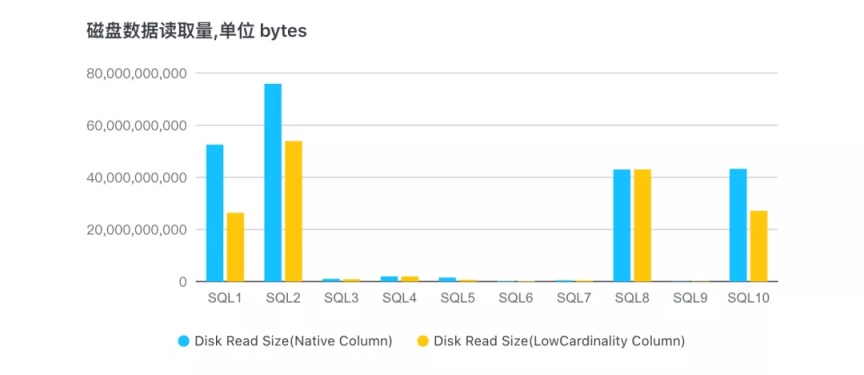
可以看出,基本上所有 SQL 读取的数据量都有明显的减少,对磁盘 IO 的压力会降低很多。SQL8 对应的查询列已经做了 Fall back,所以跟原始列读取数据量持平。
下图是查询时对应的内存使用量:
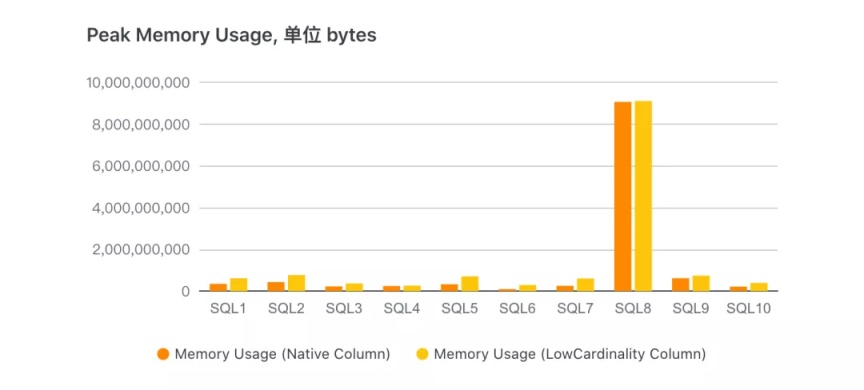
其中除了 SQL8 发生了 Fall back 外,其他查询均是 LowCardinlity 表内存使用量较大。由于 LowCardinality 列计算过程中,如 filter,需要读取的 Part 字典并将列反解出来,每个 Part 的字典是独立存在的,这样在计算过程中会多占用些内存。这块也是后续优化的重点。
小结
目前 ClickHouse UBA 版已经全面启用了字典编码列,并且在火山引擎增长分析(DataFinder)服务的多个客户环境中已经上线。
从实践反馈看,我们为客户节省了大量存储资源,同时在大多数场景下查询性能也有提升明显。总体上由于字典位于每个 Part 中独立存储,查询过程中无法做到在压缩域直接计算,因而会造成个别场景下查询性能不佳,并且内存使用量上会增加。
下一步工作的重点将是优化 LowCardinality 的计算过程,例如把字典做成 Part 间共享的,可以减少计算过程中内存占用,进一步扩展复杂场景在可以直接在压缩域做计算。
参考文献
- https://github.com/yandex/clickhouse-presentations/raw/master/meetup19/string_optimization.pdf
- https://clickhouse.com/docs/en/sql-reference/data-types/lowcardinality/
火山引擎增长分析
一站式用户分析与运营平台,为企业提供数字化消费者行为分析洞见,优化数字化触点、用户体验,支撑精细化用户运营,发现业务的关键增长点,提升企业效益。
- 欢迎关注同名公众号「字节跳动数据平台」










