
文 | 極光

上次为大家介绍了如何通过 Python 抓取新房楼盘价格信息,很多朋友都在问,那二手房最新的价格信息要如何抓取呢?好!今天就再来为大家讲一讲,二手房的房价信息要怎么抓取。
模块安装
同上次新房一样,这里需要安装以下模块(当然如果已安装就不用再装了):
# 安装引用模块
pip3 install bs4
pip3 install requests
pip3 install lxml
pip3 install numpy
pip3 install pandas好了,安装完成后,就可以开始写代码了。至于配置请求头和代理IP地址的代码,上次介绍新房已经说过了,这里不再赘述,下面直接上抓取代码。
二手房价数据对象
在这里我们将二手房的房价信息,创建成一个对象,后续我们只要将获取到的数据保存成对象,再处理就会方便很多。SecHouse 对象代码如下所示:
# 二手房信息对象
class SecHouse(object):
def __init__(self, district, area, name, price, desc, pic):
self.district = district
self.area = area
self.price = price
self.name = name
self.desc = desc
self.pic = pic
def text(self):
return self.district + "," + \
self.area + "," + \
self.name + "," + \
self.price + "," + \
self.desc + "," + \
self.pic获取二手房价信息并保存
准备好了,下面我们依然以贝壳为例,批量爬取其北京地区二手房数据,并保存到本地。这里我主要想说的是如何抓取数据过程,所以这里依然就保存成最简单的 txt 文本格式。如果想保存到数据库,可以自行修改代码进行保存数据库处理。
获取区县信息
我们在抓取二手房信息时,肯定想知道这个房源所在地区,所以这里我写了个方法把北京市所有区县信息抓取下来,并临时保存至列表变量里,以备后续程序中使用,代码如下:
# 获取区县信息
def get_districts():
# 请求 URL
url = 'https://bj.ke.com/xiaoqu/'
headers = create_headers()
# 请求获取数据
response = requests.get(url, timeout=10, headers=headers)
html = response.content
root = etree.HTML(html)
# 处理数据
elements = root.xpath('///div[3]/div[1]/dl[2]/dd/div/div/a')
en_names = list()
ch_names = list()
# 循环处理对象
for element in elements:
link = element.attrib['href']
en_names.append(link.split('/')[-2])
ch_names.append(element.text)
# 打印区县英文和中文名列表
for index, name in enumerate(en_names):
chinese_city_district_dict[name] = ch_names[index]
return en_names获取地区板块
除了上面要获取区县信息,我们还应该获取比区县更小的板块区域信息,同样的区县内,不同板块地区二手房的价格等信息肯定不一样,所以板块对于我们来说也很重要,具有一次参考价值。获取板块信息代码如下:
# 获取某个区县下所有板块信息
def get_areas(district):
# 请求的 URL
page = "http://bj.ke.com/xiaoqu/{0}".format(district)
# 板块列表定义
areas = list()
try:
headers = create_headers()
response = requests.get(page, timeout=10, headers=headers)
html = response.content
root = etree.HTML(html)
# 获取标签信息
links = root.xpath('//div[3]/div[1]/dl[2]/dd/div/div[2]/a')
# 针对list进行处理
for link in links:
relative_link = link.attrib['href']
# 最后"/"去掉
relative_link = relative_link[:-1]
# 获取最后一节信息
area = relative_link.split("/")[-1]
# 去掉区县名称,以防止重复
if area != district:
chinese_area = link.text
chinese_area_dict[area] = chinese_area
# 加入板块信息列表
areas.append(area)
return areas
except Exception as e:
print(e)获取二手房信息并保存
# 创建文件准备写入
with open("sechouse.txt", "w", encoding='utf-8') as f:
# 定义变量
total_page = 1
# 初始化 list
sec_house_list = list()
# 获取所有区县信息
districts = get_districts()
# 循环处理区县
for district in districts:
# 获取某一区县下所有板块信息
arealist = get_areas(district)
# 循环遍历所有板块下的小区二手房信息
for area in arealist:
# 中文区县
chinese_district = chinese_city_district_dict.get(district, "")
# 中文版块
chinese_area = chinese_area_dict.get(area, "")
# 请求地址
page = 'http://bj.ke.com/ershoufang/{0}/'.format(area)
headers = create_headers()
response = requests.get(page, timeout=10, headers=headers)
html = response.content
# 解析 HTML
soup = BeautifulSoup(html, "lxml")
# 获取总页数
try:
page_box = soup.find_all('div', class_='page-box')[0]
matches = re.search('.*data-total-count="(\d+)".*', str(page_box))
# 获取总页数
total_page = int(math.ceil(int(matches.group(1)) / 10))
except Exception as e:
print(e)
print(total_page)
# 设置请求头
headers = create_headers()
# 从第一页开始,遍历到最后一页
for i in range(1, total_page + 1):
# 请求地址
page = 'http://bj.ke.com/ershoufang/{0}/pg{1}'.format(area,i)
print(page)
# 获取返回内容
response = requests.get(page, timeout=10, headers=headers)
html = response.content
soup = BeautifulSoup(html, "lxml")
# 获得二手房查询列表
house_elements = soup.find_all('li', class_="clear")
# 遍历每条信息
for house_elem in house_elements:
# 价格
price = house_elem.find('div', class_="totalPrice")
# 标题
name = house_elem.find('div', class_='title')
# 描述
desc = house_elem.find('div', class_="houseInfo")
# 图片地址
pic = house_elem.find('a', class_="img").find('img', class_="lj-lazy")
# 清洗数据
price = price.text.strip()
name = name.text.replace("\n", "")
desc = desc.text.replace("\n", "").strip()
pic = pic.get('data-original').strip()
# 保存二手房对象
sec_house = SecHouse(chinese_district, chinese_area, name, price, desc, pic)
print(sec_house.text())
sec_house_list.append(sec_house)
# 循环遍历将信息写入 txt
for sec_house in sec_house_list:
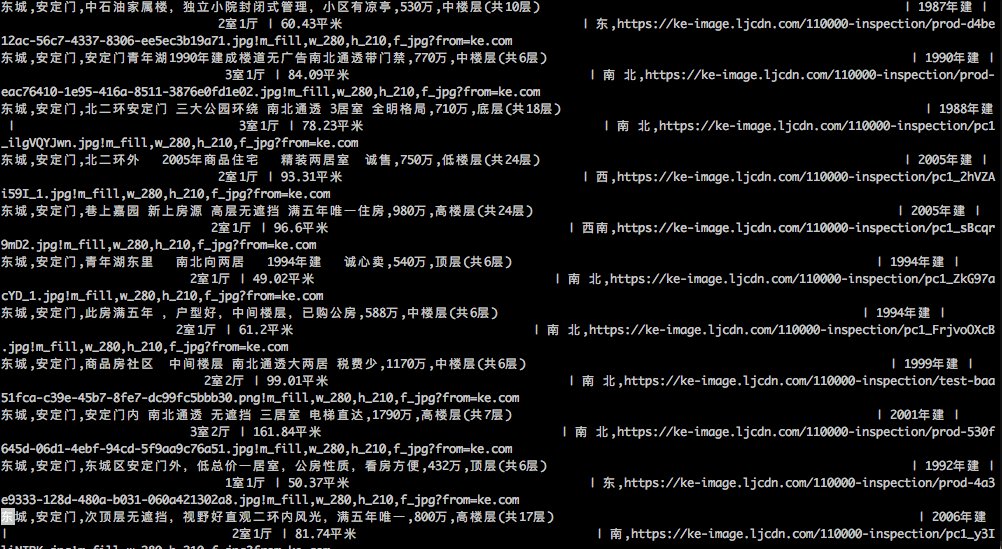
f.write(sec_house.text() + "\n")到这里代码就写好了,现在我们就可以通过命令 python sechouse.py 运行代码进行数据抓取了。抓取的结果我们可以打开当前目录下 sechouse.txt 文件查看,结果如下图所示:
总结
本文为大家介绍了如何通过 Python 将房产网上的二手房数据批量抓取下来,经过一段时间的抓取,我们就可以将抓取的结果进行对比分析,看看二手房价最近是涨还是跌?如果喜欢我们的文章,请关注收藏再看。
PS:公号内回复 :Python,即可进入Python 新手学习交流群,一起100天计划!
老规矩,兄弟们还记得么,如果感觉文章内容不错的话,记得分享让更多的人知道!
!


【代码获取方式】
识别文末二维码,回复:200430











