一、where:逐个元素按条件选取【并行计算,速度快】
torch.where(condition,x,y) #condition必须是tensor类型
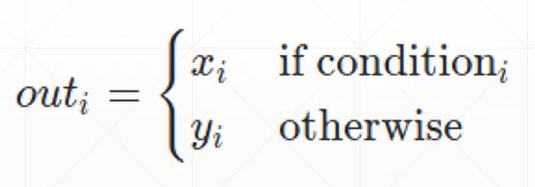
condition的维度和x,y一致,用1和0分别表示该位置的取值
import torch
cond = torch.tensor([[0.6, 0.7],
[0.3, 0.6]])
a = torch.tensor([[1., 1.],
[1., 1.]])
b = torch.tensor([[0., 0.],
[0., 0.]])
result = torch.where(cond > 0.5, a, b) # 此时cond只有0和1的值
print('result = \n', result)
打印结果:
result =
tensor([[1., 1.],
[0., 1.]])
Process finished with exit code 0
二、gather:相当于查表取值操作
torch.gather(input, dim, index, out=None)
相当于查表取值操作
import torch
prob = torch.randn(4, 6)
print("prob = \n", prob)
prob_topk = prob.topk(dim=1, k=3) # prob在维度1中前三个最大的数,一共有4行,返回值和对应的下标
print("\nprob_topk = \n", prob_topk)
topk_idx = prob_topk[1]
print("\ntopk_idx: ", topk_idx)
temp = torch.arange(6) + 100 # 举个例子,这里的列表表示为: 0对应于100,1对应于101,以此类推,根据实际应用修改
label = temp.expand(4, 6)
print('\nlabel = ', label)
result = torch.gather(label, dim=1, index=topk_idx.long()) # lable相当于one-hot编码,index表示索引
# 换而言是是y与x的函数映射关系,index表示x
print("\nresult:", result)
打印结果:
prob =
tensor([[-0.4978, 1.4266, -0.1138, 0.2140, -1.2865, -0.0214],
[ 0.1554, -0.0286, 1.3697, 0.3916, 1.2014, -0.3400],
[ 0.3241, -1.2284, 0.6961, 2.1932, 0.4673, 0.3504],
[ 1.7158, 0.3352, -0.1968, 0.3934, 0.0186, 0.5031]])
prob_topk =
torch.return_types.topk(
values=tensor([[ 1.4266, 0.2140, -0.0214],
[ 1.3697, 1.2014, 0.3916],
[ 2.1932, 0.6961, 0.4673],
[ 1.7158, 0.5031, 0.3934]]),
indices=tensor([[1, 3, 5],
[2, 4, 3],
[3, 2, 4],
[0, 5, 3]]))
topk_idx: tensor([
[1, 3, 5],
[2, 4, 3],
[3, 2, 4],
[0, 5, 3]
])
label = tensor([
[100, 101, 102, 103, 104, 105],
[100, 101, 102, 103, 104, 105],
[100, 101, 102, 103, 104, 105],
[100, 101, 102, 103, 104, 105]])
result: tensor([
[101, 103, 105],
[102, 104, 103],
[103, 102, 104],
[100, 105, 103]])
Process finished with exit code 0
三、scatter_()
scatter_(input, dim, index, src):将src中数据根据index中的索引按照dim的方向填进input。可以理解成放置元素或者修改元素
- dim:沿着哪个维度进行索引
- index:用来 scatter 的元素索引
- src:用来 scatter 的源元素,可以是一个标量或一个张量


