温馨提示:如果使用电脑查看图片不清晰,可以使用手机打开文章单击文中的图片放大查看高清原图。
Fayson的github:
https://github.com/fayson/cdhproject
提示:代码块部分可以左右滑动查看噢
1
诡异现象
在Fayson的测试测试环境下有一张Parquet格式的表,由于业务需要对表的字段名称数据类型进行了修改和新增列等操作,导致使用Hive和Impala查询显示的结果不一致问题。
Impala查询表时由于数据类型问题直接抛出异常:
WARNINGS: File 'hdfs://nameservice1/user/hive/warehouse/hdfs_metadata.db/d1/f44290ca8d0484dc-aec3029c00000000_2136518694_data.0.parq' has an incompatible Parquet schema for column 'hdfs_metadata.d1.c3'. Column type: TIMESTAMP, Parquet schema:
optional byte_array c4 [i:2 d:1 r:0]
Hive查询显示的结果与预期的一致(修改列名或新增列对结果没有影响)
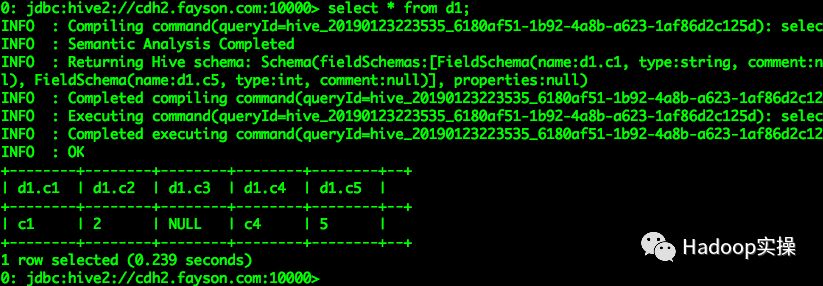
2
问题复现
1.创建一个用于测试的表并向表中插入测试数据,SQL语句如下:
create table d1 (c1 string, c2 int, c4 string, c5 int) stored as parquet;
insert into d1 values('c1', 2, 'c4',5);
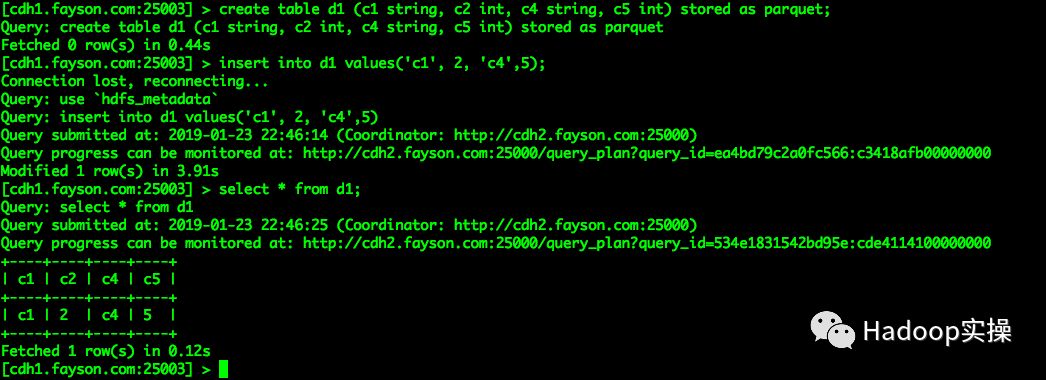
向表中插入一条测试数据
2.向d1表中添加一个新的列
alter table d1 add columns (dummy int);
select * from d1;
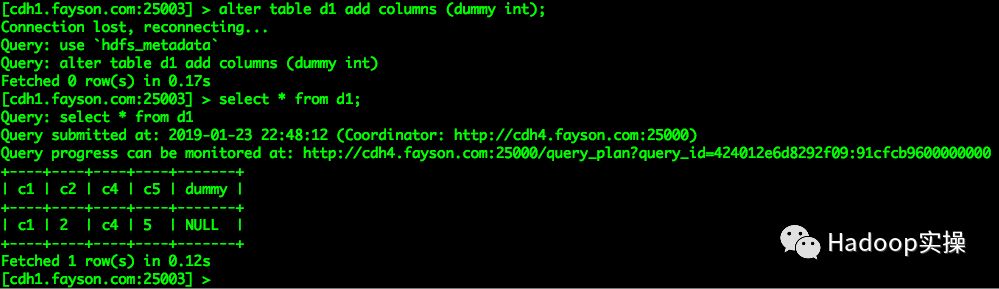
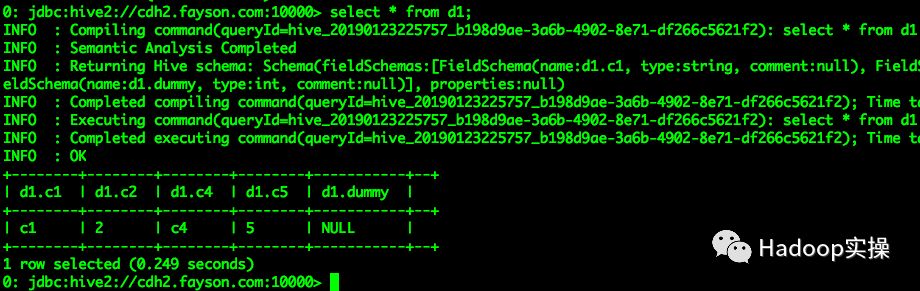
表中dummy新增的列的值填充为NULL,Hive和Impala查询均符合预期。
3.将d1表的c4列重命名为c3并修改类型为Timestamp
alter table d1 change c4 c3 timestamp;
select * from d1;

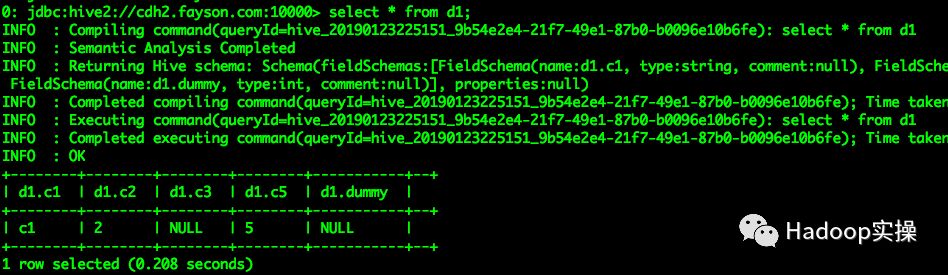
Impala由于表的Schema和Parquet的Schema不一致直接抛出异常,Hive查询符合预期由于c3列在Parquet文件的Schema不存在所以返回值为NULL。
4.将d1表的c5列重命名为c4并修改类型为String
alter table d1 change c5 c4 string;
select * from d1;

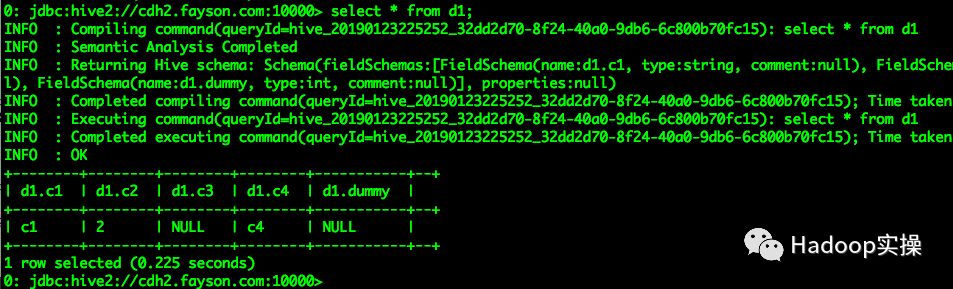
Impala查询依然抛出异常,Hive查询符合预期,c3和dummy两列在Parquet文件的Schema中不存在返回NULL,c5列重命名为c4列后可以正常获取到c4列的值,与表原始数据一致。
5.将d1表的dummy列重命名为c5并修改数据类型为int
alter table d1 change dummy c5 int;
select * from d1;

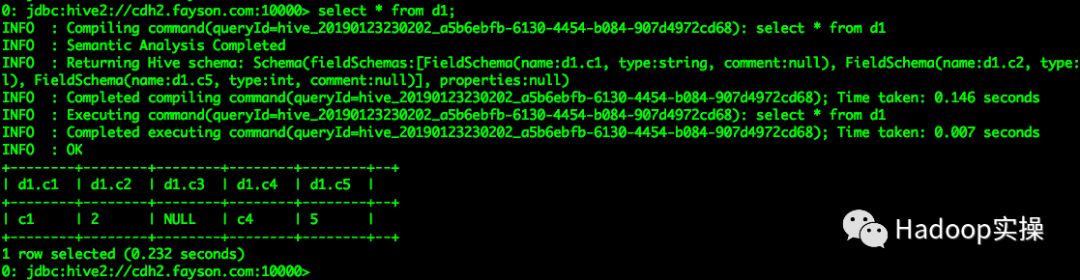
Impala查询依然抛出异常,Hive查询符合预期,c3列在Parquet文件的Schema中不存在返回NULL,dummy列重命名为c5列后可以正常获取到c5列的值,与表原始数据一致。
3
问题分析及解决
因为Impala对Parquet文件中列的顺序很敏感,所以在表的列定义与Parquet文件的列定义顺序不一致时,会导致Impala查询返回的结果与预期不一致。可以参考Impala的JIRA,https://issues.apache.org/jira/browse/IMPALA-779
针对上述问题,有如下解决方法:
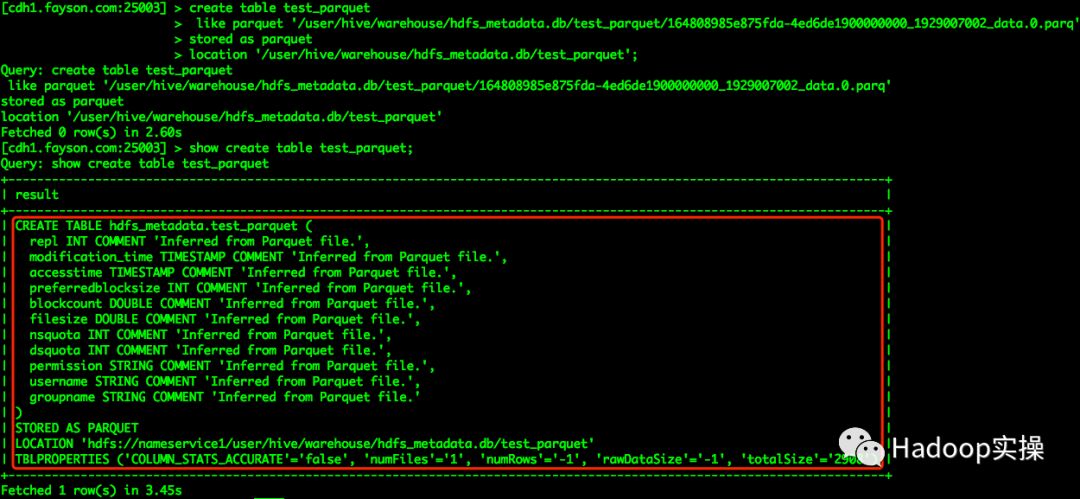
1.使用parquet文件中的Schema列名重建表,且不要修改列名及列的数据类型,操作如下:
create table test_parquet
like parquet '/user/hive/warehouse/hdfs_metadata.db/test_parquet/494df794383e3064-44fc0cc300000000_2075681924_data.0.parq'
stored as parquet
location '/user/hive/warehouse/hdfs_metadata.db/test_parquet';
将parquet文件put到/user/hive/warehouse/hdfs_metadata.db目录下

执行建表语句重建表
2.在Impala查询的每个会话中执行如下语句
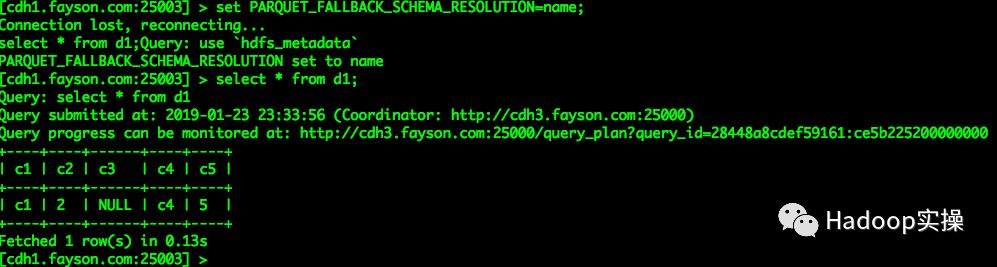
set PARQUET_FALLBACK_SCHEMA_RESOLUTION=name;
select * from d1;
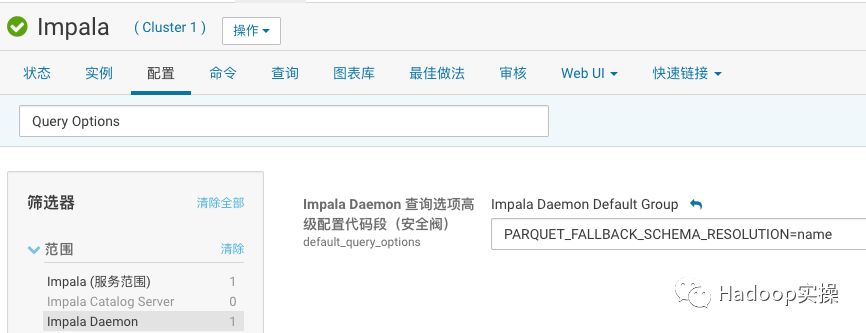
同样也可以通过CM将该参数配置为全局的,进入Impala配置界面搜索“Query Options”
4
总结
1.使用Hive查询Parquet格式表时,通过表的列名与Parquet文件中的列进行匹配返回数据,因此在表列顺序发生变化时并不会影响返回结果。
2.Impala对表的列顺序与Parquet文件中列的顺序比较敏感,默认情况下需要确保表列的顺序与Parquet中列顺序一致,如果列顺序与Parquet文件列不一致则需要在会话中设置set PARQUET_FALLBACK_SCHEMA_RESOLUTION=name;属性。
3.Hive表的字段名、类型必须和Parquet文件中的列和类型一致,否则会因为列名不匹配或数据类型不一致而导致无法返回预期的结果。
提示:代码块部分可以左右滑动查看噢
为天地立心,为生民立命,为往圣继绝学,为万世开太平。
温馨提示:如果使用电脑查看图片不清晰,可以使用手机打开文章单击文中的图片放大查看高清原图。
推荐关注Hadoop实操,第一时间,分享更多Hadoop干货,欢迎转发和分享。

原创文章,欢迎转载,转载请注明:转载自微信公众号Hadoop实操










