背景
我们这边应用部署的环境比较复杂,主要有以下几种:
- 机器直接部署
- 通过kubernates集群部署
部署环境不统一,导致查看应用日志很不方便。
业界日志系统架构
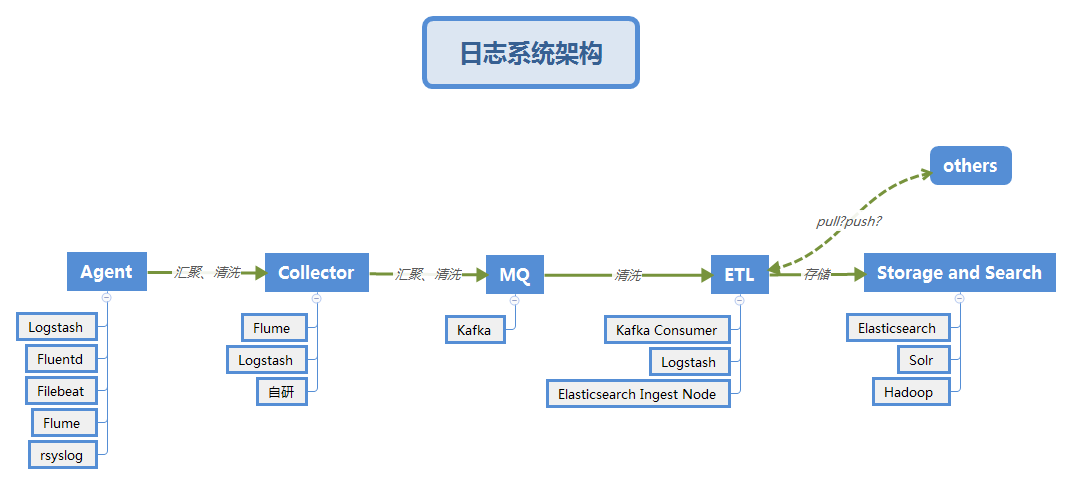
-
Collector的作用是:
- 清洗、汇聚数据,减少对于后端集群的压力。
- 安全,不允许Agent直连kafka等内部集群,保证一定的安全性,即使后端发生调整也能保证对于Agent连接、认证方式的稳定。
-
MQ的作用是削峰填谷、解耦、多次消费。
组件选择
选择组件,我们这边主要是从以下几个方面进行考量的:
- 组件对应的开源生态完整、活跃度高
- 运维成本
- 易部署、性能好
Agent: 主要比较下相对熟悉的Logstash和filebeat。
指标 Logstash filebeat Log-pilot 内存 大 小 背压敏感协议 否 是 插件 多 多 功能 从多种输入端采集并实时解析和转换数据并输出到多种输出端 传输 支持收集容器的标准输出日志和文件 轻重 重 轻 轻 过滤功能 强大的过滤功能 有过滤功能但较弱 Log-pilot支持不同的插件收集日志( Filebeat Plugin与Fluentd Plugin ) 集群 单节点 单节点 单节点 输出到多个接收方 支持 支持 支持 原理 Logstash使用管道的方式进行日志的搜集和输出,分为输入input-->处理filter(不是必须的)-->输出output,每个阶段都有不同的替代方式 开启进程后会启动一个或者多个探测器(prospectors)去检测指定的日志目录或者文档建,对于探测器找出的每个日志文件,filebeat启动收割进程(harvester),每个收割进程读取一个日志文件的新内容,并发送这些新的日志数据到处理程序(spooler),处理程序会集合这些事件,最后filebeat会发送集合的数据到你指定的地点 一个好的agent应该是资源占用少,性能好,不依赖别的组件,可以独立部署。而Logstash明显不符合这几点要求,也许正是基于这些考虑elastic推出了Filebeat。目前log-pilot文档相对较少,如果要对filebeat做特定的配置,需要重新对log-pilot镜像配置完以后重打镜像(譬如异常日志多行合并),且目前log-pilot阿里目前已经不再维护了,社区活跃度不够。综上所述,还是采用原生的Filebeat进行日志收集。
Collector暂时不用,直接来看看MQ
MQ:
filebeat的输出管道类型包括:
Elasticsearch Service、Elasticsearch、Logstash、Kafka、Redis、File、Console目前的方案采用的是kafka作削峰填谷、解耦。
ETL:采用Logstash
Storage and Search:采用ElasticSearch、Kibana
到这里,基本可以看出我们的架构如下:
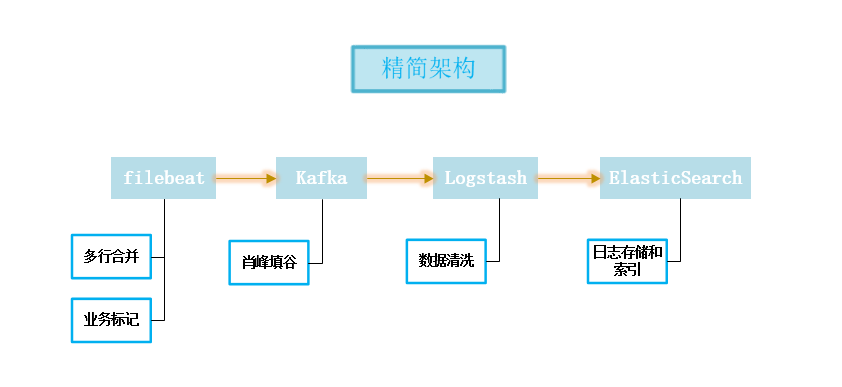
具体实现
Agent日志收集方案:
k8s日志收集filebeat日志收集方案:
| 编号 | 方案 | 优点 | 缺点 |
|---|---|---|---|
| 1 | 每个app的镜像中都集成日志收集组件 | 部署方便,kubernetes的yaml文件无须特别配置,可以为每个app自定义日志收集配置 | 强耦合,不方便应用和日志收集组件升级和维护且会导致镜像过大 |
| 2 | 单独创建一个日志收集组件跟app的容器一起运行在同一个pod中 | 低耦合,扩展性强,方便维护和升级 | 需要对kubernetes的yaml文件进行单独配置,略显繁琐 |
| 3 | 将所有的Pod的日志都挂载到宿主机上,每台主机上单独起一个日志收集Pod | 完全解耦,性能最高,管理起来最方便 | 需要统一日志收集规则,目录和输出方式 |
| 4 | 将所有的Pod的日志挂载到nfs-server上,在nfs-server上单独启一个日志收集Pod | 是方案3的升级版 | 需要统一日志收集规则,目录和输出方式,如果日志收集pod失效,会导致整个日志收集停止,影响范围比方案3大 |
综合以上优缺点,我们选择使用方案三。
统一日志格式:
| 日志类型 | 描述 | 日志包含的因子 | 日志格式 | 备注 |
|---|---|---|---|---|
| biz日志 | 用于业务中打印的info/warn | 全局链路线程号、消费者IP、提供者IP、调用者应用名称、消费者应用名称、客户号、接口名称、具体日志输出的所在行、日志打印的内容 | 仅在代码中logger.info/warn输出才会打印 | |
| err 日志 | 用于业务输出的error | 全局链路线程号、消费者IP、提供者IP、调用者应用名称、消费者应用名称、客户号、接口名称、具体日志输出的所在行、日志打印的堆栈信息 | 仅在代码中logger.error输出才会打印 | |
| io 日志 | 用于接口的输入输出参数 | 全局链路线程号、消费者IP、提供者IP、调用者应用名称、消费者应用名称、客户号、接口名称、具体日志输出的所在行、输入输出的参数、接口耗时 | 仅配置了注解,出入参才不会打印 | |
| monitor日志 | 用于监控接口耗时、接口数据量 | 全局链路线程号、消费者IP、提供者IP、调用者应用名称、消费者应用名称、客户号、接口名称、具体日志输出的所在行、数据量、接口耗时、结果标识(成功 or 失败 ) | 默认全部打印 |
需要解决的问题:
1、日志历史归档压缩(未做)
2、日志敏感数据脱敏(未做)
3、异步日志打印
目前已对日志格式做了调整,增加了异步日志,且将日志文件放到nacos上,可动态配置。

日志打印时间 | 线程号 | traceId | [调用方IP | 调用方 | 提供方IP | 提供方] | [请求url] | 日志打印类 [日志打印行号] - 日志内容
Filebeat配置:
vim /opt/filebeat-6.8.9-linux-x86_64/filebeat-all.yml
文件内容如下:
fields:
ip_inside: 10.210.100.141
fields_under_root: true
filebeat.config.inputs:
enabled: true
path: /opt/filebeat-6.8.9-linux-x86_64/conf/*/*.yml
reload.enabled: true
reload.period: 10s
logging.files:
keepfiles: 3
name: filebeat
path: /opt/filebeat-6.8.9-linux-x86_64/log/
logging.level: info
logging.to_files: true
output.kafka:
bluk_max_size: 4096
compression: gzip
compression_level: 7
hosts:
- 10.210.98.112:9092
partition.round_robin:
reachable_only: true
required_acks: 1
timeout: 45
topic: 'bi-sit'
worker: 1
processors:
- drop_fields:
fields: ["prospector","beat","host","source","log"]
queue.mem:
events: 4096
flush.min_events: 512
flush.timeout: 5s
参数说明:
| 序号 | 参数 | 说明 |
|---|---|---|
| 1 | fields.ip_inside | 存储日志的宿主机IP |
| 2 | filebeat.config.inputs.path | 宿主机日志采集配置文件,统一在/opt/filebeat-6.8.9-linux-x86_64/conf文件夹下 |
| 3 | output.kafka.topic | 日志在Kafka中使用的Topic |
| 4 | output.kafka.hosts | Kafka宿主机IP和Port,检测当前日志宿主机与Kafka宿主机是否可正常通信:telnet 10.210.98.112 9092 |
日志采集配置:
mkdir /opt/filebeat-6.8.9-linux-x86_64/conf
新建各个级别日志采集配置文件
以bi系统测试环境为例:新建文件夹:bi-sit
mkdir /opt/filebeat-6.8.9-linux-x86_64/conf/bi-sit
新建info日志采集配置文件bqx-bi-info.yml,文件内容如下:
- enabled: true
exclude_files:
- .gz$
fields:
log_type: err
server_name: bqx-bi
tags : bi-sit
fields_under_root: true
multiline.match: after
multiline.negate: true
multiline.pattern: ^[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2},[0-9]{3}
paths:
- /u01/bqx-bi/logs/info/bqx-bi-service-info*.log
type: log
参数说明:
| 序号 | 参数 | 说明 |
|---|---|---|
| 1 | fields.server_name | 服务名称 |
| 2 | fields.tags | 服务标签 |
| 3 | paths | 对应级别日志所在的路径 |
Logstash配置:
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
input {
kafka{
bootstrap_servers => ["10.210.3.68:9092"]
client_id => "logger"
group_id => "logger"
auto_offset_reset => "latest"
consumer_threads => 5
decorate_events => true
topics => ["logger"]
codec => json {
charset => "UTF-8" }
}
kafka{
bootstrap_servers => ["10.210.3.68:9092"]
client_id => "activity"
group_id => "activity"
auto_offset_reset => "latest"
consumer_threads => 1
decorate_events => true
topics => ["activity"]
codec => json {
charset => "UTF-8" }
}
kafka{
bootstrap_servers => ["10.210.3.68:9092"]
client_id => "mysqlslowlog"
group_id => "mysqlslowlog"
auto_offset_reset => "latest"
consumer_threads => 1
decorate_events => true
topics => ["mysqlslowlog"]
codec => json {
charset => "UTF-8" }
}
kafka{
bootstrap_servers => ["10.210.3.68:9092"]
client_id => "bi-prd"
group_id => "bi-prd"
auto_offset_reset => "latest"
consumer_threads => 2
decorate_events => true
topics => ["bi-prd"]
codec => json {
charset => "UTF-8" }
}
}
filter {
grok{
match => ["message","(?<logdate>%{YEAR}-%{MONTHNUM}-%{MONTHDAY} %{TIME})",
"message","# Time: (?<time>[0-9]{4}-[0-9]{2}-[0-9]{2}T[0-9]{2}:[0-9]{2}:[0-9]{2})"
]
}
date{
match => [ "logdate", "yyyy-MM-dd HH:mm:ss,SSS"]
locale => "en"
timezone => "Asia/Shanghai"
}
mutate{
remove_field => ["logdate","@metadata"]
}
}
output {
elasticsearch {
hosts => ["http://10.210.3.68:9200"]
index => "%{[tags]}-log-%{+YYYY.MM.dd}"
user => "es用户名"
password => "es密码"
#ssl => true
#ssl_certificate_verification => false
}
}
output中user和password,如果有用户名和密码的话,需要设置,没有可以去掉
针对过期的index需要通过定时任务将对应的index删除掉
脚本如下:
#!/bin/bash
#删除早于15天的ES集群的索引
function delete_indices() {
param=$(echo $1)
#截取索引的日期部分(用于下面的日期比较是否小于15日),我的索引是com-字符串后面的部分为日期, 比如: www.test.com-2020.08.08
dateValue=$(echo ${param#*com-})
#截取日期的前部分作为索引的名称(后续需要替换-为., 然后和日期拼接起来成为一个真正的索引名称,用于删除)
name=$(echo $2)
echo "name=$name date=$dateValue"
comp_date=`date -d "15 day ago" +"%Y-%m-%d"`
date1="$dateValue 00:00:00"
date2="$comp_date 00:00:00"
t1=`date -d "$date1" +%s`
t2=`date -d "$date2" +%s`
if [ $t1 -le $t2 ]; then
echo "$1时间早于$comp_date,进行索引删除"
#转换一下格式,将类似www-test-com格式转化为www.test.com
#转换一下格式,将类似2020-10-01格式转化为2020.10.01
format_date=`echo $dateValue| sed 's/-/\./g'`
#拼接成索引名称
indexName="$name-$format_date"
curl -u admin:admin -k -XDELETE http://10.210.3.68:9200/$indexName
#删除索引
echo "$indexName删除成功"
fi
}
curl -u admin:admin -k http://10.210.3.68:9200/_cat/indices?v | awk -F" " '{print $3}' |egrep prod|awk -F"-" '{print $NF}' | egrep "[0-9]*\.[0-9]*\.[0-
9]*" | sort | uniq | sed 's/\./-/g'| while read LINE
do
#调用索引删除函数, 结果打印到日志
delete_indices $LINE prod-log >> /home/logs/delete_indices.log
done
curl -u admin:admin -k http://10.210.3.68:9200/_cat/indices?v | awk -F" " '{print $3}' |egrep activity|awk -F"-" '{print $NF}' | egrep "[0-9]*\.[0-9]*\
.[0-9]*" | sort | uniq | sed 's/\./-/g'| while read LINE
do
#调用索引删除函数, 结果打印到日志
delete_indices $LINE activity-log >> /home/logs/delete_indices.log
done
匹配逻辑需要根据你自己的索引规范来做适当调整









