之前零零散散写过几篇和 LSM-Tree、LevelDB 有关的文章。之后也看了一些代码和论文,笔记也做了一些,但大都比较零乱、随意,没花功夫整理。
这次打算将之前的文章和之后的笔记一起整理一下,成为一个系列文章——本文是本系列文章的第一篇。
LSM-Tree
Log Structured Merge Tree,简称 LSM-Tree。2006年,Google 发表了 BigTable 的论文。这篇论文提到 BigTable 单机上所使用的数据结构就是 LSM-Tree。
很多存储产品使用 LSM-Tree 作为数据结构,比如 Apache HBase,Apache Cassandra,MongoDB 的 Wired Tiger 存储引擎,LevelDB 存储引擎,RocksDB 存储引擎等。
简单地说,LSM-Tree 的设计目标是提供比传统的 B-Tree/B+Tree 更好的写性能。LSM-Tree 通过将磁盘的随机写转化为顺序写来提高写性能 ,而付出的代价就是牺牲部分读性能、写放大(B-Tree/B+Tree 同样有写放大的问题)。
如何优化写性能
如果我们对写性能特别敏感,我们最好怎么做?—— Append only:所有写操作都是将数据添加到文件末尾。这样顺序写的性能是最好的,大约等于磁盘的理论速度(无论是 SSD 还是 HDD,顺序写性能都要明显由于随机写性能)。但是 append only 的方式会带来一些问题:
- 不支持有序遍历。
- 需要垃圾回收(清理过期数据)。
所以,纯粹的 append only 方式只能适用于一些简单的场景:
如何优化读性能
如果我们对读性能特别敏感,一般我们有两种方式:
- 有序存储,比如 B-Tree/B+Tree。但是 B-Tree/B+Tree 会导致随机写。
- 哈希存储 —— 不支持有序遍历,适用范围有限。
读写性能的权衡
如何获得接近 append only 的写性能,而又能拥有不错的读性能呢?以 LevelDB/RocksDB 为代表的 LSM-Tree 存储引擎给出了一个参考答案。原始的 LSM-Tree 可以参考论文。下面的讨论主要以 LevelDB 为例子。
LevelDB 的写操作(Put/Delete/Write)主要由两步组成:
- 写日志(WAL,顺序写)。
- 写 MemTable(内存中的 SkipList)。
所以,正常情况下,LevelDB 的写速度非常快。
内存中的 MemTable 写满后,会转换为 Immutable MemTable,然后被后台线程 compact 成按 key 有序存储的 SSTable(顺序写)。
SSTable 按照数据从新到旧被组织成多个层次(上层新下层旧),点查询(Get)的时候从上往下一层层查找,所以 LevelDB 的读操作可能会有多次磁盘 IO(LevelDB 通过 table cache、block cache 和 bloom filter 等优化措施来减少读操作的 I/O 次数)。
后台线程的定期 compaction 负责回收过期数据和维护每一层数据的有序性。在数据局部有序的基础上,LevelDB 实现了数据的(全局)有序遍历。
LevelDB 接口使用
LevelDB 提供的接口很简单,请参考官网文档。
LevelDB 整体架构
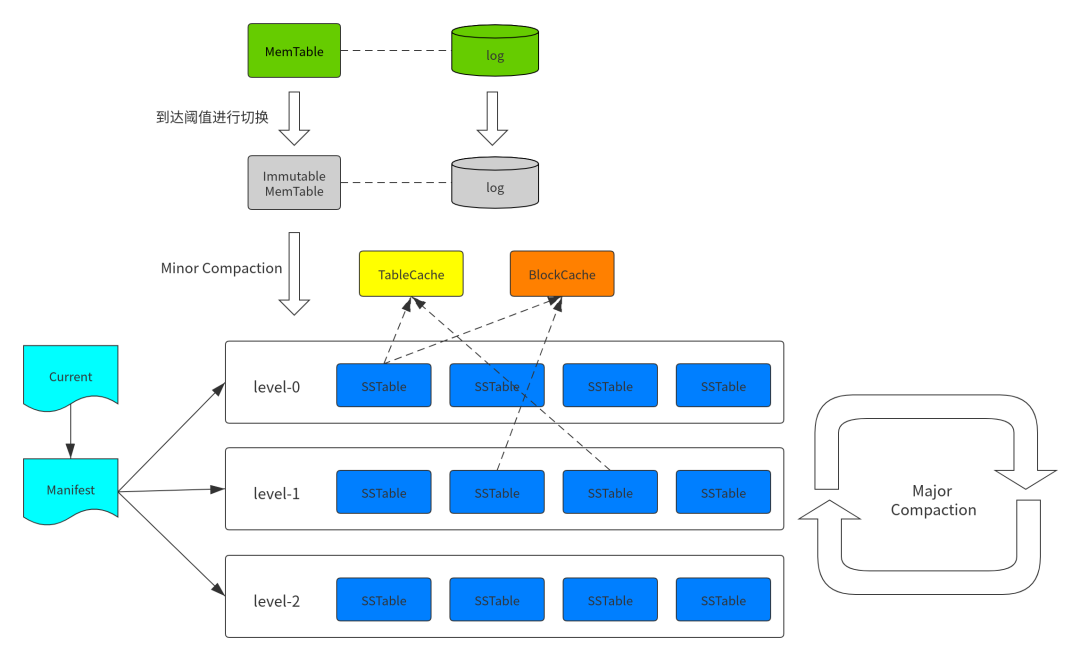
上图简单展示了 LevelDB 的整体架构。
- MemTable:内存数据结构,具体实现是 SkipList。 接受用户的读写请求,新的数据会先在这里写入。
- Immutable MemTable:当 MemTable 的大小达到设定的阈值后,会被转换成 Immutable MemTable,只接受读操作,不再接受写操作,然后由后台线程 flush 到磁盘上 —— 这个过程称为 minor compaction。
- Log:数据写入 MemTable 之前会先写日志,用于防止宕机导致 MemTable 的数据丢失。一个日志文件对应到一个 MemTable。
- SSTable:Sorted String Table。分为 level-0 到 level-n 多层,每一层包含多个 SSTable,文件内数据有序。除了 level-0 之外,每一层内部的 SSTable 的 key 范围都不相交。
- Manifest:Manifest 文件中记录 SSTable 在不同 level 的信息,包括每一层由哪些 SSTable,每个 SSTable 的文件大小、最大 key、最小 key 等信息。
- Current:重启时,LevelDB 会重新生成 Manifest,所以 Manifest 文件可能同时存在多个,Current 记录的是当前使用的 Manifest 文件名。
- TableCache:TableCache 用于缓存 SSTable 的文件描述符、索引和 filter。
- BlockCache:SSTable 的数据是被组织成一个个 block。BlockCache 用于缓存这些 block(解压后)的数据。










