Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
https://space.bilibili.com/523606542完整代码请加Python学习交流群:1039649593找管理员免费领取
前言
现在电商平台有很多商品数据,采集到的数据对电商价格战很有优势
今天带大家采集京东这个电商平台的数据
环境介绍:
python 3.6
pycharm
selenium
csv
time
首先配置好开发环境
先要找到你Google浏览器的版本
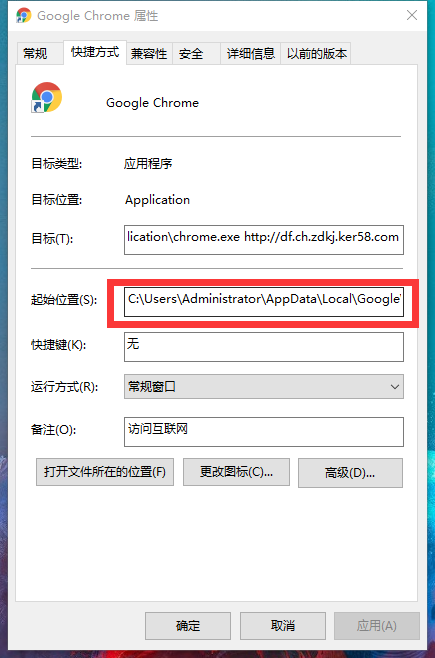
复制地址,随便在一个文件夹内粘贴打开

然后就可以看见你Google浏览器的版本
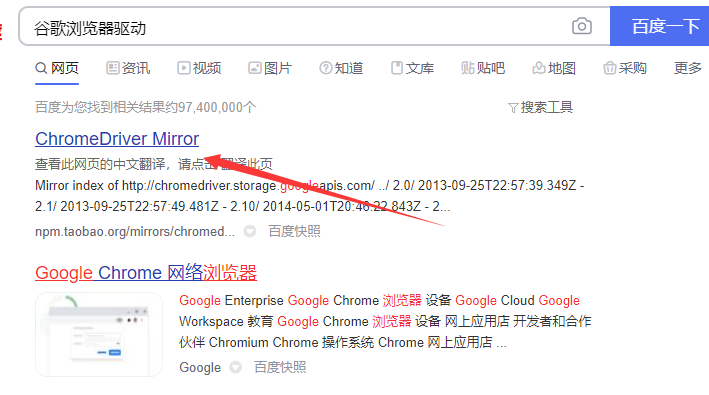
在百度上搜索浏览器驱动,第一个就是
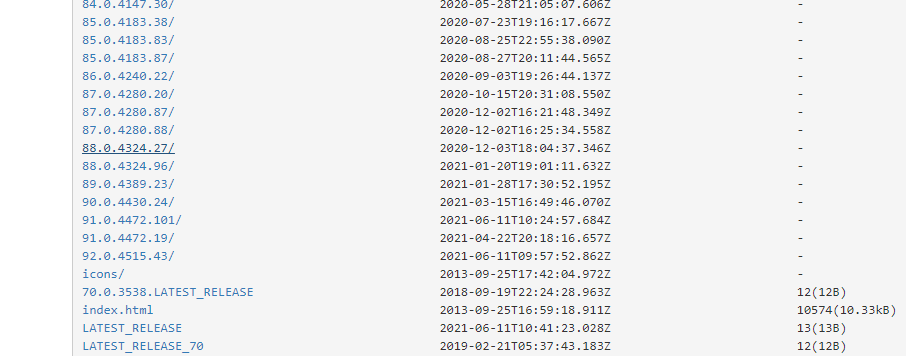
找一个和你版本一样或者差不多的版本下载
现在可以敲代码了
安装selenium模块
pip install selenium再导入模块,创建浏览器对象
# 浏览器功能
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.jd.com/')运行代码,可以操控浏览器自动打开你输入的网址
既然能自动的打开网页,那干脆来个全自动的搜索商品好了
def get_product(key):
"""商品搜索"""
driver.find_element_by_css_selector('#key').send_keys(key)
driver.find_element_by_css_selector('#search > div > div.form > button').click()
keyword = input('请输入商品搜索的关键字:')解析搜索商品的网页数据
def parse_data():
"""页面的数据解析"""
lis = driver.find_elements_by_css_selector('.gl-item') # 所有li标签
for li in lis:
try:
name = li.find_element_by_css_selector('div.p-name a em').text # 商品的名字
name = name.replace('京东超市', "").replace('"', '').replace('\n', '')
price = li.find_element_by_css_selector('div.p-price strong i').text + '元' # 商品的价格
deal = li.find_element_by_css_selector('div.p-commit strong a').text # 商品的评价数量
title = li.find_element_by_css_selector('span.J_im_icon a').get_attribute('title') # 商品的店铺名字
print(name, price, deal, title, sep=' | ')最后一步,就是保存数据了
import csv # 数据保存模块, 内置
with open('京东数据.csv', mode='a', encoding='utf-8', newline='') as f:
csv_write = csv.writer(f)
csv_write.writerow([name, price, deal, title])运行代码,效果如下图











