注意:本篇为50天后的Java自学笔记扩充,内容不再是基础数据结构内容而是机器学习中的各种经典算法。这部分博客更侧重与笔记以方便自己的理解,自我知识的输出明显减少,若有错误欢迎指正!
目录
2.M-distance算法的leave-one-out测试过程(核心)
3.1 平均绝对误差(Mean Abusolute Error: MAE)
3.2 均方根误差(Root Mean Square Error: RMSE)
· 第55天内容:补充实现user-based recommendation.
出处说明
今日的算法出自下面这篇老师和师姐共同发表的论文: Mei Zheng, Fan Min, Heng-Ru Zhang, Wen-Bin Chen, Fast recommendations with the M-distance, IEEE Access 4 (2016) 1464–1468. 点击下载论文.
一、算法简介
简单来说是一个推荐系统。假如当前系统是一个电影的评分与推荐系统,系统会为我们分析这个用户对于其他电影的评价情况来决策某个电影对于此用户的适合程度,并以评分表示。
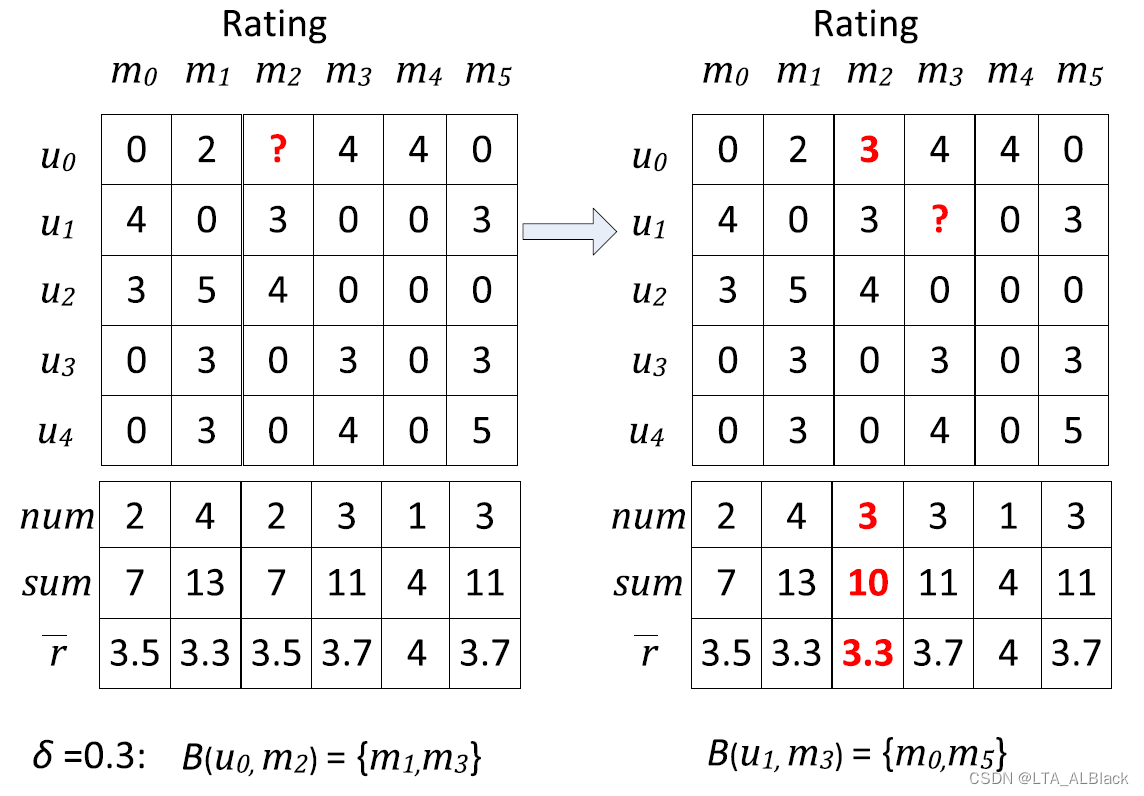
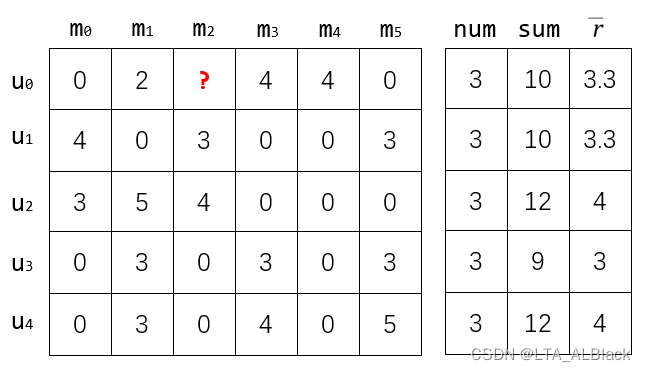
图例描述:这里是论文中的一个评分表,行表示这个用户对于一系列电影的评分情况,例如\(u_0\)所在行分别是\(\{4,0,3,0,0,3\}\),分别对应了用户\(u_0\)对于电影\(\{m_0,m_1,m_2,m_3,m_4,m_5\}\)的评价,纵列来看,可与理解为对于某部电影的不同用户评价。这里的0并不是评分为0而是,用户并没有看这部电影,因此电影列最下方的\(num\)表示了此电影的评价用户数目,\(sum\)为总数,而\(\bar r\)为平均数。
算法需要解决的问题:当我掩盖某个已经评分的内容(即上图中红色问号表示的数值),我是否可以通过这个问号周围的评分信息,对于这个评分进行一个预测?(遮住就相当于测试集大小为1,测试集大小为\(N-1\))
算法思路:类似于kNN,我们试着找被遮住点潜在的邻居,但是需要确定基于电影找邻居还是基于用户找邻居,并且确定邻居的指标是什么。
M-distance算法认为,某个点的邻居查找可以基于电影评分情况,即向量\(\vec m_i\);而查找的指标的话并不是计算向量\(\vec m_i\)与\(\vec m_j\)之间的欧氏距离或者曼哈顿距离,而是直接算算出每个向量的平均值\(\bar r\)(这里被遮住的部分不纳入平均值计算),判断过程中任意一个电影的平均评分与当前电影的平均评分的差值如果小于阈值\(\delta\) 的话,那么就将其选定为邻居。最终求邻居数组的平均值,即确定为测试集的预测值。
· leave-one-out
假设一次基本测试操作是任意一个数据选取出来作为测试集,然后其余数据作为训练集,以此对于测试集进行一次预测。然后leave-one-out就是依次遍历全部的测试集并都进行一次基本测试操作。因为往往来说,用于机器学习的数据样例\(N\)都是极其庞大的,而这种操作会对这个样例进行\(O(N^2)\)复杂度的基础操作,更别说每次操作的学习开销。所以只有足够高效的算法我们才会进行leave-one-out(或者数据量比较小?)
但是leave-one-out很公平!因为这里每个测试集的学习最大化了,能避免一些偶然情况。
· 一些值得注意的与kNN的差异
这个算法是kNN的一个变种但是却与kNN有些显然的差异
- 这里判断邻居是基于阈值\(\delta\) 的,这样的决断是合理的。因为在如此案例中,有的电影看人多有的少,若强行设置一个\(k\)有可能强迫纳入一些参考价值不大的电影,会干扰最终平均值的选取。而阈值\(\delta\)可以限定参考价值的尺度,本身就是基于参考价值的尺度的判断,因此更适用于这种情况。
- 不同于昨日的kNN,M-distance有明显的leave-one-out过程。因为每次学习的量非常小,只用对所有电影的评分的进行比对就好了,单次学习速度非常快,因此可以使用leave-one-out。
二、数据集准备与代码变量说明
评分表 (用户, 项目, 评分) 的压缩方式给出. 见 GitHub - FanSmale/sampledata: Sample data 中 movielens-943u1682m.txt.
大概内容是
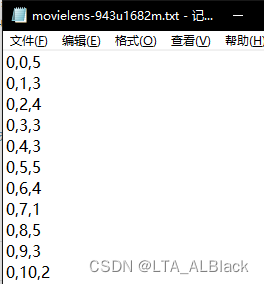
表现为存储稀疏图的三元表:
| User | Movie | Score |
| 0 | 0 | 5 |
| 0 | 1 | 3 |
| ... | ... | ... |
| 942 | 1329 | 3 |
一共有943个用户与1682部电影,每行表示一次可靠的评分,总共有10 0000个评分(行)
可见数据有效率只有 \(\frac{100000}{943 * 1682} = 0.063\),是典型的稀疏矩阵,这也是为什么我们的数据存储追求的是压缩存储。
/**
* Default rating for 1-5 points.
*/
public static final double DEFAULT_RATING = 3.0;
/**
* The total number of users.
*/
private int numUsers;
/**
* The total number of items.
*/
private int numItems;
/**
* The total number of ratings (non-zero values)
*/
private int numRatings;代码变量部分,依次是:
- 默认评分,当无法找到邻居的时候,会默认按照此评分,避免0分
- 用户数目,这里大小是943
- 项目数目,这里大小是1682
- 正常给出的评分个数,这里是100000
/**
* The predictions.
*/
private double[] predictions;
/**
* Compressed rating matrix. User-item-rating triples.
*/
private int[][] compressedRatingMatrix;
/**
* The degree of users (how many item he has rated).
*/
private int[] userDegrees;
/**
* The average rating of the current user.
*/
private double[] userAverageRatings;代码变量部分,依次是:
- predictions是大小为numRatings的数组,依次对每个leave-one-out选取的数据进行评分,因为正常评分有numRatings个,因此也要评分这么多。这里需要注意,这是一个将二维压缩成的一维数组
- compressedRatingMatrix是稀疏图三元组矩阵的直观存储,具体来说,是一个numRatings*3的矩阵
- userDegrees是某个用户看得电影数目,就我们最上面给出的图来说,userDegrees[2] = 3
- 某个用户打的所有评分的平均分,拿上图举例就是userAverageRatings[2] = \(\frac{3+5+4}{3}\)
/**
* The degree of users (how many item he has rated).
*/
private int[] itemDegrees;
/**
* The average rating of the current item.
*/
private double[] itemAverageRatings;
这两个属性类似于userDegrees与userAverageRatings,只不过视角不在行(\(\vec u\)),而在列(\(\vec m\))。依据电影向量的M-distance主要依靠这两个,上面图中所示的\(r_i\)就是itemAverageRatings。
/**
* The first user start from 0. Let the first user has x ratings, the second
* user will start from x.
*/
private int[] userStartingIndices;
/**
* Number of non-neighbor objects.
*/
private int numNonNeighbors;
/**
* The radius (delta) for determining the neighborhood.
*/
private double radius;userStartingIndices表示在压缩存储当中,第i个用户压缩数据的开始:
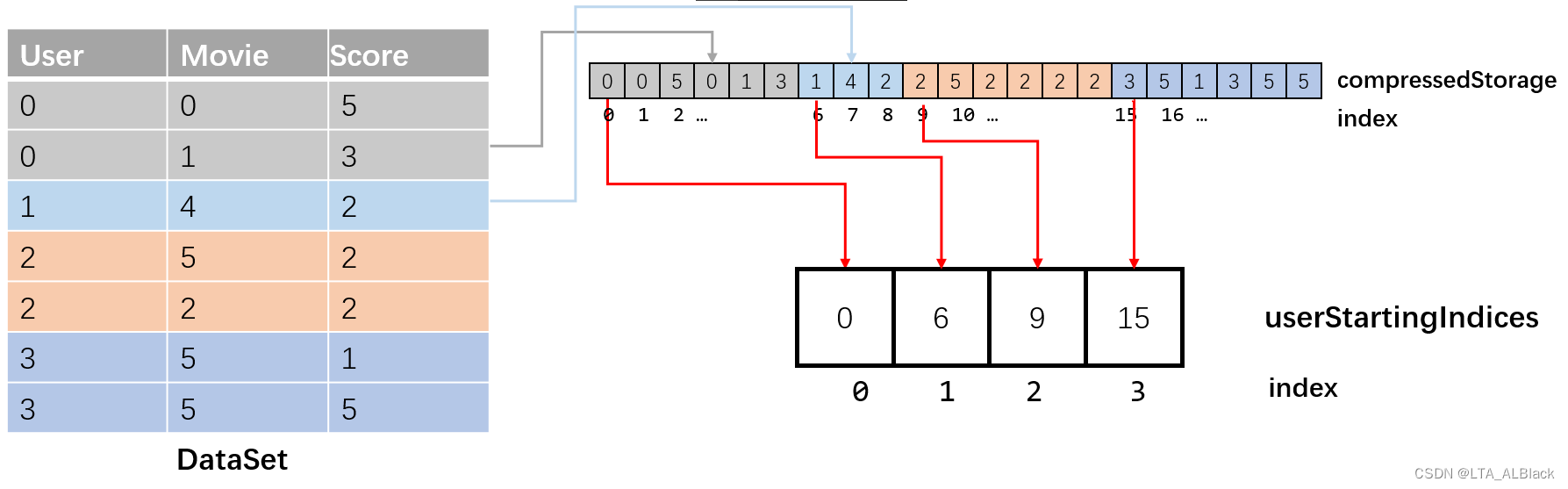
这个东西可以快速在压缩数组中找到我们希望寻找的用户,并且取出这个用户系列的评分(遍历这个用户评分时,以访问到下一个用户的开始下标为停止) 。因为一次评分间隔三元组,因此用户开始下标总是3的倍数,这是一个关键特征,因为我们可以通过用户开始下标除3得到三元组矩阵的行索引。
numNonNeighbors记录没有邻居的数据数目,针对这些特定数据我们将默认评分为DEFAULT_RATING;radius就是我们的预测半径,或者说阈值\(\delta\)。
三、代码详解
1.构造初始化
/**
*************************
* Construct the rating matrix.
*
* @param paraRatingFilename the rating filename.
* @param paraNumUsers number of users
* @param paraNumItems number of items
* @param paraNumRatings number of ratings
*************************
*/
public MBR(String paraFilename, int paraNumUsers, int paraNumItems, int paraNumRatings) throws Exception {
// Step 1. Initialize these arrays
numItems = paraNumItems;
numUsers = paraNumUsers;
numRatings = paraNumRatings;
userDegrees = new int[numUsers];
userStartingIndices = new int[numUsers + 1];
userAverageRatings = new double[numUsers];
itemDegrees = new int[numItems];
compressedRatingMatrix = new int[numRatings][3];
itemAverageRatings = new double[numItems];
predictions = new double[numRatings];
System.out.println("Reading " + paraFilename);
// Step 2. Read the data file.
File tempFile = new File(paraFilename);
if (!tempFile.exists()) {
System.out.println("File " + paraFilename + " does not exists.");
System.exit(0);
} // Of if
BufferedReader tempBufReader = new BufferedReader(new FileReader(tempFile));
String tempString;
String[] tempStrArray;
int tempIndex = 0;
userStartingIndices[0] = 0;
userStartingIndices[numUsers] = numRatings;
while ((tempString = tempBufReader.readLine()) != null) {
// Each line has three values
tempStrArray = tempString.split(",");
compressedRatingMatrix[tempIndex][0] = Integer.parseInt(tempStrArray[0]);
compressedRatingMatrix[tempIndex][1] = Integer.parseInt(tempStrArray[1]);
compressedRatingMatrix[tempIndex][2] = Integer.parseInt(tempStrArray[2]);
userDegrees[compressedRatingMatrix[tempIndex][0]]++;
itemDegrees[compressedRatingMatrix[tempIndex][1]]++;
if (tempIndex > 0) {
// Starting to read the data of a new user.
if (compressedRatingMatrix[tempIndex][0] != compressedRatingMatrix[tempIndex - 1][0]) {
userStartingIndices[compressedRatingMatrix[tempIndex][0]] = tempIndex;
} // Of if
} // Of if
tempIndex++;
} // Of while
tempBufReader.close();
double[] tempUserTotalScore = new double[numUsers];
double[] tempItemTotalScore = new double[numItems];
for (int i = 0; i < numRatings; i++) {
tempUserTotalScore[compressedRatingMatrix[i][0]] += compressedRatingMatrix[i][2];
tempItemTotalScore[compressedRatingMatrix[i][1]] += compressedRatingMatrix[i][2];
} // Of for i
for (int i = 0; i < numUsers; i++) {
userAverageRatings[i] = tempUserTotalScore[i] / userDegrees[i];
} // Of for i
for (int i = 0; i < numItems; i++) {
itemAverageRatings[i] = tempItemTotalScore[i] / itemDegrees[i];
} // Of for i
}// Of the first constructor
这部分代码不要看着长,其实就是对于txt文件的读取,然后按照我们构造的数据结构要求,将其存储于我们的数据结构中,都是很多基本操作的组合。
- 12~26行 因为输入的目标参数,故对于数组等数据结构的初始化
- 28~34行 常规的Java读文件代码。然后从40行开始解析读指针,逐行获取数据。
- 43~48行 完善三元组矩阵、某用户看电影数目的累加、某电影被多少用户所看的数目累加
- 50~56行 完善 “ 压缩矩阵中用户开始下标 ” 数组
- 60~72行 用以统计某用户全部评分的平均分、统计某电影全部评分的平均分。这里创建了临时数组tempUserTotalScore与tempItemTotalScore,通过遍历三元组矩阵来统计各用户与各电影的的总分。
2.M-distance算法的leave-one-out测试过程(核心)
先贴出全部代码:
/**
*************************
* Leave-one-out prediction. The predicted values are stored in predictions.
*
* @see predictions
*************************
*/
public void leaveOneOutPrediction() {
double tempItemAverageRating;
// Make each line of the code shorter.
int tempUser, tempItem, tempRating;
System.out.println("\r\nLeaveOneOutPrediction for radius " + radius);
numNonNeighbors = 0;
for (int i = 0; i < numRatings; i++) {
tempUser = compressedRatingMatrix[i][0];
tempItem = compressedRatingMatrix[i][1];
tempRating = compressedRatingMatrix[i][2];
// Step 1. Recompute average rating of the current item.
tempItemAverageRating = (itemAverageRatings[tempItem] * itemDegrees[tempItem] - tempRating)
/ (itemDegrees[tempItem] - 1);
// Step 2. Recompute neighbors, at the same time obtain the ratings
// Of neighbors.
int tempNeighbors = 0;
double tempTotal = 0;
int tempComparedItem;
for (int j = userStartingIndices[tempUser]; j < userStartingIndices[tempUser + 1]; j++) {
tempComparedItem = compressedRatingMatrix[j][1];
if (tempItem == tempComparedItem) {
continue;// Ignore itself.
} // Of if
if (Math.abs(tempItemAverageRating - itemAverageRatings[tempComparedItem]) < radius) {
tempTotal += compressedRatingMatrix[j][2];
tempNeighbors++;
} // Of if
} // Of for j
// Step 3. Predict as the average value of neighbors.
if (tempNeighbors > 0) {
predictions[i] = tempTotal / tempNeighbors;
} else {
predictions[i] = DEFAULT_RATING;
numNonNeighbors++;
} // Of if
} // Of for i
}// Of leaveOneOutPrediction然后细看一些细节:
tempUser = compressedRatingMatrix[i][0];
tempItem = compressedRatingMatrix[i][1];
tempRating = compressedRatingMatrix[i][2];
// Step 1. Recompute average rating of the current item.
tempItemAverageRating = (itemAverageRatings[tempItem] * itemDegrees[tempItem] - tempRating) / (itemDegrees[tempItem] - 1);首先在获取了本回合的针对用户、针对电影、标准评分(修改前)之后,将其作为我们的测试数据(也就是所谓的掩盖住这个数据,将其变成未知数据,并对它预测)。在这之前需要得到修改它为未知数据之后,它平均数\(r\)的变化。itemAverageRatings[tempItem] * itemDegrees[tempItem],即电影的平均分 * 电影评分个数,得到的是这个电影的原总分。然后减去评分tempRating,即得到掩盖掉用户tempUser评价之后的电影总评分,最后除以-1的人数,即得到了掩盖掉用户tempUser的评价之后电影tempItem的评分。这是一个简单的数学题。
// Step 2. Recompute neighbors, at the same time obtain the ratings
// Of neighbors.
int tempNeighbors = 0;
double tempTotal = 0;
int tempComparedItem;
for (int j = userStartingIndices[tempUser]; j < userStartingIndices[tempUser + 1]; j++) {
tempComparedItem = compressedRatingMatrix[j][1];
if (tempItem == tempComparedItem) {
continue;// Ignore itself.
} // Of if
if (Math.abs(tempItemAverageRating - itemAverageRatings[tempComparedItem]) < radius) {
tempTotal += compressedRatingMatrix[j][2];
tempNeighbors++;
} // Of if
} // Of for j然后就是kNN的思想,找邻居来预测。在压缩的三元组里面怎么照邻居?
首先明白在我们这个User-Movie稀疏矩阵中谁是潜在的邻居:
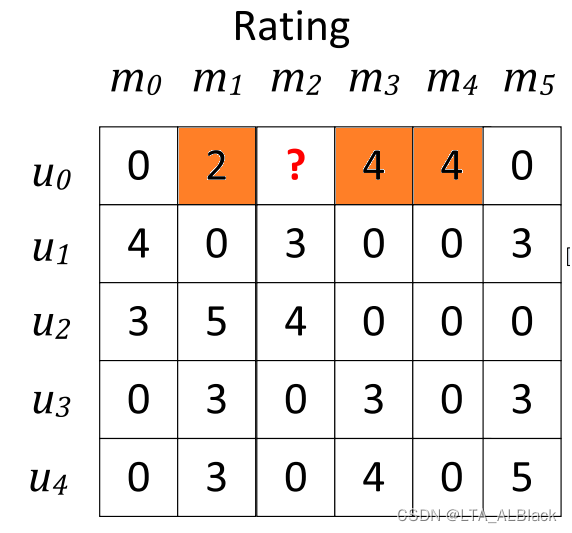
当把\((u_0,m_2)\)给设置为测试对象后,基于电影来预测,那么此用户没用看过的电影就不应当纳入预测,只有那些这个用户看过的电影才能作为潜在邻居,所以我们应当遍历这个稀疏矩阵的第\(u_0\)行中所有参与了评分的元素。
怎么遍历呢?三元压缩存储到压缩的过程如下:

可见 “ 第\(u_0\)行中所有参与了评分的元素 ”就是三元组矩阵的灰色部分,在压缩存储中,这部分元素夹在当前\(u_0\)用户首次在压缩存储中出现的下标与下一个用户\(u_1\)之间。所以得出了下面这样的for循环。
if (Math.abs(tempItemAverageRating - itemAverageRatings[tempComparedItem]) < radius) {
tempTotal += compressedRatingMatrix[j][2];
tempNeighbors++;
} // Of if然后判断平均数的差,并与阈值比较;当小于阈值时判断为合格的邻居,统计邻居的分数。
执行完上面的循环之后,基本统计了邻居的总分,由此计算邻居平均值作为估计分(无邻居则设置缺省值):
// Step 3. Predict as the average value of neighbors.
if (tempNeighbors > 0) {
predictions[i] = tempTotal / tempNeighbors;
} else {
predictions[i] = DEFAULT_RATING;
numNonNeighbors++;
} // Of if3.算法的评价指标
3.1 平均绝对误差(Mean Abusolute Error: MAE)
所谓的误差,即我们对于已知的一个User-Movie稀疏图中的一个数据\(M(u_i,m_j) = x\),将其设置为一个未知的测试集,做leave-one-out的预测,最终预测出结果\(P(u_i,m_j) = y\),那么误差就是\(E_{i,j} = |x-y|\)。于是平均绝对误差(Mean Abusolute Error)的可定义为一个基本的算术平均(\(u表示用户数,m表示电影数\)):\[MAE = \frac{\sum_{i=1}^{u}\sum_{i=1}^{m} E_{i,j}}{um}\]
/**
*************************
* Compute the MAE based on the deviation of each leave-one-out.
*
* @author Fan Min
*************************
*/
public double computeMAE() throws Exception {
double tempTotalError = 0;
for (int i = 0; i < predictions.length; i++) {
tempTotalError += Math.abs(predictions[i] - compressedRatingMatrix[i][2]);
} // Of for i
return tempTotalError / predictions.length;
}// Of computeMAEpredictions[i]中存入的是我们的预测集,相当于我上面的\(P(u_i,m_j) = y\),只不过因为它的逻辑表示是压缩存储结构,所以这里的下标\(i\)是算式中\(i\)与\(j\)的融合。
3.2 均方根误差(Root Mean Square Error: RMSE)
思路是一样的,只不过换了一种评价方案而已,计算如下:\[RMSE = \sqrt \frac{\sum_{i=1}^{u}\sum_{i=1}^{m} E_{i,j}^2}{um}\]
/**
*************************
* Compute the RSME based on the deviation of each leave-one-out.
*
* @author Fan Min
*************************
*/
public double computeRSME() throws Exception {
double tempTotalError = 0;
for (int i = 0; i < predictions.length; i++) {
tempTotalError += (predictions[i] - compressedRatingMatrix[i][2])
* (predictions[i] - compressedRatingMatrix[i][2]);
} // Of for i
double tempAverage = tempTotalError / predictions.length;
return Math.sqrt(tempAverage);
}// Of computeRSMEMAE能很好反映误差的实际情况,而RMSE主要是反映同真实值之间的偏差,一般来说MAE值要比RMSE小得多,突然的峰值异常值将会对于RMSE照成较大的影响,而MAE能相对稳定。
四、运行测试与数据分析
主函数部分:
/**
*************************
* The entrance of the program.
*
* @param args Not used now.
*************************
*/
public static void main(String[] args) {
try {
MBR tempRecommender = new MBR("D:/Java DataSet/movielens-943u1682m.txt", 943, 1682, 100000);
for (double tempRadius = 0.2; tempRadius < 0.6; tempRadius += 0.1) {
tempRecommender.setRadius(tempRadius);
tempRecommender.leaveOneOutPrediction();
double tempMAE = tempRecommender.computeMAE();
double tempRSME = tempRecommender.computeRSME();
System.out.println("Radius = " + tempRadius + ", MAE = " + tempMAE + ", RSME = " + tempRSME
+ ", numNonNeighbors = " + tempRecommender.numNonNeighbors);
} // Of for tempRadius
} catch (Exception ee) {
System.out.println(ee);
} // Of try
}// Of main
}// Of class MBR在主函数中我们枚举了0.2、0.3、0.4、0.5四种阈值,并分别进行leave-one-out测试,然后输出两个评价指标。得到输出结果:
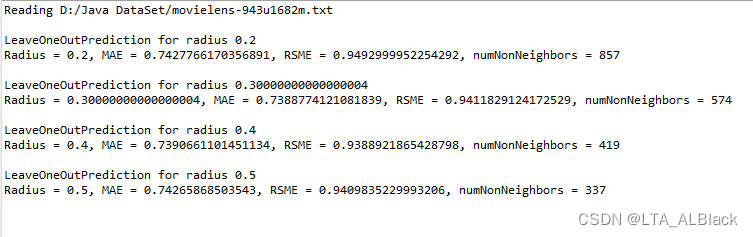

简单来看,MAE与RSME评价指标下,若阈值变化范围不大时,误差值都相对稳定在一个比较低的范围,上面这个图是主函数中的表示。若夸大循环的范围,阈值的限制变得宽松时,更多不恰当的电影推荐了进来后,误差值便逐步提高。但是从这个图也能发现一个细节,并不是一定地说阈值是越小越好,此图在阈值介于0.25到0.5之间有非常明显的偏差局部最小,有不显著的单调减区间。据我个人推测来看,有可能是过小的阈值导致忽略了某些关键电影,而这些电影冥冥之中可能与我们原本的标准数据有较强关联性。
同时也能了解一个现象,RSME虽然相比于MAE,值会更大一些,可以有利于放大一些不显著的特征,便于分析以及发现数据的进步空间。

整个算法的复杂度非常明显,leave-one-out照成了有效评分的双循环,而每次分析邻居需要耗时最多\(O(M)\)(\(M\)为电影数目),而单次分析邻居只需要\(O(1)\)复杂度。因此,总的复杂度为\(O(MN^2)\)(N为有效评分总数)。
· 第55天内容:补充实现user-based recommendation.
1.思维转变
昨天我们实现的是基于电影平均分的预测,也就基于向量\(\vec m_i\)的评分(看列),这是 item-based recommendation。而今天改变思路,实现user-based recommendation。算法思路是一样,只不过我们比对的平均数和邻居的选择不同了。
仍随机掩住一个\((u_i,m_j)\)设置为未知量,但是这次选邻居我们是选择同一部电影的所有给出评分的观众,在这些潜在邻居——给出评分的观众里面选择 给所有电影的评分总平均 最接近的预测数据平均数的 观众。其实就是将原来看列向量选定邻居变为看行向量选择邻居。
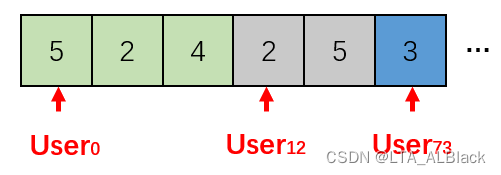
那么这个怎么压缩呢,这个就不能像item-based recommendation那样直接读我们的数据集了,因为我们的数据(见下txt文档)是基本按照用户编号进行排序的。
对于User * Movie的稀疏矩阵,那么我们的数据在逻辑上就是先行(用户)后列(电影)排列的。举个鲜明的例子吧,如果我们的三元组表是:
0 0 5
0 7 2
0 120 4
12 0 2
12 50 5
73 0 3
...那么顺序访问的话,就是按照下图这样先行后列地遍历

若按照这样设置压缩存储,那么同个用户的数据一定是连续的,而同一部电影一定不连续。这就是我们设置 用户开始下标数组 的原因
若现在我们要更方便取得同一部电影的全部评分,而非一个用户的全部评分,那么就要改变策略,变为行优先。如何做呢?其实只要改变我们默认数据的排序规则就好了:比如我刚刚举的这个三元组数据的例子,我来按照电影标号将其排序:
0 0 5
12 0 2
73 0 3
0 7 2
12 50 5
0 120 4
...排序规则变为先按照第二列排序,最后再按照第一列排序。这样顺序读取就变成了先列(电影)后行(用户)的排序规则,这样体现在细数图上的遍历会是什么样的呢?
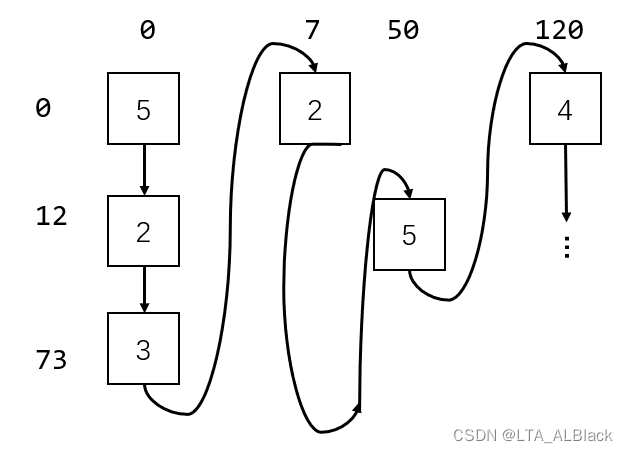
果然实现了列优先的遍历,也是因为实现了先列存储,所以同一部电影的评分都是连续的了,所以压缩存储之后就可以非常容易设置 电影开始下标 数组。这样在得到某个未知评分之后就能很快取出这个评分所在的列。

上述的这个过程有个大家都非常熟悉的名称:转置!
因此,我们就得到实现item-based recommendtion的方案简图:
先得到按照用户优先的三元组表,然后按照电影列优先对于表进行重排,然后照常读取这个表进行压缩存储即可,但是要注意这个过程中一些细节变量的改换使用!
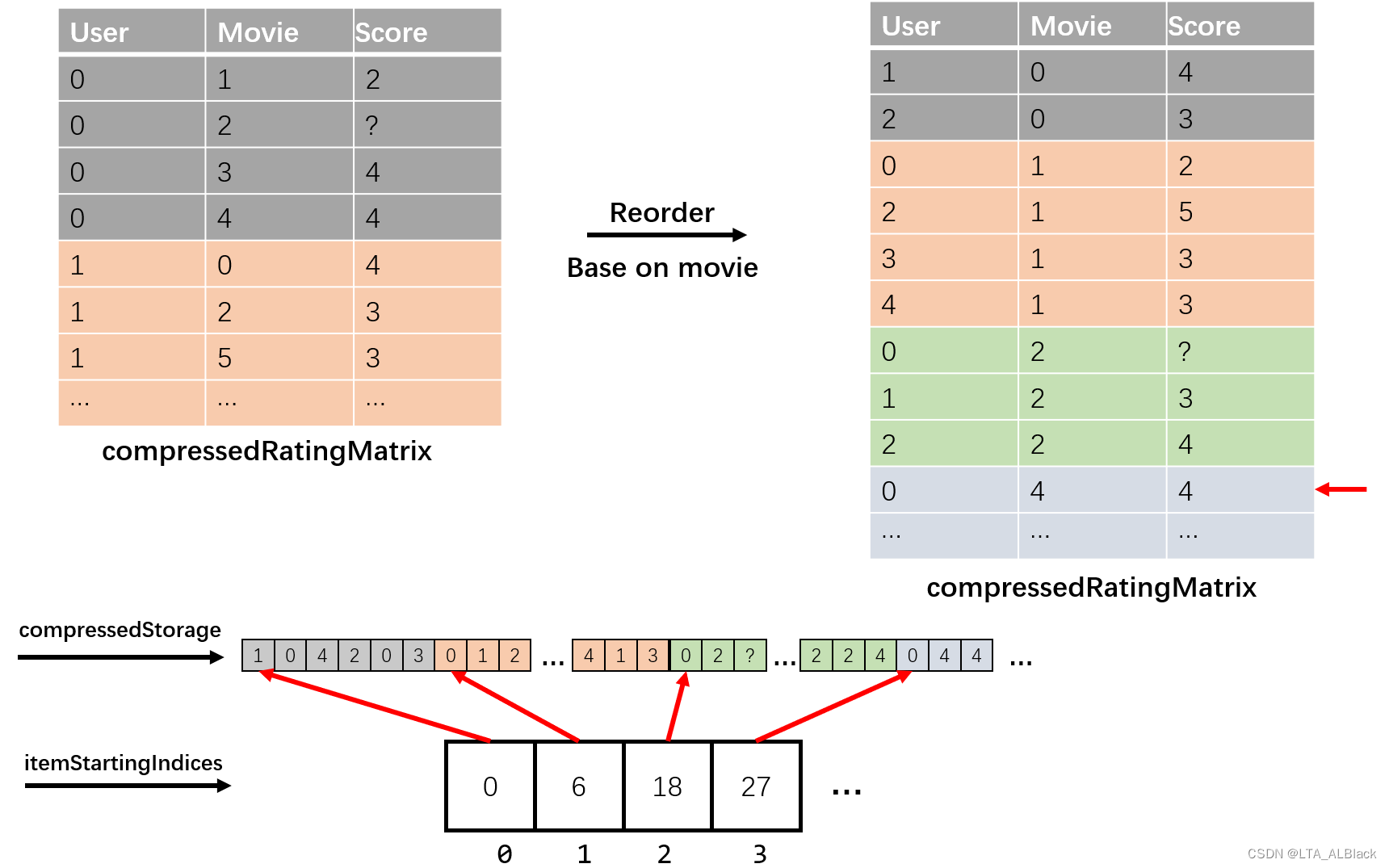
2.重写的构造函数
/**
*************************
* Construct the rating matrix.
*
* @param paraRatingFilename the rating filename.
* @param paraNumUsers number of users
* @param paraNumItems number of items
* @param paraNumRatings number of ratings
*************************
*/
public MBR_userBased(String paraFilename, int paraNumUsers, int paraNumItems, int paraNumRatings) throws Exception {
// Step 1. Initialize these arrays
numItems = paraNumItems;
numUsers = paraNumUsers;
numRatings = paraNumRatings;
userDegrees = new int[numUsers];
itemStartingIndices = new int[numItems + 1];
userAverageRatings = new double[numUsers];
itemDegrees = new int[numItems];
compressedRatingMatrix = new int[numRatings][3];
itemAverageRatings = new double[numItems];
predictions = new double[numRatings];
System.out.println("Reading " + paraFilename);
// Step 2. Read the data file.
File tempFile = new File(paraFilename);
if (!tempFile.exists()) {
System.out.println("File " + paraFilename + " does not exists.");
System.exit(0);
} // Of if
BufferedReader tempBufReader = new BufferedReader(new FileReader(tempFile));
String tempString;
String[] tempStrArray;
int tempIndex = 0;
// Step 3. Read the data to compressedRatingMatrix and reorder
while ((tempString = tempBufReader.readLine()) != null) {
// Each line has three values
tempStrArray = tempString.split(",");
compressedRatingMatrix[tempIndex][0] = Integer.parseInt(tempStrArray[0]);
compressedRatingMatrix[tempIndex][1] = Integer.parseInt(tempStrArray[1]);
compressedRatingMatrix[tempIndex][2] = Integer.parseInt(tempStrArray[2]);
userDegrees[compressedRatingMatrix[tempIndex][0]]++;
itemDegrees[compressedRatingMatrix[tempIndex][1]]++;
tempIndex++;
} // Of while
tempBufReader.close();
// Reorder based on items
Arrays.sort(compressedRatingMatrix, new Comparator<int[]>() {
@Override
public int compare(int[] o1, int[] o2) {
if (o1[1] == o2[1])
return o1[0] - o2[0];
return o1[1] - o2[1];
}// Of compare
});
// Step 4. Create Compressed Storage
itemStartingIndices[0] = 0;
itemStartingIndices[numItems] = numRatings;
for (int k = 1; k < numRatings; k++) {
// Starting to read the data of a new user.
if (compressedRatingMatrix[k][1] != compressedRatingMatrix[k - 1][1]) {
itemStartingIndices[compressedRatingMatrix[k][1]] = k;
} // Of if
} // Of while
// Step 5. Calculate the average
double[] tempUserTotalScore = new double[numUsers];
double[] tempItemTotalScore = new double[numItems];
for (int i = 0; i < numRatings; i++) {
tempUserTotalScore[compressedRatingMatrix[i][0]] += compressedRatingMatrix[i][2];
tempItemTotalScore[compressedRatingMatrix[i][1]] += compressedRatingMatrix[i][2];
} // Of for i
for (int i = 0; i < numUsers; i++) {
userAverageRatings[i] = tempUserTotalScore[i] / userDegrees[i];
} // Of for i
for (int i = 0; i < numItems; i++) {
itemAverageRatings[i] = tempItemTotalScore[i] / itemDegrees[i];
} // Of for i
}// Of the first constructor注意!因为要重排数据,所以这将原来是一个循环完成的读数据(Step 3)与压缩存储(Step 4)操作分开了。重排代码见下:
// Reorder based on items
Arrays.sort(compressedRatingMatrix, new Comparator<int[]>() {
@Override
public int compare(int[] o1, int[] o2) {
if (o1[1] == o2[1])
return o1[0] - o2[0];
return o1[1] - o2[1];
}// Of compare
});3.重写的leave-one-out的测试代码
/**
*************************
* Leave-one-out prediction. The predicted values are stored in predictions.
*
* @see predictions
*************************
*/
public void leaveOneOutPrediction() {
double tempItemAverageRating;
// Make each line of the code shorter.
int tempUser, tempItem, tempRating;
System.out.println("\r\nLeaveOneOutPrediction for radius " + radius);
numNonNeighbors = 0;
for (int i = 0; i < numRatings; i++) {
tempUser = compressedRatingMatrix[i][0];
tempItem = compressedRatingMatrix[i][1];
tempRating = compressedRatingMatrix[i][2];
// Step 1. Recompute average rating of the current item.
tempItemAverageRating = (userAverageRatings[tempUser] * userDegrees[tempUser] - tempRating)
/ (userDegrees[tempUser] - 1);
// Step 2. Recompute neighbors, at the same time obtain the ratings
// Of neighbors.
int tempNeighbors = 0;
double tempTotal = 0;
int tempComparedUser;
for (int j = itemStartingIndices[tempItem]; j < itemStartingIndices[tempItem + 1]; j++) {
tempComparedUser = compressedRatingMatrix[j][0];
if (tempUser == tempComparedUser) {
continue;// Ignore itself.
} // Of if
if (Math.abs(tempItemAverageRating - userAverageRatings[tempComparedUser]) < radius) {
tempTotal += compressedRatingMatrix[j][2];
tempNeighbors++;
} // Of if
} // Of for j
// Step 3. Predict as the average value of neighbors.
if (tempNeighbors > 0) {
predictions[i] = tempTotal / tempNeighbors;
} else {
predictions[i] = DEFAULT_RATING;
numNonNeighbors++;
} // Of if
} // Of for i
}// Of leaveOneOutPrediction
原方法中没有使用的用户数目userDegrees与用户平均数userAverageRatings在这个成为了计算的主角,思路没变,只是压缩数组的下标访问变量变了,许多基于列的操作改为基于行的即可。
4.数据测试
修改了之后测试输出如下:


就数据量比较小来看,基本上基于用户的推荐与基于电影的推荐是平行的,这是由类似的方法所决定的。从值上来看,基于用户推荐的误差会高一些。可能的原因是用户的数目(943)要小于电影数目(1682)的原因,在基于用户的推荐系统中,用户少则学习样本量更少,学习的量可能不完全精确。

有趣的地方在于当我们把数据量扩大后,基于用户评判的推荐系统似乎在对于阈值宽松环境下误差率上升率并没有强于基于电影的推荐系统,甚至在高阈值(推荐系统推荐限制低)的环境下,使用样本更少的基于用户的推荐系统能有更低的误差。也许这与用户样本量少的偶发性有一定的关系?或者说更少的样本基数也降低了不满足预测评分的错误评分的个数,从而避免了误差不会上升得很快?









