目录
Spark
Spark的特点?
Spark具备的能力
spark与Hadoop的异同?
Spark的应用场景
Spark的生态系统
spark的构架和原理
spark架构设计
spark的作业流程
核心原理
每文一语
Spark
Spark的特点?
Spark首先是一个大规模数据处理的统一分析引擎,它是类与Hadoop MapReduce的通用并行框架,专门为大数据处理的一个快速计算引擎。如果说Hadoop是大数据的第一把利剑,那么毫无疑问spark就是大数据分析与计算的第二把利剑,spark具有下面四个特点:
快速: 在相同的实验环境下处理相同的数据,若在内存中运行,那么Spark要比MapReduce快100倍(只是在逻辑回归测试中)。
通用:Spark 是一个通用引擎,可用它来完成各种运算,包括 SQL 查询、文本处理、机器学习、实时流处理等。我们之前花费大量的时间去学习SQL的规范与语法,就是为了在后面有更好的突破和发展。
易用:Spark提供了高级 API,应用开发者只用专注于应用计算本身即可,而不用关注集群本身,这使得Spark更简单易用。至于提供了高级的API,那么我们知道Python是一个胶水语言,一般在智能的分析里面我们还是要利用Python的特性,提供pyspark这个模块进行我们更加快速方便的操作。
兼容性好:Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。
Spark具备的能力
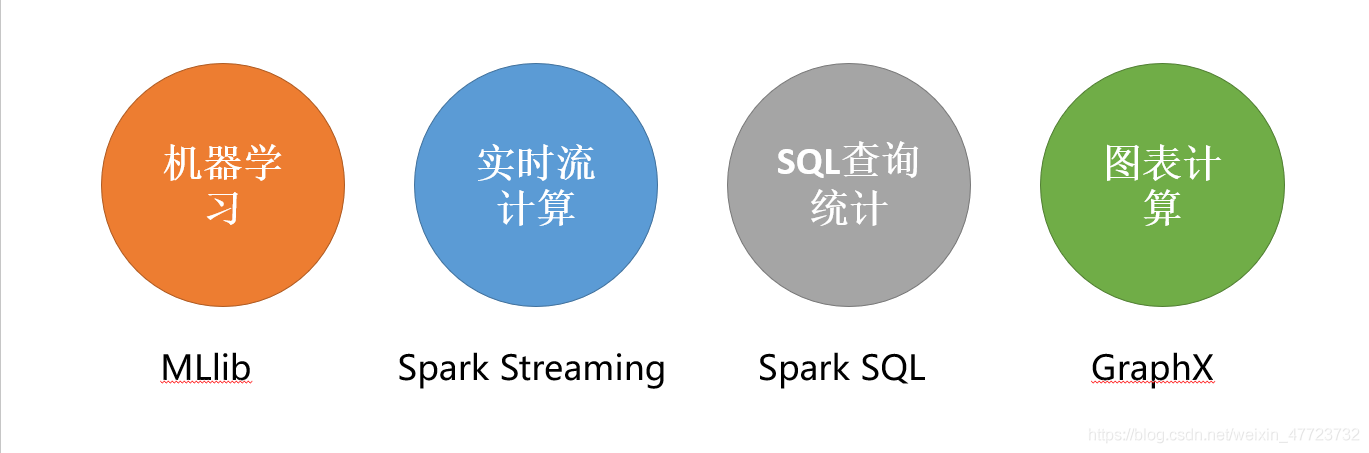
说实话spark在这些领域能够具有不一般的地位,在于时代的需要和发展,任何一个产品如果不适应时代的需要,那么即使它拥有非常好的资源也终究会时间淘汰。
spark与Hadoop的异同?
我们都知道Hadoop,之前我们也介绍了在Hadoop里面处理大量的数据进行分析,Hadoop也可以,那么spark和Hadoop究竟有些什么不一样呢?
1.首先解决问题方式不一样
首先,Hadoop和Apache Spark两者都是大数据框架,但是各自的属性和性能却不完全相同。Hadoop实质上更多是一个分布式数据基础设施。它将巨大的数据集分派到一个由普通计算机组成的集群中的多个节点进行存储,意味着我们不需要购买和维护昂贵的服务器硬件。同时,Hadoop还会排序和追踪这些数据,这使得大数据处理和分析效率更加迅速。在之前我们的Hadoop的实验里面我们也发现这个问题,但是处理速度,确实有点不尽人意,每次执行查询的时候都进行MapReduce的过滤和分析,时间上还是浪费了许多。
Spark则是一个专门的,用来对那些分布式存储的大数据进行处理的工具,但它并不会进行分布式数据的存储。
2.Hadoop与spark可谓珠联璧合
Hadoop不仅提供了从前的 HDFS分布式数据存储功能之外,而且提供了叫做MapReduce的数据处理的功能。所以我们可以不使用Spark,而选择使用Hadoop自身的MapReduce来对数据进行处理。这个当然是可以的,但是我们了解了spark之后就会选择在不同的场景下进行不同的选择和应用,不然也没有必要的去了解这个产品。
同样的,Spark也不一定需要依附在Hadoop系统中。但如上所述,毕竟它没有提供文件管理系统,所以,它需要和其他的分布式文件系统先进行集成然后运作。这里我们可以选择一些基于云的数据系统平台进行操作。
3.spark某些方面比Hadoop更胜一筹
①它可以把中间结果放在内存!Hadoop却不能,这就是Hadoop执行每次任务较慢的重要原因之一:基于MapReduce的计算模型会将中间结果序列化到磁盘上。而Spark将执行模型抽象为通用的有向无环图执行计划。且可以将中间结果缓存内存中。
②自动布局和数据格式转换:Spark抽象出分布式内存存储结构,即弹性分布式数据集RDD(Resilient Distributed Datasets)进行数据存储。Spark能够控制数据在不同节点上的分区,用户可以自定义分区策略。
③执行策略高:MapReduce在数据shuffle之前总是花费大量时间来排序。Spark支持基于Hash的分布式聚合,在需要的时候再进行实际排序。
④任务调度可以减少:MapReduce上的不同作业在同一个节点运行时,会各自启动一个JVM。而Spark同一节点的所有任务都可以在一个JVM上运行。
其实我们也不能光否定Hadoop,一味地去夸spark,Hadoop也是基于内存计算,Spark只是把计算过程中间的结果缓存在内存中。Spark只是在逻辑回归测试时候速度比Hadoop快了100倍,其他算法不一定。这个是需要我们注意的,并不是所有的算法都是这样。
Spark的应用场景
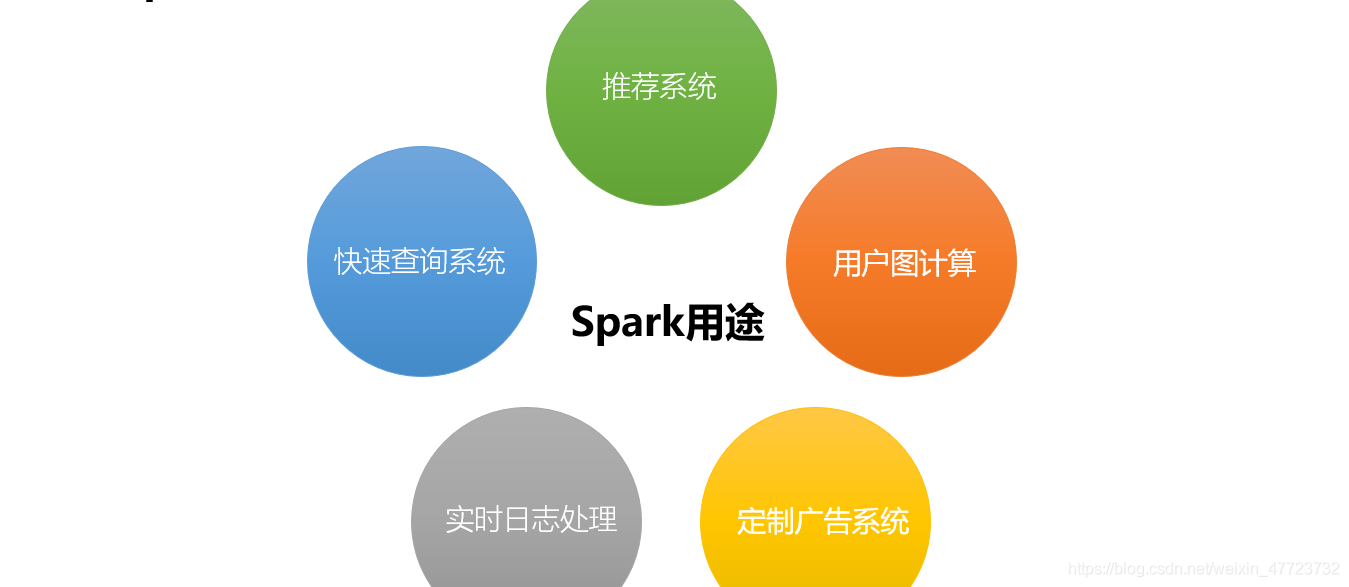
Spark使用了内存分布式数据集,除了能够提供交互式查询外,它还提升了迭代工作负载的功能,在Spark SQL、Spark Streaming、MLlib、GraphX中都有自己一定的子项目。在互联网领域,Spark有快速查询、实时日志采集处理、业务推荐、定制广告、用户图计算等强大功能。国内外的一些大公司,比如Google、阿里巴巴、Intel、网易、科大讯飞等都有实际业务运行在Spark平台上。下面简要说明Spark在各个领域中的用途。

Spark的生态系统
我们都知道一个技术产品的生态系统的好坏决定了这个技术产品未来的走势和发展,那么spark的生态系统是怎么样的?下面我们就来看看
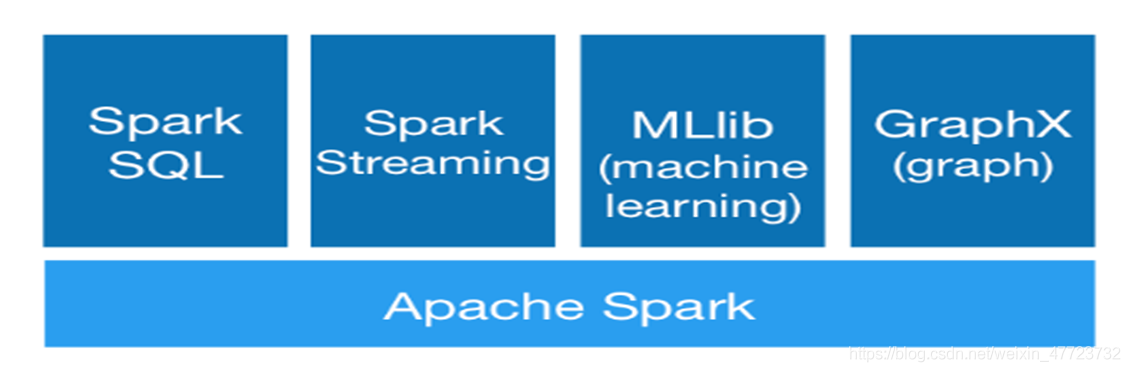
Spark 生态系统以Spark Core 为核心,利用Standalone、YARN 和Mesos 等资源调度管理,完成应用程序分析与处理。这些应用程序来自Spark 的不同组件,如Spark Shell 或Spark Submit 交互式批处理方式、Spark Streaming 的实时流处理应用、Spark SQL 的即席查询、MLlib 的机器学习、GraphX 的图处理等。
spark的构架和原理
spark架构设计
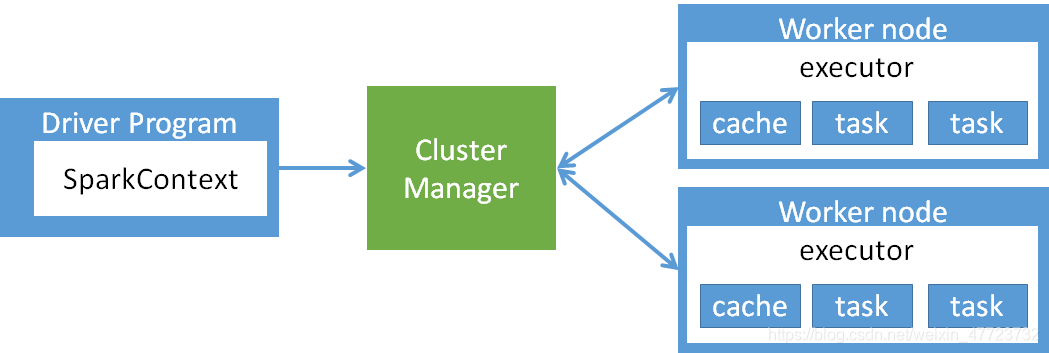
(1)Cluster Manager:Spark的集群管理器,主要负责资源的分配与管理。集群管理器分配的资源属于一级分配,它将各个Worker上的内存、CPU等资源分配给应用程序,但是并不分配Executor的资源。目前,Standalone、YARN、Mesos、EC2等都可以作为Spark的集群管理器。
(2)Worker:Spark的工作节点。对Spark应用程序来说,由集群管理器分配得到资源的Worker节点主要负责以下工作:创建Executor,将资源和任务进一步分配给Executor,然后同步资源信息给Cluster Manager。
(3)Executor:执行计算任务的一线进程。主要负责任务的执行以及与Worker、Driver App的信息同步。
(4)Driver Program:客户端驱动程序,也可以理解为客户端应用程序,用于将任务程序转换为RDD和DAG,并与Cluster Manager进行通信与调度。
其实说了这么多可能你还是不够了解这个,但是我们再来看看这个你就看明白了
Master进程和Worker进程,对整个集群进行控制。
Driver 程序是应用逻辑执行的起点,负责作业的调度,即Task任务的分发
Worker用来管理计算节点和创建Executor并行处理任务。
Executor对相应数据分区的任务进行处理。
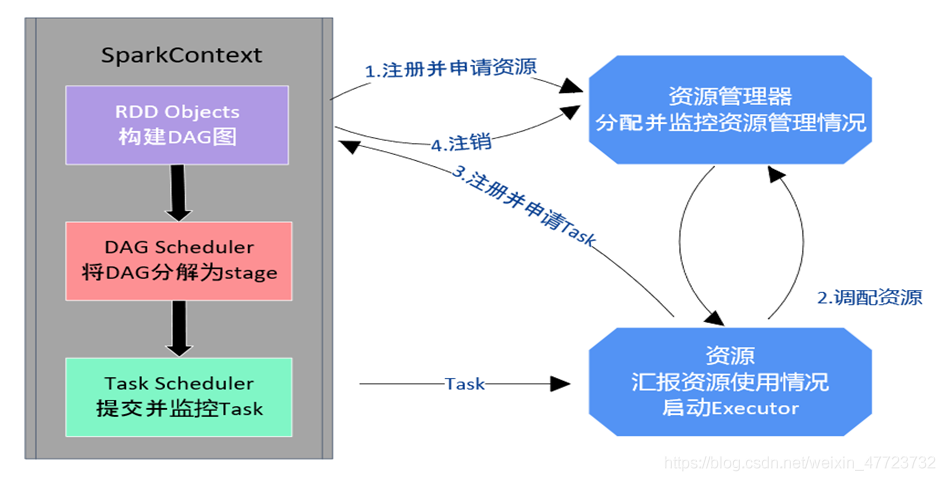
spark的作业流程
(1)构建Spark Application的运行环境,启动SparkContext。
(2)SparkContext向资源管理器(可以是Standalone,Mesos,Yarn)申 请运行Executor资源。
(3)Executor向SparkContext申请Task。
(4)SparkContext将应用程序分发给Executor。
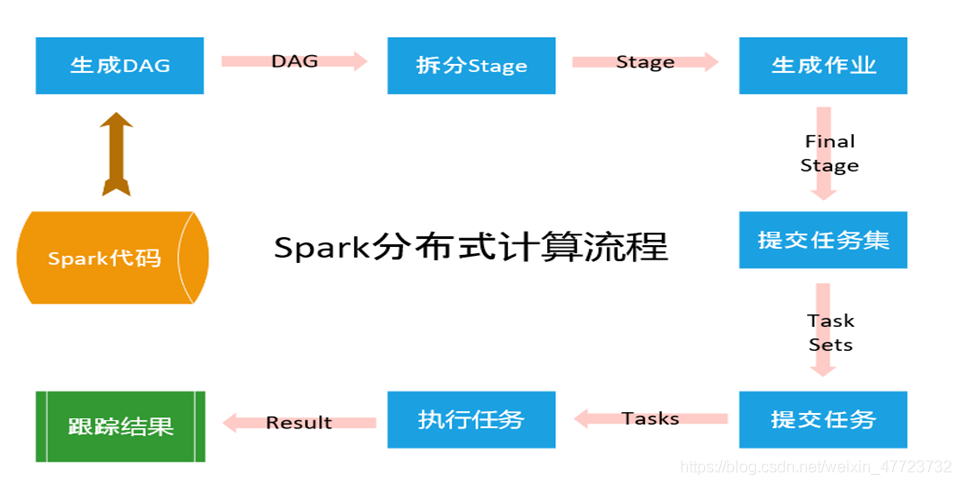
(5)SparkContext构 建成DAG图( Directed Acyclic Graph有向无环图),将DAG图分解成Stage、将Taskset发送给Task Scheduler,最后由Task Scheduler将Task发送给Executor运行。
(6)Task在Executor上运行,运行完释放所有资源。
核心原理
还是那句话工欲善其事必先利其器,本专栏使用的是spark2.X版本的,具有很好地效果
每文一语
底线,是有所为有所不为!
