项目场景:
提示:这里简述项目相关背景:最近ETL数据处理中需要把100多个excel导入的数据库(MySQL),但是excel的列是不一样的,如果手工粘贴的话,需要很多时间还可能遗漏。
例如:项目场景:示例:通过蓝牙芯片(HC-05)与手机 APP 通信,每隔 5s 传输一批传感器数据(不是很大)
这些数据大小是200M内,100万行内
问题描述
提示:这里描述项目中遇到的问题:文件列数不同,且需要转换
例如:这个16列的
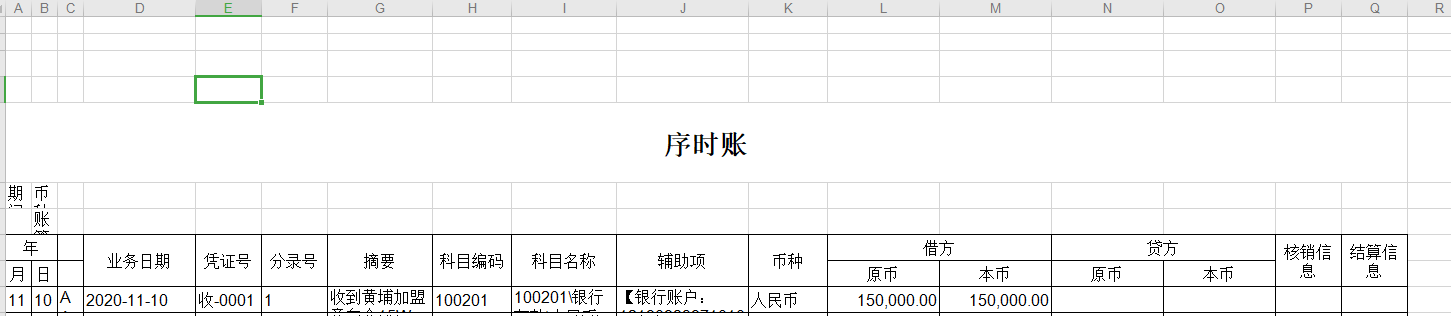
这个是17列的

同时还有其它列数的文件,这里不再列出
解决方案:
1 获取数据文件
def get_file_path(rootfile, file_list: list, dir_list: list):
"""
获取指定路径下的所有文件
:param rootfile: 指定文件夹
:param file_list: 文件夹下的文件夹列表
:param dir_list: 文件夹下的文件列表
"""
dir_or_files = os.listdir(rootfile)
for dir_file in dir_or_files:
dir_file_path = os.path.join(rootfile, dir_file)
if os.path.isdir(dir_file_path):
file_list.append(dir_file_path)
get_file_path(dir_file_path, file_list, dir_list)
else:
dir_list.append(dir_file_path)
2 数据处理
数据处理包括,列名修改,数据过滤,添加列
def getDateFrame(filename):
"""
获取文件对应的dataframe
:param filename: 需要读取的文件名
:return: 处理后的dataframe
"""
# 读取文件
excelfile = pd.read_excel(filename, sheet_name='新的工作表', engine='xlrd')
# 对不同列数据进行转换
if excelfile.columns.size == 16:
# 修改列名
cdf = excelfile.rename(columns={'Unnamed: 0': '月'
, 'Unnamed: 1': '日'
, 'Unnamed: 2': '业务日期'
, 'Unnamed: 3': '凭证号'
, 'Unnamed: 4': '分录号'
, 'Unnamed: 5': '摘要'
, 'Unnamed: 6': '科目编码'
, 'Unnamed: 7': '科目名称'
, 'Unnamed: 8': '辅助项'
, 'Unnamed: 9': '币种'
, 'Unnamed: 10': '借方原币'
, 'Unnamed: 11': '借方本币'
, 'Unnamed: 12': '贷方原币'
, 'Unnamed: 13': '贷方本币'
, 'Unnamed: 14': '核销信息'
, 'Unnamed: 15': '结算信息'})
# 过滤指定数据
dcfs = cdf[cdf["币种"].isin(['人民币', '港币', '美元', '欧元'])].copy()
# 添加特定列
dcfs.loc[:, '业务主体'] = str.split(filename, '\\')[3]
# 返回数据dataframe
return dcfs[["业务日期", "凭证号", "科目编码", "科目名称","币种", "借方原币", "借方本币", "贷方原币", "贷方本币", "业务主体"]]
if excelfile.columns.size == 17:
cdf = excelfile.rename(columns={'Unnamed: 0': '月'
, 'Unnamed: 1': '日'
, 'Unnamed: 2': '业务公司'
, 'Unnamed: 3': '业务日期'
, 'Unnamed: 4': '凭证号'
, 'Unnamed: 5': '分录号'
, 'Unnamed: 6': '摘要'
, 'Unnamed: 7': '科目编码'
, 'Unnamed: 8': '科目名称'
, 'Unnamed: 9': '辅助项'
, 'Unnamed: 10': '币种'
, 'Unnamed: 11': '借方原币'
, 'Unnamed: 12': '借方本币'
, 'Unnamed: 13': '贷方原币'
, 'Unnamed: 14': '贷方本币'
, 'Unnamed: 15': '核销信息'
, 'Unnamed: 16': '结算信息'})
dcfs = cdf[cdf["币种"].isin(['人民币', '港币', '美元', '欧元'])].copy()
dcfs.loc[:, '业务主体'] = str.split(filename, '\\')[3]
return dcfs[["业务日期", "凭证号", "科目编码", "科目名称","币种", "借方原币", "借方本币", "贷方原币", "贷方本币", "业务主体"]]
返回的Dataframe的格式是统一的,方便写入数据库。
3 写入数据库
采用dataframe.tosql写入数据库,模式为追加
# 创建的数据库引擎
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test?charset=utf8')
# 创建session类型
DBSession = sessionmaker(bind=engine)
# 实例化官宣模型 - Base 就是 ORM 模型
Base = declarative_base()
# 创建服务单表
class fileinfo(Base):
__tablename__ = 'fileinfo'
id = Column(Integer, primary_key=True, autoincrement=True)
filename = Column(String(268), comment='文件名')
lines = Column(Integer, comment='数量')
# 创建数据库 如果数据库已存在 则不会创建 会根据库名直接连接已有的库
def init_db():
Base.metadata.create_all(engine)
for excel_file in dir_list:
if os.path.getsize(excel_file) > 0:
susscces_file.append(excel_file)
df = getDateFrame(excel_file)
filename = str.split(excel_file, '\\')[3]
df.to_sql(filename, engine, if_exists='append', index=False)
4 数据核验
每完成一个文件是把文件信息收集起来
session = DBSession()
for excel_file in dir_list:
if os.path.getsize(excel_file) > 0:
df = getDateFrame(excel_file)
filename = str.split(excel_file, '\\')[3]
df.to_sql(filename, engine, if_exists='append', index=False)
session.add(fileinfo(os.path.basename(excel_file),df.size))
session.commit()
session.close()
抽取数据要保证数据的完整性,这里可以抽取部分文件数据进行比对
5 数据合并
这个可以在数据库中直接操作,;利用union all 的方式把数据合并起来