摘要
新5G标准和边缘计算对低延迟的要求,给那些试图将一堆不同组件组装成一个不会出现故障且仍具有低延迟的高成本效益应用程序公司带来了严峻的挑战。事实上,这个问题非常严重,以至于需要重新考虑架构。
想要真正从5G和高速数据带来的发展中获利,需要将多个数据层整合到一个集成堆栈中。
介绍
5G和边缘计算都有改变世界的潜力。事实上,很多人会争辩说,边缘计算已经改变了世界。STL Partners发布的一份令人震惊的报告深入分析了IBM和亚马逊等主要企业目前向边缘计算领域投入了多少资金,而5G也在其中。
钱是一回事,而投资所带来的实际变化是另一回事。
显然,一般的现代企业技术栈还没有为5G和边缘计算做好准备,或是为公司已经对5G和边缘计算进行的投资做好准备。 然而今天的技术栈不是为这两种技术构建的。随着更大、更快、更多样化的数据涌入我们的系统,预算限制使它们成为一个非常沉重的负担。
你无法将低延迟改造到传统系统中,至少在不花钱的情况下是这样。 但残酷的现实是,对高可用性和异地复制的新需求需要不断增加开源或传统技术,最终会导致成本过高。
这给现代企业留下了一个非常明确但也令人担忧的困境:寻找一种高效且价格合理的方式。
本文将解释为什么5G标准需要更好的延迟,为什么技术栈变得如此复杂,以及合适的数据平台如何能简化技术栈并通过这种简化自然降低TCO。
为什么5G和边缘计算会遇到物理定律
光和所有其他形式的电磁辐射在真空中以每秒约180英里的速度传播,在光缆中以每秒约120,000 英里的速度传播。5G和边缘计算都围绕极低的延迟建立其的价值主张,1-2 毫秒(ms)很快成为标准。
让我们幻想一款非常简单,能够快速响应的应用程序,其唯一目的是向用户提供其所在城市的名称。如果应用程序托管在爱尔兰都柏林且用户也是,那么用户可以预期1-2毫秒的响应时间。但如果该应用程序托管在288英里外的伦敦会怎么样?这意味着往返(从都柏林到伦敦再返回都柏林)的最短时间是(288/120)×2即4.8毫秒。这还是在理想状态下,即在真空中。
如果应用程序稍微复杂一点怎么办?不是一次性给你城市名称,而是一次给你一个字母(即L-O-N-D-O-N)?这将需要4.8×5即24毫秒。按照5G和边缘计算的标准来看,这速度慢得可笑。
这告诉我们什么?为了可靠地运行边缘和5G应用程序,您需要:
- 地理位置靠近您的客户
- 能够在尽可能少的网络传输中解决其业务问
虽然企业正在通过将计算尽可能靠近其边缘来解决第一个问题,但这一边缘需要被定义。第二个限制传输的问题,需要企业重新考虑如何处理数据以及当前的技术栈可以实现什么与新的数据平台可以为他们做什么。
日益增加的复杂性(和TCO)问题
开源和XaaS正在增加企业系统组件的数量。
在过去二十年中,大量开源、云原生计算基金会(CNCF)和超大规模项目的面世使你可以用最少的代码将相当复杂的解决方案粘合在一起。但这也意味着用不同的组件组装系统更容易,所以系统往往会比所需要的更复杂。
比如说,从开发的角度来看,添加Kafka可能会节省一周的时间。但在操作上,往往会引入多个新组件来支持可能20年前用单个文件就能完成的操作。抽象导致效率低下的想法并不新鲜,这也是为什么有些事情仍然用汇编语言完成。但请记住:面对物理定律,任何额外的复杂性都会消耗我们的延迟预算。
实际上,使用开源技术的TCO比人们想象到的要高得多。你开始使用开源代码,找出差距,然后需要雇佣人员来填补差距,然后根据用例进行定制并构建产品。你还需要遵循积极的升级过程,以免产生巨额技术债务。
微服务也在增加解决方案中的组件数量
微服务也会使延迟问题变得更严重。每个边界(堆栈层之间或微服务之间的水平边界)都会带来延迟和复杂性。即使所有组件可能都位于同一个数据中心,但仍存在消耗预算的延迟。
微服务都会导致为解决业务问题而运行的次数增加。当在同一建筑物里时这没事,但在高延迟网络中会产生问题。在某种程度上你可以异步处理以缓解这种情况,但这又会增加了应用程序的复杂性,并可能导致系统本质上不稳定。假设你需要调用五个微服务来实现业务目标。为了加快速度,你一次运行了其中四个,等待响应,然后再运行第五个,但这可能会出现很多错误。
单独表现良好的组件在堆叠它们时开始表现不好,原因很简单,因为它们试图做不同的事情,并且是由不同的人以不同的视角和期望构建的。此外,每次将组件一分为二时,都会创建新的边界、新的延迟问题和新的API。
结果是:“阻力”让一切都变慢了
德国军事理论家冯·克劳塞维茨(Von Clauswitz)写到了“阻力”的概念,他将其定义为:“单位、组织或系统的理想性目标与其在现实场景中的实际性能之间的差异”。
“阻力”存在于大型复杂应用,就像它存在于军队一样。当你上线运行时,你永远无法获得测试期间的性能,“变量”越多,带来的“阻力”就越多。
因此,开源/XaaS和微服务引入了一个真正的“阻力”问题。当你期望这样一个系统以最慢组件的速度运行,但实际经验表明,这种影响实际上会让事情至少慢 10 倍。
为什么NoSQL数据平台无法解决延迟(或 TCO)问题
基于NoSQL的数据平台于2009/2010年开始出现,并迅速成为任何需要快速扩展处理大量非结构化数据的应用程序(即现代应用程序)公司的“热门”数据库技术。然而,当5G和边缘计算出现时,NoSQL的局限性就暴露出来了。
在NoSQL中,所有处理都由客户端应用程序完成。客户端应用程序的工作是发出多个请求以检索所涉及的不同键值,根据需要对其进行更改,然后将其发回。
这有多重含义:
- 随着业务结构变得更加复杂,到服务器的网络访问次数也在增加。
- 在复杂的事务中,关键数据经常以“读取、重新读取然后再次读取以确保”的模式发生变化。这会导致重大问题,因为每次传输都会增加更多延迟并产生另一个潜在的故障场景。
- 完成事务也会遇到问题。如果你已经更改了三分之二的数据项,现在需要执行第三个。但发现由于数据库中缺乏ACID遵从性,有问题的两个数据项之一已被其他人更改,现在你需要撤销事务并重试。这将显示为“长尾”(即比正常情况更长)延迟,并导致在5G/边缘环境中出现问题。
你还必须考虑客户端应用程序的位置以及客户端代码的复杂程度。它不能在边缘设备上生存,因为光是网络传输的次数就注定了它的失败。但这意味着你的应用程序服务器需要位于边缘位置,以便接收来自边缘设备请求并将其发送到位于同一位置的NoSQL数据库。但是由于上述处理过程非常复杂,应用服务器本身可能会出现故障,使系统处于混乱和不一致的状态,而更改只完成了一半。
最后,如果相关产品使用Java来管理数据,Java垃圾收集也是一个问题。众所周知,垃圾收集很难调整,尤其是产品中的垃圾收集(相较于一次性部署),垃圾收集引起的暂停很容易破坏5G/边缘SLA。
简化堆栈的力量
例证:你不能通过增加复杂性来解决问题。
当你将组件的激增与使用需要多次调用的数据库技术(即NoSQL)相结合时,你将创建网络传输的几何爆炸式增长。系统的复杂性使得单个业务事件可能涉及系统内的20-30个调用。“阻力”出现,SLA消失。
面对5G和边缘计算,传统的性能问题解决方案都无法奏效。因此你无法雇佣更聪明的开发人员、使用更快的硬件或使用更多的硬件。而面对光速,你需要从头开始彻底重新思考你的架构。
企业可能需要些时间才能弄清楚这个问题的全貌。沉没成本谬论应运而生。人们将非常不愿意承认一个系统已从根本上被打破,从而引起越来越多英勇和绝望的调整尝试。企业往往在完成解决方案的实施后,才得出一个尴尬且昂贵的结论,即解决方案行不通。
从堆栈中删除层意味着重新考虑所使用的工具。
现在来质疑微服务的价值可能为时已晚。木已成舟。但迫使开发人员在每次将函数一分为二时考虑摩擦增加的后果并不是一件坏事。
为了更进一步,让我们提出一个可能令人不安的问题:你的应用程序代码中有多少用于解决上述问题,而不是为最终用户提供价值?要有多糟糕你才会开始质疑在5G/边缘体系结构中,是否存在需要为每个逻辑事务执行多个物理事务并重试争用数据的持久层?
当你将业务逻辑限制在客户端应用程序中,检查和/或更改数据所需的传输次数会明显增加。如果可以将业务逻辑代码和数据放在同一个物理服务器上以访问RAM而不是网络,那会怎么样?
Volt Active Data平台如何在未来验证您的技术栈并降低TCO
Volt开发初衷是让OLTP的运行速度比传统数据库快10倍,同时保持ACID遵从性并避免争用问题。随着时间的推移,Volt添加了额外的功能,直到Volt Active Data平台可以替换堆栈中的多个组件,并对其进行高度简化,以便您的应用程序可以轻松满足5G和边缘计算的延迟要求。
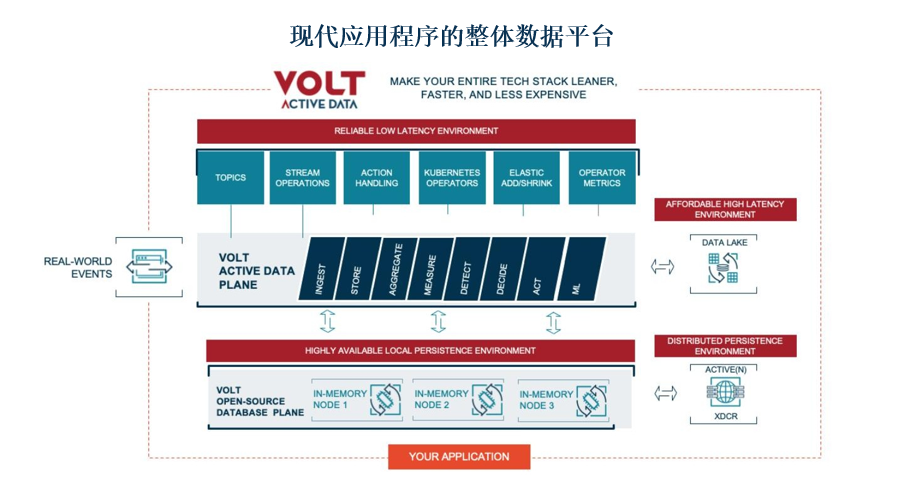
Volt Active Data平台采用了传统数据库“持续存储,间断处理”的方式,并转换成了“持续处理,间断存储”。存储是传统数据库的主要功能,而对Volt Active Data平台来说是在发现事件时可选择的处理方式。Volt的最终目标是尽可能精确地处理尽可能多的事件,同时保持超低的延迟。
在10毫秒内, Volt Active Data平台可以对您的数据执行以下所有操作:
- 消化—即,意识到一个事件。
- 存储—即,如需,存储事件或事件的各个方面以供未来决策时参考。
- 汇总—即,将其汇总以用于统计分析和机器学习(ML)算法。
- 测量—即使数据以闪电般的速度再系统中传输,Volt也可以精准测量。
- 用来做决策—Volt非常擅长做出精准和可扩展的决策。
- 用来进行操作—即,生成真实世界的事件响应(如,接受信用卡交易),而无需客户应用程序知道或参与。
- 用于机器学习—Volt可与任何基于Java的决定性ML引擎配合使用。
Volt是唯一能够在10毫秒内完成上述所有操作的数据平台。
结论
直到最近,企业构建自己的系统才成为常态。他们可能会将这些系统与功能齐全、特定领域的第三方应用程序集成在一起,但大部分代码都是企业的,因此他们“拥有”其性能,无论好坏。
然而,在过去十年中,我们已经看到了在线云服务的兴起,例如提供排队和等候功能。这便于你以更快的完成代码编写,但代价是运行时的复杂性和延迟。
微服务的广泛使用让这成为一个更大的挑战。问题是,当你从超大规模提供商处“购买”在线服务时,你可以更快地完成代码,但你可能根本无法以低延迟运行。鉴于我们现在看到的对5G、边缘计算和个位数毫秒响应的重视,这是一个非常昂贵的错误。
所以,不要犯这样的错误。
并不是说你需要拆除并替换整个堆栈,只因我们知道拆除和替换是一件多么(可能非常昂贵)让人头疼的事。你可以慢慢开始,并逐步集成Volt,这样你就知道自己做了正确的选择。我们强烈建议你从延迟预算开始,然后再进行广泛的原型设计并确定架构。
如果您希望集成 VOLT 到您的技术栈中,请与我们联系!
Volt Active Data 中国网站 | sgao@voltactivedata.com









