
POSTGRESQL 作为开源中高级的数据库,对于OLAP的操作是支持的,和SQL SERVER ,ORACLE 属于同一种类型。所以对于一些轻型的OLAP如何进行优化也是一种的需求。
那么OLAP的优化雷同于,添加一个索引,或者对语句的改写吗,当然不是,如同OOP 面向对象思维的方式,OLAP的操作也可以进行拆分,一个好的OLAP 的操作并不是将一个SQL 写成几十行,然后通过纷繁的索引来解决问题。
那么OLAP到底怎么优化,我们将通过以下的几种方式来尝试将OLAP的操作进行分解目的有以下几个
1 便于阅读,一个很长的SQL不便于理解和执行,可能过一段时间就忘记为什么这样写了,并且这样也不容易发现这样写有什么问题,所以一定不要写一个超级冗长的SQL ,这一定不是一个有经验的SQL 人该做的。
2 便于数据库改写和理解 , 想想你将一堆的SQL 堆在一起,数据库本身要对SQL 进行改写,而越复杂的SQL 改写越困难,出现问题的可能性越大,所以还是不要写成一堆的SQL 将他们改写成一个个的功能。
3 数据重新转移和计算,一个OLAP的SQL 大部分是多个表进行合并计算后的结果,这些表可能有大表,小表,一个个的结果被一次次的计算,如何在计算中,将多个结果先合并成小的结果,在进行拼装,让计算更小,更快。
基于上面的思想,我们会用到以下几种技术来对OLAP 的SQL 进行改写
1 Temporary table
2 CTE
3 视图
4 物化视图
1 临时表
我们创建一个临时表,将中间的结果进行存储,并且在后面对这个临时表的结果进行使用
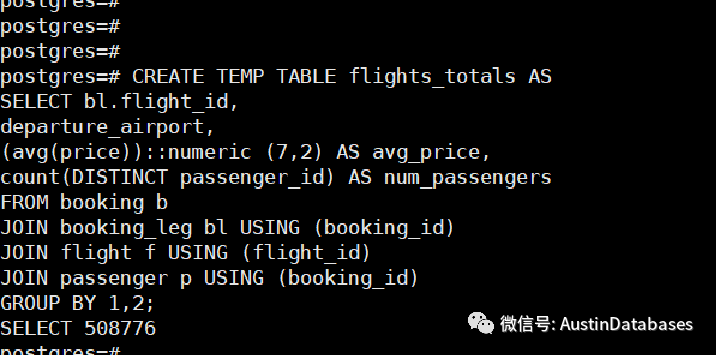
CREATE TEMP TABLE flights_totals AS
SELECT bl.flight_id,
departure_airport,
(avg(price))::numeric (7,2) AS avg_price,
count(DISTINCT passenger_id) AS num_passengers
FROM booking b
JOIN booking_leg bl USING (booking_id)
JOIN flight f USING (flight_id)
JOIN passenger p USING (booking_id)
GROUP BY 1,2;
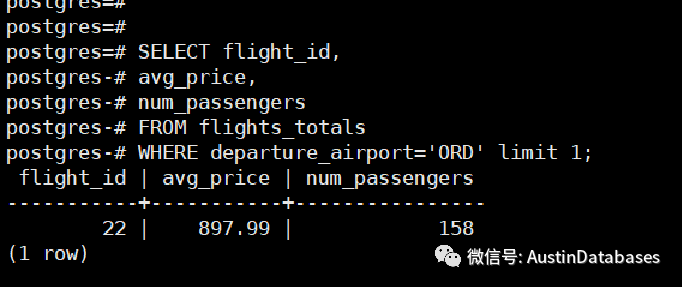
SELECT flight_id,
avg_price,
num_passengers
FROM flights_totals
WHERE departure_airport='ORD' limit 1;
那么问题是临时表的好处是什么,为什么我们要抛弃原表,将结果进行临时的计算并且将结果存储到临时表中。
1 临时表只是在这个会话中存在,不必为了他的存储空间而担心,可以在多个并发中使用同样的临时表,每个临时表只对当时的SESSION负责,这适合变动的数据。
2 临时表将主表与计算分离,通过空间换时间的方式,避免的主表在OLTP 和OLAP 之间分身乏术,避免了长时间占用主表,导致OLTP 工作的失败。
3 如果主表过大,临时添加索引不是一件好事情,可以在产生临时表后,对表进行索引的建立,提高执行的效率,并且灵活应对各种对后期的数据查询和数据提取。
所以临时表是你优化一个复杂查询的第一个方法。
2 CTE
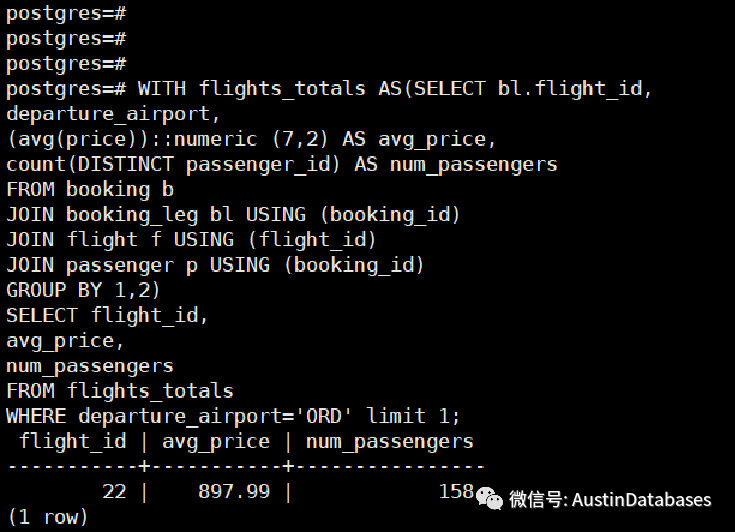
在PG 12之前的版本,CTE 的工作方式与我们建立临时表的方式是一样的,CTE 在执行前需要将数据存储在磁盘上
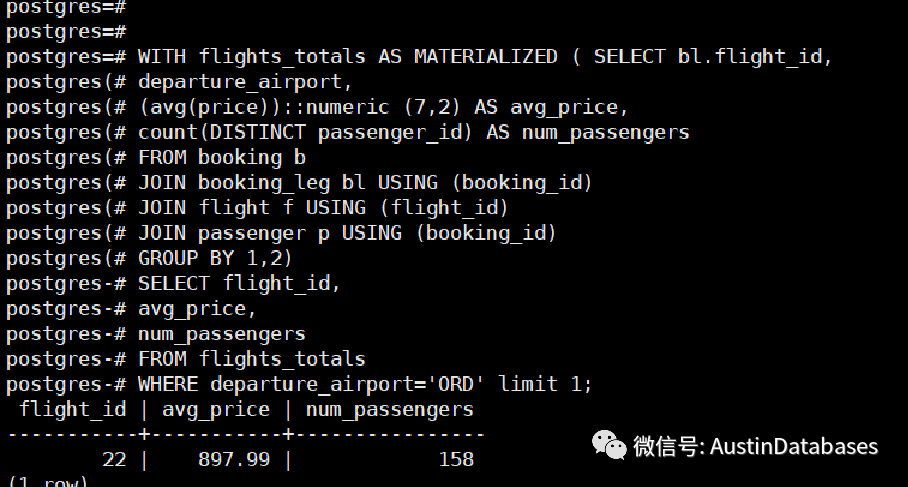
在PG12 和后面得版本,会有两种方式针对CTE ,物化 或者 非物化
explain WITH flights_totals AS MATERIALIZED ( SELECT bl.flight_id,
departure_airport,
(avg(price))::numeric (7,2) AS avg_price,
count(DISTINCT passenger_id) AS num_passengers
FROM booking b
JOIN booking_leg bl USING (booking_id)
JOIN flight f USING (flight_id)
JOIN passenger p USING (booking_id)
GROUP BY 1,2)
SELECT flight_id,
avg_price,
num_passengers
FROM flights_totals
WHERE departure_airport='ORD' limit 1;
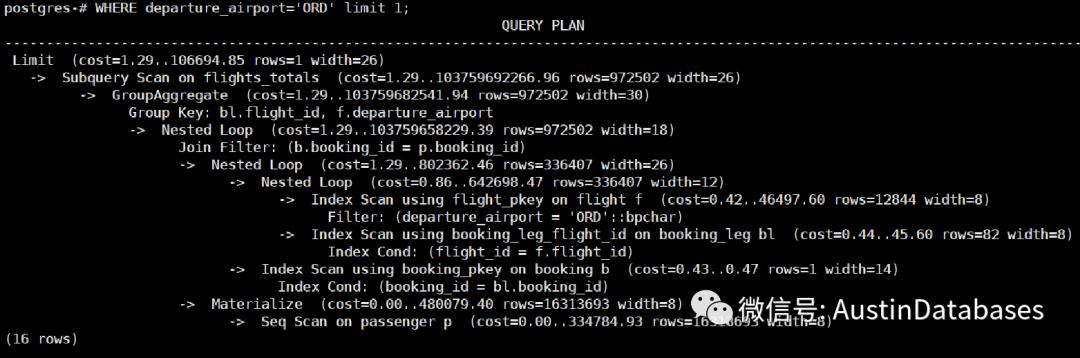
explain WITH flights_totals AS NOT MATERIALIZED ( SELECT bl.flight_id,
departure_airport,
(avg(price))::numeric (7,2) AS avg_price,
count(DISTINCT passenger_id) AS num_passengers
FROM booking b
JOIN booking_leg bl USING (booking_id)
JOIN flight f USING (flight_id)
JOIN passenger p USING (booking_id)
GROUP BY 1,2)
SELECT flight_id,
avg_price,
num_passengers
FROM flights_totals
WHERE departure_airport='ORD' limit 1;
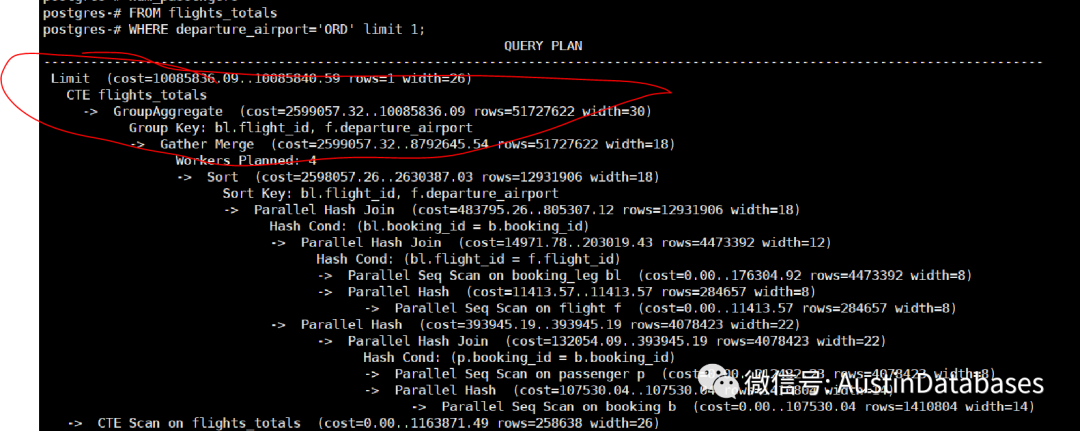
在第二种方式中,强制使用PG12后的提供的内联的方式,查询的优化效果相对之前的方式事有进步的。
所以在复杂查询中可以使用PG12后的CTE方式来对数据进行查询。
说完这个问题就是另一个问题了,对于VIEW 到底要不要使用,其实这个观点和性能无关,和管理有关
1 如果我不用VIEW 直接写SQL 或使用VIEW
1.1 如果条件进行变化,则我直接要在整体的SQL中进行修改
1.2 对于复杂查询,查询是一个整体,而不是用开发的思维的方式来进行管理,VIEW 可以理解就是一个复杂SQL 的模块,通过不同的模块组成一个整体的复杂的SQL,便于维护和管理。
1.3 对于更多的OLAP得操作,这个VIEW 是可以被复用的,而不是我又要在写一遍,这样对于提高工作效率是好的
1.4 VIEW 是一个被编译好的语句,而不是每次都需要被编译的SQL
当然这也不是说,就可以滥用VIEW,那些不经过拆分的VIEW,将一个大SQL 直接塞入VIEW的方式,是应该被谴责的,我认为他就是 数据库中的“工业垃圾”。
最后就是物化视图,PG的物化视图是需要手动进行更新的,实际上物化视图针对部分场景是十分友好的,例如数据计算是前一天的数据,那么我凌晨计算好这些昨天的数据,并将其存储到物化视图中,转天可以避开实体表,让计算OLTP 和 OLAP 进行分离,这当然是一个好的想法,所以物化视图是一个帮助实现这个功能的方式,尤其可以用一条命令就刷新数据。











