alloc_skb:分配一个数据长度为size的network buffer {skb+data_buffer}1 /**
2 * __alloc_skb - allocate a network buffer
3 * @size: size to allocate
4 * @gfp_mask: allocation mask
5 * @flags: If SKB_ALLOC_FCLONE is set, allocate from fclone cache
6 * instead of head cache and allocate a cloned (child) skb.
7 * If SKB_ALLOC_RX is set, __GFP_MEMALLOC will be used for
8 * allocations in case the data is required for writeback
9 * @node: numa node to allocate memory on
10 *
11 * Allocate a new &sk_buff. The returned buffer has no headroom and a
12 * tail room of at least size bytes. The object has a reference count
13 * of one. The return is the buffer. On a failure the return is %NULL.
14 *
15 * Buffers may only be allocated from interrupts using a @gfp_mask of
16 * %GFP_ATOMIC.
17 */
18 /*1.SKB 的分配时机主要有两种,最常见的一种是在网卡的中断中,有数据包到达的时,系统分配 SKB 包进行包处理;
19 第二种情况是主动分配 SKB 包用于各种调试或者其他处理环境.
20
21 2.SKB 的 reserve 操作:SKB 在分配的过程中使用了一个小技巧 :
22 即在数据区中预留了 128 个字节大小的空间作为协议头使用,
23 通过移动 SKB 的 data 与 tail 指针的位置来实现这个功能.
24 3.当数据到达网卡后,会触发网卡的中断,从而进入 ISR 中,系统会在 ISR 中计算出此次接收到的数据的字节数 : pkt_len,
25 然后调用 SKB 分配函数来分配 SKB :
26 skb = dev_alloc_skb(pkt_len+);
27 实际上传入的数据区的长度还要比实际接收到的字节数多,这实际上是一种保护机制.
28 实际上,在 dev_alloc_skb 函数调用 __dev_alloc_skb 函数,而 __dev_alloc_skb 函数又调用 alloc_skb 函数 时,
29 其数据区的大小又增加了 128 字节, 这 128 字节就事前面我们所说的 reserve 机制预留的 header 空间
30 */
31 struct sk_buff *__alloc_skb(unsigned int size, gfp_t gfp_mask,
32 int flags, int node)
33 {
34 struct kmem_cache *cache;
35 struct skb_shared_info *shinfo;
36 struct sk_buff *skb;
37 u8 *data;
38 bool pfmemalloc;
39 //获取指定的高速缓存 fclone_skb or skb
40 cache = (flags & SKB_ALLOC_FCLONE)
41 ? skbuff_fclone_cache : skbuff_head_cache;
42
43 if (sk_memalloc_socks() && (flags & SKB_ALLOC_RX))
44 gfp_mask |= __GFP_MEMALLOC;
45
46 /* Get the HEAD 从cache上分配, 如果cache上无法分配,则从内存中申请 */
47 skb = kmem_cache_alloc_node(cache, gfp_mask & ~__GFP_DMA, node);
48 if (!skb)
49 goto out;
50 prefetchw(skb); //用于写预取 手工执行预抓取 ----提升性能
51
52 /* We do our best to align skb_shared_info on a separate cache
53 * line. It usually works because kmalloc(X > SMP_CACHE_BYTES) gives
54 * aligned memory blocks, unless SLUB/SLAB debug is enabled.
55 * Both skb->head and skb_shared_info are cache line aligned.
56 */
57 size = SKB_DATA_ALIGN(size);/* 数据对齐 */
58 /* 对齐后的数据加上skb_shared_info对齐后的大小 */
59 size += SKB_DATA_ALIGN(sizeof(struct skb_shared_info));
60 //分配数据区 使用kmalloc ??????
61 data = kmalloc_reserve(size, gfp_mask, node, &pfmemalloc);---
62 if (!data)
63 goto nodata;
64 /* kmalloc(size) might give us more room than requested.
65 * Put skb_shared_info exactly at the end of allocated zone,
66 * to allow max possible filling before reallocation.
67 */
68 /* 除了skb_shared_info以外的数据大小 */
69 size = SKB_WITH_OVERHEAD(ksize(data));
70 prefetchw(data + size);// 手工执行预抓取
71
72 /*
73 * Only clear those fields we need to clear, not those that we will
74 * actually initialise below. Hence, don't put any more fields after
75 * the tail pointer in struct sk_buff!
76 */
77 memset(skb, 0, offsetof(struct sk_buff, tail));
78 /* Account for allocated memory : skb + skb->head */
79 /* 总长度= skb大小+ 数据大小+ skb_shared_info大小 */
80 skb->truesize = SKB_TRUESIZE(size);
81 skb->pfmemalloc = pfmemalloc;
82 atomic_set(&skb->users, 1);/* 设置引用计数为1 */
83 skb->head = data;/*head data tail均指向数据区头部*/
84 skb->data = data;
85 skb_reset_tail_pointer(skb);
86 //end tail+size 指向尾部
87 skb->end = skb->tail + size;
88 // l2 l3 l4 head 初始化 为啥不是0
89 skb->mac_header = (typeof(skb->mac_header))~0U;
90 skb->transport_header = (typeof(skb->transport_header))~0U;
91
92 /* make sure we initialize shinfo sequentially */
93 //之前 手工执行预抓取 现在使用 -------从end开始的区域为skb_shared_info
94 shinfo = skb_shinfo(skb);// skb->end 也就是 linear data的end ----> 数据的开始
95 memset(shinfo, 0, offsetof(struct skb_shared_info, dataref));
96 atomic_set(&shinfo->dataref, 1);
97 kmemcheck_annotate_variable(shinfo->destructor_arg);
98
99 /*skbuff_fclone_cache和skbuff_head_cache。它们两个的区别是前者是每两个skb为一组。
100 当从skbuff_fclone_cache分配skb时,会两个连续的skb一起分配,但是释放的时候可以分别释放。
101 也就是说当调用者知道需要两个skb时,如后面的操作很可能使用skb_clone时,
102 那么从skbuff_fclone_cache上分配skb会更高效一些。*/
103
104 if (flags & SKB_ALLOC_FCLONE) {//如果有克隆标记
105 struct sk_buff_fclones *fclones;/* 如果是fclone cache的话,那么skb的下一个buf,也被分配le
106 之前使用的是flcone_cache 分配*/
107
108 fclones = container_of(skb, struct sk_buff_fclones, skb1);
109
110 kmemcheck_annotate_bitfield(&fclones->skb2, flags1);
111 skb->fclone = SKB_FCLONE_ORIG; //orig
112 atomic_set(&fclones->fclone_ref, 1);//
113
114 fclones->skb2.fclone = SKB_FCLONE_CLONE;
115 fclones->skb2.pfmemalloc = pfmemalloc;
116 }
117 out:
118 return skb;
119 nodata:
120 kmem_cache_free(cache, skb);
121 skb = NULL;
122 goto out;
123 }
dev_alloc_skb:分配skb,通常被设备驱动用在中断上下文中,它是alloc_skb的封装函数,因为在中断处理函数中被调用,因此要求原子操作(GFP_ATOMIC)----不允许休眠;
GFP_ATOMIC:防止alloc memory 时 出现休眠导致 在中断里面出现 调度
static inline struct sk_buff *dev_alloc_skb(unsigned int length)
{
return netdev_alloc_skb(NULL, length);
}


1 /**
2 * __netdev_alloc_skb - allocate an skbuff for rx on a specific device
3 * @dev: network device to receive on
4 * @len: length to allocate
5 * @gfp_mask: get_free_pages mask, passed to alloc_skb
6 *
7 * Allocate a new &sk_buff and assign it a usage count of one. The
8 * buffer has NET_SKB_PAD headroom built in. Users should allocate
9 * the headroom they think they need without accounting for the
10 * built in space. The built in space is used for optimisations.
11 *
12 * %NULL is returned if there is no free memory.
13 */
14 struct sk_buff *__netdev_alloc_skb(struct net_device *dev, unsigned int len,
15 gfp_t gfp_mask)
16 {
17 struct page_frag_cache *nc;
18 unsigned long flags;
19 struct sk_buff *skb;
20 bool pfmemalloc;
21 void *data;
22
23 /* 分配长度+ skb_shared_info长度 然后对整个长度进行对齐*/
24 len += NET_SKB_PAD;
25 len += SKB_DATA_ALIGN(sizeof(struct skb_shared_info));
26 len = SKB_DATA_ALIGN(len);
27
28 if (sk_memalloc_socks())
29 gfp_mask |= __GFP_MEMALLOC;
30
31 local_irq_save(flags);//为啥要 关闭中断??
32
33 nc = this_cpu_ptr(&netdev_alloc_cache);
34 data = __alloc_page_frag(nc, len, gfp_mask); /* 分配空间 */
35 pfmemalloc = nc->pfmemalloc;
36
37 local_irq_restore(flags);/* 开启中断 并restore flag*/
38
39 if (unlikely(!data))
40 return NULL;
41
42 skb = __build_skb(data, len);/* 构建skb */
43 if (unlikely(!skb)) {
44 skb_free_frag(data);
45 return NULL;
46 }
47
48 /* use OR instead of assignment to avoid clearing of bits in mask */
49 if (pfmemalloc)
50 skb->pfmemalloc = 1;
51 skb->head_frag = 1;
52
53 skb_success:
54 skb_reserve(skb, NET_SKB_PAD); /* 保留空间 */
55 skb->dev = dev;/* 设置输入设备 */
56
57 skb_fail:
58 return skb;
59 }View Code
1 /**
2 * __build_skb - build a network buffer
3 * @data: data buffer provided by caller
4 * @frag_size: size of data, or 0 if head was kmalloced
5 *
6 * Allocate a new &sk_buff. Caller provides space holding head and
7 * skb_shared_info. @data must have been allocated by kmalloc() only if
8 * @frag_size is 0, otherwise data should come from the page allocator
9 * or vmalloc()
10 * The return is the new skb buffer.
11 * On a failure the return is %NULL, and @data is not freed.
12 * Notes :
13 * Before IO, driver allocates only data buffer where NIC put incoming frame
14 * Driver should add room at head (NET_SKB_PAD) and
15 * MUST add room at tail (SKB_DATA_ALIGN(skb_shared_info))
16 * After IO, driver calls build_skb(), to allocate sk_buff and populate it
17 * before giving packet to stack.
18 * RX rings only contains data buffers, not full skbs.
19 */
20 struct sk_buff *__build_skb(void *data, unsigned int frag_size)
21 {
22 struct skb_shared_info *shinfo;
23 struct sk_buff *skb;
24 unsigned int size = frag_size ? : ksize(data);
25
26 skb = kmem_cache_alloc(skbuff_head_cache, GFP_ATOMIC);
27 if (!skb)
28 return NULL;
29
30 size -= SKB_DATA_ALIGN(sizeof(struct skb_shared_info));
31
32 memset(skb, 0, offsetof(struct sk_buff, tail));
33 skb->truesize = SKB_TRUESIZE(size);
34 atomic_set(&skb->users, 1);
35 skb->head = data;
36 skb->data = data;
37 skb_reset_tail_pointer(skb);skb->tail = skb->data;
38 skb->end = skb->tail + size;
39 skb->mac_header = (typeof(skb->mac_header))~0U;
40 skb->transport_header = (typeof(skb->transport_header))~0U;
41
42 /* make sure we initialize shinfo sequentially */
43 shinfo = skb_shinfo(skb);
44 memset(shinfo, 0, offsetof(struct skb_shared_info, dataref));
45 atomic_set(&shinfo->dataref, 1);
46 kmemcheck_annotate_variable(shinfo->destructor_arg);
47
48 return skb;
49 }View Code
napi_alloc_skb:分配skb,和dev_allock_skb 差不多:
- __napi_alloc_skb - allocate skbuff for rx in a specific NAPI instance
- __netdev_alloc_skb - allocate an skbuff for rx on a specific device
和__netdev_alloc_skb 相比;__napi_alloc_skb 实现差不多 就多了一部分代码:
分配长度+ skb_shared_info长度> 一页 且有__GFP_DIRECT_RECLAIM | GFP_DMA 标记------>则调用 alloc_skb分配
struct sk_buff *__napi_alloc_skb(struct napi_struct *napi, unsigned int len,
gfp_t gfp_mask)
{
struct napi_alloc_cache *nc = this_cpu_ptr(&napi_alloc_cache);
struct sk_buff *skb;
void *data;
len += NET_SKB_PAD + NET_IP_ALIGN;
if ((len > SKB_WITH_OVERHEAD(PAGE_SIZE)) ||
(gfp_mask & (__GFP_DIRECT_RECLAIM | GFP_DMA))) {
skb = __alloc_skb(len, gfp_mask, SKB_ALLOC_RX, NUMA_NO_NODE);
if (!skb)
goto skb_fail;
goto skb_success;
}
-------------------
}
当然 分配内存 最后的底层实现就不看了:有机会再看吧;应该是kmalloc kmem_cache slab get_page order_page啥的吧
kfree_skb:减少skb引用,为0则释放;Drop a reference to the buffer and free it if the usage count has hit zero.
/**
* kfree_skb - free an sk_buff
* @skb: buffer to free
*
* Drop a reference to the buffer and free it if the usage count has
* hit zero.
*/
void kfree_skb(struct sk_buff *skb)
{
if (unlikely(!skb))
return;
/* 引用为1,可直接释放 */
if (likely(atomic_read(&skb->users) == 1))
smp_rmb();
// 对引用减1,并且判断,如果结果不为0 说明还有对象持有 返回
else if (likely(!atomic_dec_and_test(&skb->users)))
return;
trace_kfree_skb(skb, __builtin_return_address(0));
__kfree_skb(skb); //真正的skb释放
}
/**
* __kfree_skb - private function
* @skb: buffer
*
* Free an sk_buff. Release anything attached to the buffer.
* Clean the state. This is an internal helper function. Users should
* always call kfree_skb
*/
void __kfree_skb(struct sk_buff *skb)
{
skb_release_all(skb);/* 释放skb附带的所有数据 */
kfree_skbmem(skb);/* 释放skb */
}
static void skb_free_head(struct sk_buff *skb)
{
unsigned char *head = skb->head;
if (skb->head_frag)// 表示线性区 数据在page 区 len=size&&&date_len=sieze 通过alloc_page_frag拿到skb->head=data=page
skb_free_frag(head);
else
kfree(head);
}
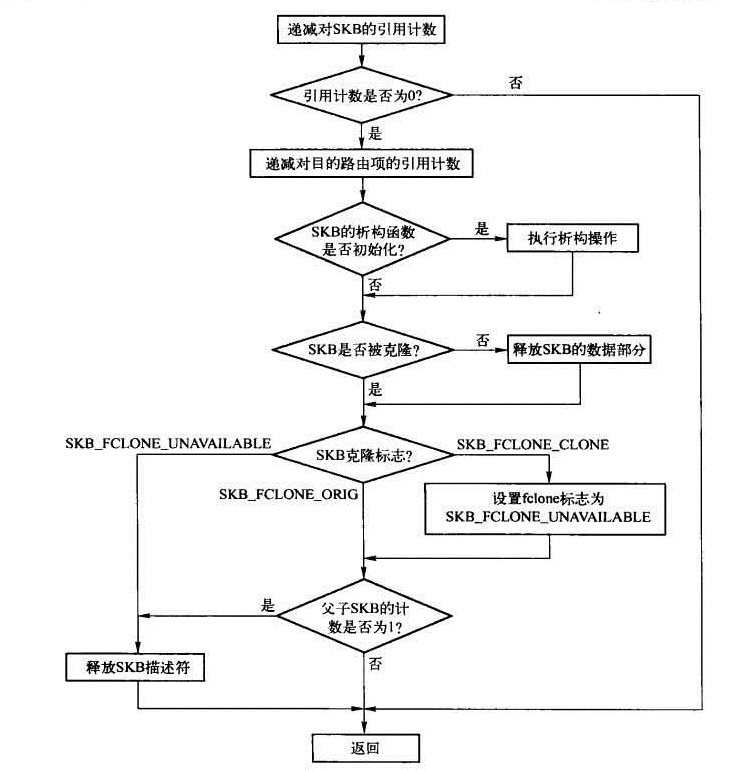

consume_skb:释放skb,与kfree_skb区别是,kfree_skb用于失败时丢包释放;
也就是:consume_skb 表示 skb是正常释放。kfree_skb 表示因为某种错误报文被丢弃
#define dev_kfree_skb(a) consume_skb(a)
1 /**
2 * consume_skb - free an skbuff
3 * @skb: buffer to free
4 *
5 * Drop a ref to the buffer and free it if the usage count has hit zero
6 * Functions identically to kfree_skb, but kfree_skb assumes that the frame
7 * is being dropped after a failure and notes that
8 */
9 void consume_skb(struct sk_buff *skb)
10 {
11 if (unlikely(!skb))
12 return;
13 if (likely(atomic_read(&skb->users) == 1))
14 smp_rmb();
15 else if (likely(!atomic_dec_and_test(&skb->users)))
16 return;
17 trace_consume_skb(skb);
18 __kfree_skb(skb);
19 }View Code
所以 consume_skb 和kfree_skb 基本相同;除了统计分析的函数不一样
对于中断上下文中其不能使用kfree_skb来释放skbbuff;
需要使用dev_kfree_skb_irq 或者dev_kfree_skb_any
/*
* It is not allowed to call kfree_skb() or consume_skb() from hardware
* interrupt context or with hardware interrupts being disabled.
* (in_irq() || irqs_disabled())
*
* We provide four helpers that can be used in following contexts :
*
* dev_kfree_skb_irq(skb) when caller drops a packet from irq context,
* replacing kfree_skb(skb)
*
* dev_consume_skb_irq(skb) when caller consumes a packet from irq context.
* Typically used in place of consume_skb(skb) in TX completion path
*
* dev_kfree_skb_any(skb) when caller doesn't know its current irq context,
* replacing kfree_skb(skb)
*
* dev_consume_skb_any(skb) when caller doesn't know its current irq context,
* and consumed a packet. Used in place of consume_skb(skb)
*/
static inline void dev_kfree_skb_irq(struct sk_buff *skb)
{
__dev_kfree_skb_irq(skb, SKB_REASON_DROPPED);
}
static inline void dev_consume_skb_irq(struct sk_buff *skb)
{
__dev_kfree_skb_irq(skb, SKB_REASON_CONSUMED);
}
static inline void dev_kfree_skb_any(struct sk_buff *skb)
{
__dev_kfree_skb_any(skb, SKB_REASON_DROPPED);
}
static inline void dev_consume_skb_any(struct sk_buff *skb)
{
__dev_kfree_skb_any(skb, SKB_REASON_CONSUMED);
}
http代理服务器(3-4-7层代理)-网络事件库公共组件、内核kernel驱动 摄像头驱动 tcpip网络协议栈、netfilter、bridge 好像看过!!!!
但行好事 莫问前程
--身高体重180的胖子










