ZooKeeper 到底是个什么东西?
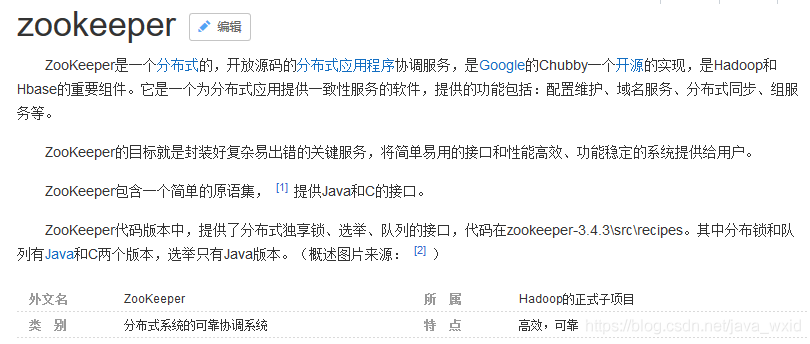
ZooKeeper 作为 Dubbo 的注册中心
Zookeeper 是 Hadoop 生态系统的一员。
zookeeper是一个开源的服务软件,需要安装到linux中。
构建 Zookeeper 集群的时候,使用的服务器最好是奇数台。
ZooKeeper的基本运转流程:
1、选举Leader。
2、同步数据。
3、选举Leader过程中算法有很多,但要达到的选举标准是一致的。
4、Leader要具有最高的执行ID,类似root权限。
5、集群中大多数的机器得到响应并接受选出的Leader。
Zookeeper的作用
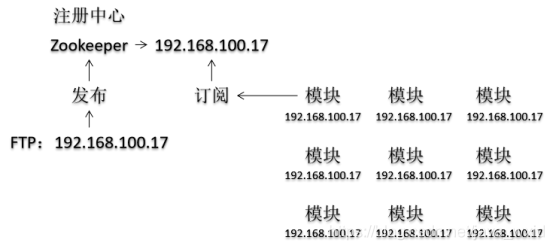
树形目录结构
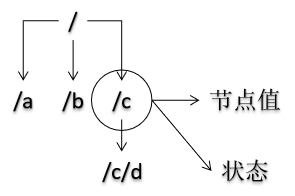
异步通知机制
Zookeeper安装
确认JDK
[root@rich ~]# java -version
java version "1.8.0_121"
Java(TM) SE Runtime Environment (build 1.8.0_121-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.121-b13, mixed mode)Zookeeper解压
第一步:上传zookeeper-3.4.9.tar.gz到/opt目录
第二步:解压
tar -zxvf /opt/zookeeper-3.4.9.tar.gz
第三步:进入解压目录下的conf目录
cd /opt/zookeeper-3.4.9/conf
第四步:复制得到配置文件
cp zoo_sample.cfg zoo.cfg
第五步:创建数据目录
mkdir /opt/zookeeper-3.4.9/data
第六步:修改zoo.cfg配置文件
dataDir=/opt/zookeeper-3.4.9/data
常用四字命令(运维人员常用)
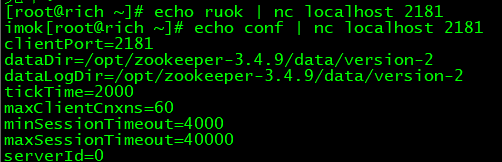
Are your ok? I am ok
ruok:测试服务是否处于正确状态。如果确实如此,那么服务返回“imok ”,否则不做任何响应
stat:输出关于性能和连接的客户端的列表
conf:输出相关服务配置的详细信息
cons:列出所有连接到服务器的客户端的完全的连接 /会话的详细信息。包括“接受 / 发送”的包数量、会话id 、操作延迟、最后的操作执行等等信息
dump:列出未经处理的会话和临时节点
envi:输出关于服务环境的详细信息(区别于conf命令)
reqs:列出未经处理的请求
wchs:列出服务器watch的详细信息
wchc:通过session列出服务器watch的详细信息,它的输出是一个与watch相关的会话的列表
wchp:通过路径列出服务器 watch的详细信息。它输出一个与 session相关的路径
节点状态
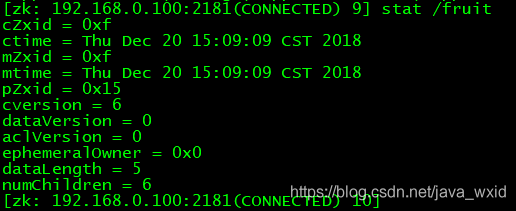
czxid:引起这个znode创建的zxid,创建节点的事务的czxid(create ZooKeeper Transaction Id)
ctime:znode被创建的毫秒数(从1970年开始)
mzxid:znode最后更新的zxid
mtime:znode最后修改的毫秒数(从1970年开始)
pZxid:znode最后更新的子节点zxid
cversion:znode子节点变化号,znode子节点修改次数
dataversion:znode数据变化号,也就是版本号
aclVersion:znode访问控制列表的变化号
ephemeralOwner:如果是临时节点,这个是znode拥有者的session id。如果不是临时节点则是0。
dataLength:znode的数据长度
numChildren:znode子节点数量
版本号的作用
Zookeeper里面的版本号和我们理解的版本号不同,它表示的是对数据节点的内容、子节点列表或者ACL信息的修改次数。节点创建时dataversion、aclversion,cversion都为0,每次修改响应内容其对应的版本号加1。
这个版本号的用途就和分布式场景的一个锁概念有关。比如演出售票中的一个座位,显然每个场次中的每个座位都只有一个,不可能卖出2次。如果A下单的时候显示可售,他想买,那么为了保证他可以下单成功,此时别人就不能买。这时候就需要有一种机制来保证同一时刻只能有一个人去修改该座位的库存。这就用到了锁。锁有悲观锁和乐观锁。
- 悲观锁:它会假定所有不同事务的处理一定会出现干扰,数据库中最严格的并发控制策略,如果一个事务A正在对数据处理,那么在整个事务过程中,其他事务都无法对这个数据进行更新操作,直到A事务释放了这个锁。
- 乐观锁:它假定所有不同事务的处理不一定会出现干扰,所以在大部分操作里不许加锁,但是既然是并发就有出现干扰的可能,如何解决冲突就是一个问题。在乐观锁中当你在提交更新请求之前,你要先去检查你读取这个数据之后该数据是否发生了变化,如果有那么你此次的提交就要放弃,如果没有就可以提交。
Zookeeper中的版本号就是乐观锁,你修改节点数据之前会读取这个数据并记录该数据版本号,当你需要更新时会携带这个版本号去提交,如果你此时携带的版本号(就是你上次读取出来的)和当前节点的版本号相同则说明该数据没有被修改过,那么你的提交就会成功,如果提交失败说明该数据在你读取之后和提交之前这段时间内被修改了。
这里通过set命令并携带版本号提交更新,版本号相同更新就会成功。
Zookeeper服务器客户端操作
启动服务器
/opt/zookeeper-3.4.9/bin/zkServer.sh start
查看服务器状态
[root@rich bin]# /opt/zookeeper-3.4.9/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.4.9/bin/../conf/zoo.cfg
Mode: standalone
日志文件
zookeeper.out
停止服务器
/opt/zookeeper-3.4.9/bin/zkServer.sh stop
使用客户端登录服务器,登录之前要启动服务器
/opt/zookeeper-3.4.9/bin/zkCli.sh -server 192.168.200.100:2181
如果是本机和默认2181端口号-server后面部分可以省略
Zookeeper常用命令
ZooKeeper服务器与客户端
在/opt/zookeeper-3.4.9/bin目录下
启动服务器:./zkServer.sh start
停止服务器:./zkServer.sh stop
制作开机启动的脚本

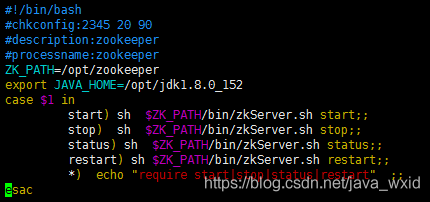
把如下脚本复制进去,注意:先i,然后在复制
#!/bin/bash
#chkconfig:2345 20 90
#description:zookeeper
#processname:zookeeper
ZK_PATH=/opt/zookeeper
export JAVA_HOME=/opt/jdk1.8.0_152
case $1 in
start) sh $ZK_PATH/bin/zkServer.sh start;;
stop) sh $ZK_PATH/bin/zkServer.sh stop;;
status) sh $ZK_PATH/bin/zkServer.sh status;;
restart) sh $ZK_PATH/bin/zkServer.sh restart;;
*) echo "require start|stop|status|restart" ;;
esacZK_PATH=/opt/zookeeper
export JAVA_HOME=/opt/jdk1.8.0_152
注意:这二处地方要改成自己opt目录下对应的zookeeper
然后把脚本注册为Service
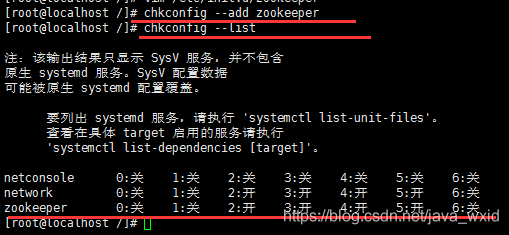
增加权限
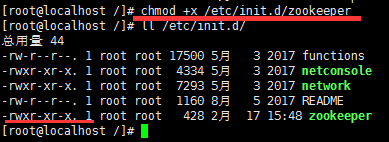
初始化zookeeper配置文件
拷贝/opt/zookeeper/conf/zoo_sample.cfg
到同一个目录下改个名字叫zoo.cfg

然后咱们启动zookeeper
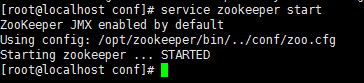
以上状态即为安装成功。
在/opt/zookeeper-3.4.9/bin目录下
启动客户端:./zkCli.sh
退出客户端:[zk: localhost:2181(CONNECTED) 6] quit
查看节点的子节点:ls /zookeeper/quota
获取指定节点的值:get /zookeeper
设置指定节点的值:set /zookeeper hello
创建节点:create /fruit water
删除节点:delete /fruit/apple只能删除空节点
删除节点rmr /fruit空节点和非空节点都可以删除

-s:含有序列
创建有序列的节点:create -s /fruit/apple red
apple后面的0000000000就是序列
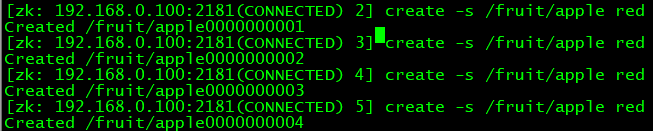

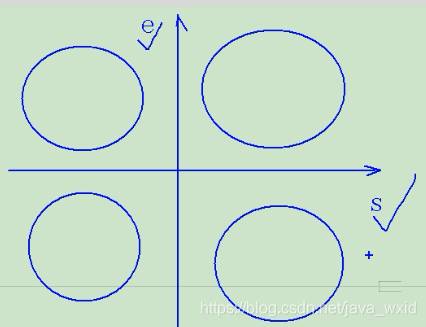
-e:临时(重启或者超时消失)
创建临时节点:create -e /fruit/orange yellow在重启后再查看就没有这个节点了
通过-e和-s可以把节点分为四个象限,四个情况的节点
Zookeeper集群搭建
集群中服务器间通信时用到3种端口号
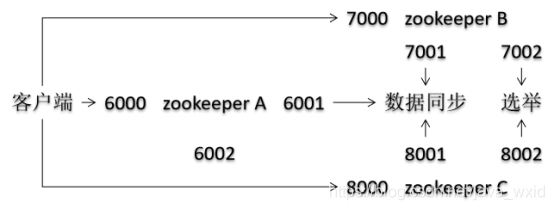
- 客户端访问端口号
- 集群中服务器间数据同步端口号
- 集群中follower服务器选举leader服务器端口号
集群中服务器编号
编号形式:1、2、3、……
指定编号:数据目录/myid文件中写入编号
编号和端口号在配置文件中的配置方式
客户端端口号
clientPort
编号和端口号
在配置文件末尾指定如下格式:
server.编号=IP地址:数据同步端口号:选举端口号
server.1=127.0.0.1:6001:6002
server.2=127.0.0.1:7001:7002
server.3=127.0.0.1:8001:8002
zkone步骤
创建目录
mkdir /opt/cluster_zk
重新解压Zookeeper
tar -zxvf /opt/zookeeper-3.4.9.tar.gz -C /opt/cluster_zk/
进入集群目录
cd /opt/cluster_zk
复制解压目录
cp -r zookeeper-3.4.9/ zkone
在zkone中创建data目录
mkdir /opt/cluster_zk/zkone/data
创建myid文件
vim /opt/cluster_zk/zkone/data/myid
进入zkone的conf目录
cd /opt/cluster_zk/zkone/conf/
复制得到zoo.cfg
cp zoo_sample.cfg zoo.cfg
编辑zoo.cfg
dataDir=/opt/cluster_zk/zkone/data/
clientPort=6000
server.1=127.0.0.1:6001:6002
server.2=127.0.0.1:7001:7002
server.3=127.0.0.1:8001:8002
zktwo步骤
复制zkone
cp -r /opt/cluster_zk/zkone/ /opt/cluster_zk/zktwo
将myid改成2
vim /opt/cluster_zk/zktwo/data/myid
修改配置文件
vim /opt/cluster_zk/zktwo/conf/zoo.cfg
dataDir=/opt/cluster_zk/zktwo/data/
clientPort=7000
三个客户端登录三个服务器
/opt/cluster_zk/zkone/bin/zkCli.sh -server 127.0.0.1:6000
/opt/cluster_zk/zktwo/bin/zkCli.sh -server 127.0.0.1:7000
/opt/cluster_zk/zkthree/bin/zkCli.sh -server 127.0.0.1:8000
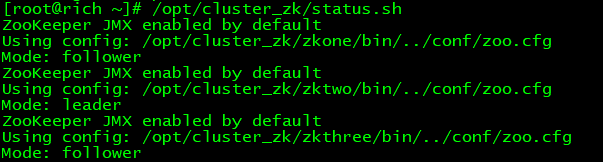
可以看到现在zktwo是leader,zkone和zkthree是follower
如果leader服务器不能工作了,并不影响zkone和zkthree,因为zkone和zkthree二个服务器会选举出一个leader,三个服务器任何一个服务器不能工作,其他服务器都可以正常运行,并且可以保证数据同步。
集群数量为什么是单数?
zookeeper有这样一个特性:集群中只要有过半的机器是正常工作的,那么整个集群对外就是可用的。也就是说如果有2个zookeeper,那么只要有1个死了zookeeper就不能用了,因为1没有过半,所以2个zookeeper的死亡容忍度为0;同理,要是有3个zookeeper,一个死了,还剩下2个正常的,过半了,所以3个zookeeper的容忍度为1;同理你多列举几个:2->0;3->1;4->1;5->2;6->2会发现一个规律,2n和2n-1的容忍度是一样的,都是n-1,所以为了更加高效,何必增加那一个不必要的zookeeper呢。










