文章目录
理论讲述
前言
之前的一篇文章已经简单介绍了回归中的线性回归:click here
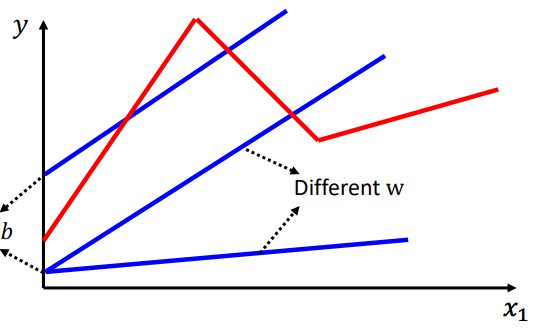
这次依然讲回归,按照线性回归的思路,
y
=
b
+
w
∗
x
1
y=b+w*x_1
y=b+w∗x1,再写出loss,梯度下降再最优化参数,可得到最优解。但是这样的模型还是比较简单,因为影响y的因素可能不止
x
1
x_1
x1,可能还有其他的因素,所以假设模型为
y
=
b
+
∑
i
=
1
7
w
i
x
i
y=b+\sum_{i=1}^7w_ix_i
y=b+i=1∑7wixi计算出此时训练数据集的loss,和测试集的loss。如果觉得loss还是太大还可以继续增加feature,令
y
=
b
+
∑
i
=
1
28
w
i
x
i
y=b+\sum_{i=1}^{28}w_ix_i
y=b+i=1∑28wixi
这样一直下来的结果,会发现loss的确会下降,但是当feature一定多的时候,loss就会下降的非常缓慢或者停止下降了;
这其实就告诉我们,可能真正的模型不是线性回归,毕竟线性回归模型有很多限制,不能够很好的拟合真正的模型,我们需要一个更灵活的模型。
全连接网络
首先假设存在这样一个更复杂的函数,如下图红色曲线所示。
显然红色曲线不再是简单的线性回归,但可以看成是分段的线性函数,并且可以把它分解成下图所示:
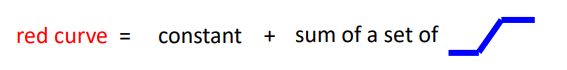
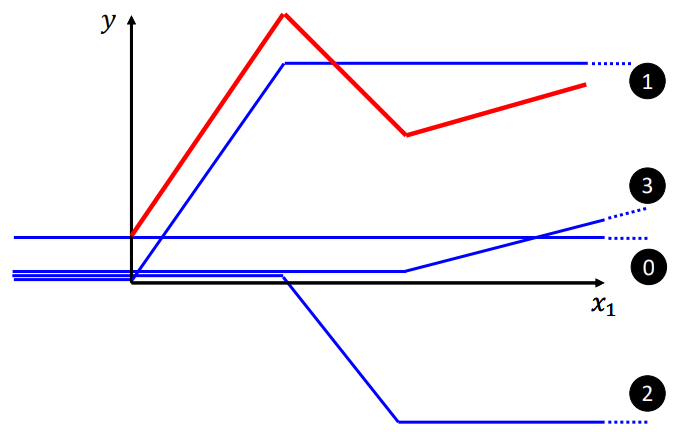
具体地,红色曲线可以由这样几条曲线组成:
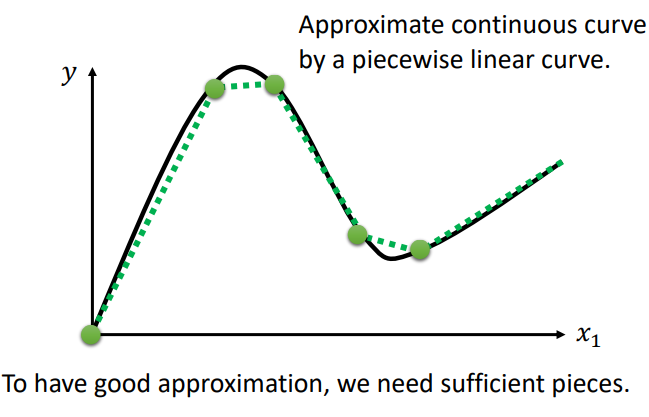
并且,如果实际的模型比红色的曲线更复杂,不用担心,也可以进行分解:

如果不是分段线性,是一个曲线的话,可以用分段线性来拟合:
现在的问题只剩下如何来表示这个函数了:
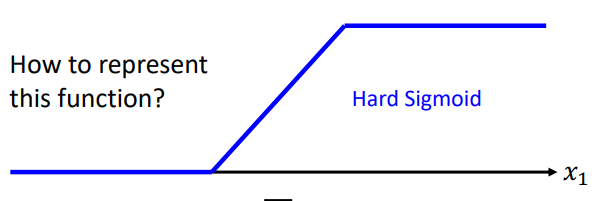
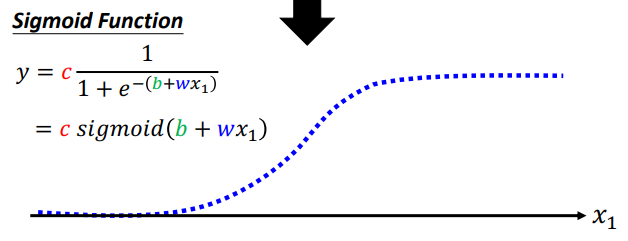
采用拟合逼近的方法,引入sigmoid函数:
f
(
x
)
=
1
1
+
e
−
x
f(x)=\frac{1}{1+e^{-x}}
f(x)=1+e−x1
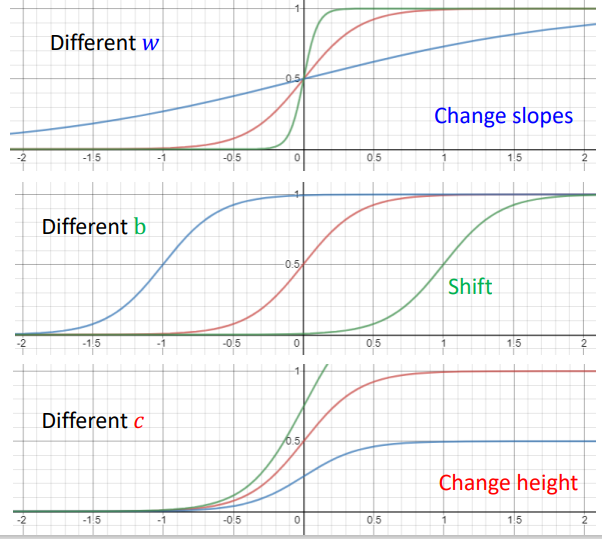
不同的w,b,c,会有不同的sigmoid形式,但顶多是对原图像进行平移,x或y方向进行伸缩:
所以之前的红色折线可以表示为0,1,2,3折线的相加:
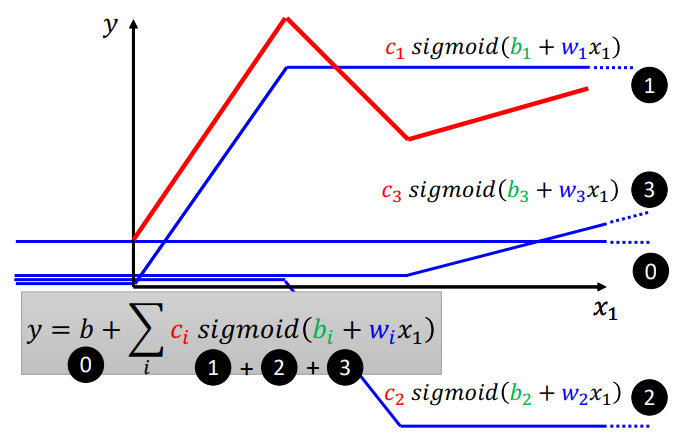
即:
y
=
b
+
∑
i
c
i
s
i
g
m
o
i
d
(
b
i
+
∑
j
w
i
j
x
i
)
y=b+\sum_i c_i sigmoid(b_i+\sum_j w_{ij}x_i)
y=b+i∑cisigmoid(bi+j∑wijxi)
i
i
i表示sigmoid的数量,
j
j
j表示特征的数目
以上图为例,为了得到这个分段线性函数,我们需要三个sigmoid,特征数目是3
写得更具体一点有:
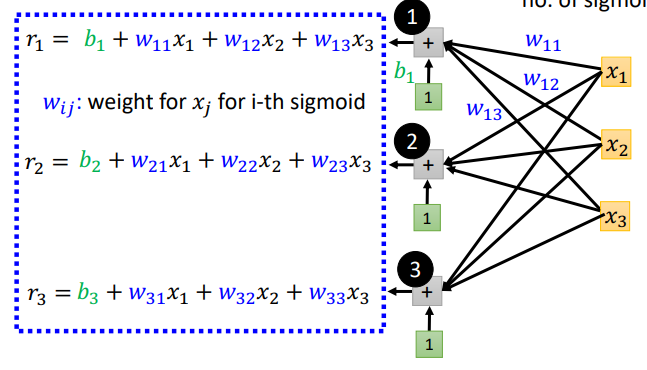
写成向量形式是:
r
⃗
=
b
⃗
+
W
⃗
×
X
⃗
\vec{r}=\vec{b}+\vec{W}\times \vec{X}
r=b+W×X
输出之后再经过sigmoid函数,最后再来一个线性变换:
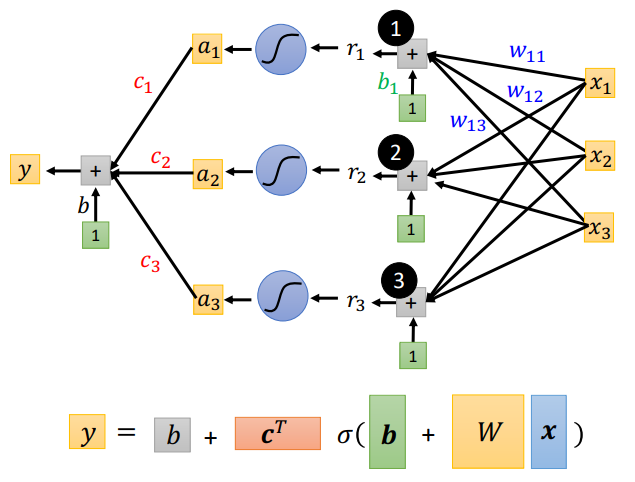
即:
y
=
b
+
c
T
σ
(
b
+
w
x
)
,
y
=
b
+
c
T
a
y=b+c^T \sigma(b+wx),y=b+c^Ta
y=b+cTσ(b+wx),y=b+cTa,
a
=
σ
(
r
)
,
r
=
b
+
w
x
a=\sigma(r),r=b+wx
a=σ(r),r=b+wx
(其中x是feature,b,c,w,x,r都是向量)
所以参数
θ
=
[
θ
1
,
θ
2
,
θ
3
,
⋯
]
=
[
w
1
,
w
2
,
⋯
,
b
1
,
b
2
,
⋯
,
c
1
,
c
2
,
⋯
]
\theta=[\theta_1,\theta_2,\theta_3,\cdots]=[w1,w2,\cdots,b1,b2,\cdots,c1,c2,\cdots]
θ=[θ1,θ2,θ3,⋯]=[w1,w2,⋯,b1,b2,⋯,c1,c2,⋯]
sigmoid的个数可以自己指定,理论上sigmoid个数越多,可以越逼近越复杂的函数
除了sgmoid函数,还有其他的也可以表示,比如Relu函数
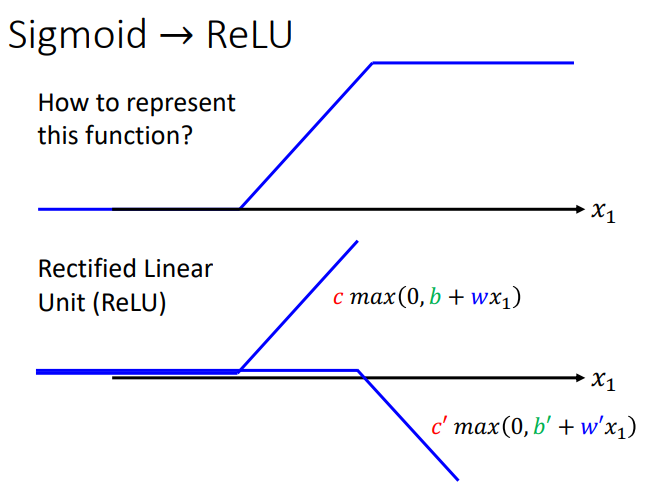
也是一样的写表达式:
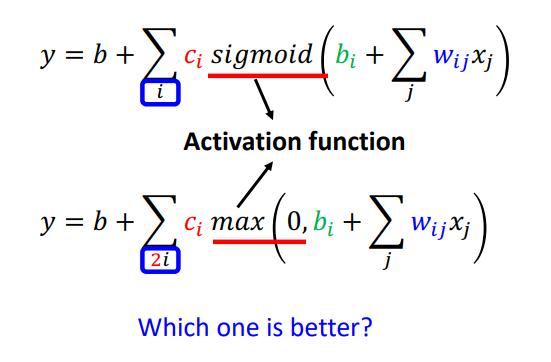
把sigmoid和Relu统称为激活函数。
接下来就是loss定义与最优化,在前一篇文章中已经讲过,不再赘述。
代码实战
pytorch训练基本步骤可参见:pytorch之完整的模型训练套路
0.准备工作:导入相关包设置参数等
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader, random_split
from torch import nn
import pandas as pd
import argparse
import csv
import os
import math
# 先定义命令行参数
parser = argparse.ArgumentParser()
parser.add_argument("--seed", type=int, default=2022, help="seed number")
parser.add_argument("--select_all", type=bool, default=True, help="Whether to use all features")
parser.add_argument("--valid_ratio", type=float, default=0.2, help="validation_size = train_size * valid_ratio")
parser.add_argument("--n_epochs", type=int, default=4, help="Number of epochs")
parser.add_argument("--batch_size", type=int, default=256, help="")
parser.add_argument("--lr", type=float, default=1e-5, help="learning rate")
parser.add_argument("--early_stop", type=int, default=400, help="If model has not improved for this epochs, stop training.")
parser.add_argument("--save_path", type=str, default="./model/my_model.pth", help="the directory of save model ")
args = parser.parse_args()
print(args) # 可以把参数输出来看一下
# 选择设备,GPU/CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device) # 看一下自己的设备(支不支持gpu)
# output:
Namespace(batch_size=64, early_stop=400, lr=1e-05, n_epochs=3000, save_path='./model/', seed=2022, select_all=True, valid_ratio=0.2)
cuda
1.数据预处理&有用的函数
"""2.3中需要用到的选择特征的函数"""
def select_feat(train_data, valid_data, test_data, select_all=True):
'''Selects useful features to perform regression'''
# 取训练集和验证集的最后一列(即输出值)作为y值
y_train, y_valid = train_data[:, -1], valid_data[:, -1]
# 取训练集,验证集的前117个特征作为输入x,测试集原本就是117维
raw_x_train, raw_x_valid, raw_x_test = train_data[:, :-1], valid_data[:, :-1], test_data
if select_all:
# 选择全部117个特征
feat_idx = list(range(raw_x_train.shape[1]))
else:
# 这里就是需要研究哪些特征和预测结果正相关
feat_idx = [0, 1, 2, 3, 4]
return raw_x_train[:, feat_idx], raw_x_valid[:, feat_idx], raw_x_test[:, feat_idx], y_train, y_valid
"""第五部分模型预测的函数"""
def predict(test_loader, model, device):
model.eval()
preds = []
for x in test_loader:
x = x.to(device)
with torch.no_grad():
pred = model(x)
preds.append(pred.detach().cpu())
# preds是list,长度为5,将所有的tensor展成一维,并转化为numpy
preds = torch.cat(preds, dim=0).numpy()
return preds
2.数据读取(Dataset&DataLoader)
2.1 先定义Dataset类
class Covid2019Data(Dataset):
"""
x: Features.
y: Targets, if none, do prediction.
"""
def __init__(self, x, y=None):
if y is None:
self.y = y
else:
self.y = torch.FloatTensor(y)
self.x = torch.FloatTensor(x)
def __getitem__(self, idx):
if self.y is None:
return self.x[idx]
else:
return self.x[idx], self.y[idx]
def __len__(self):
return len(self.x)
2.2 读取本地数据,划分训练集
# train_data size: 2699 x 118 (id + 37 states + 16 features x 5 days)
# test_data size: 1078 x 117 (without last day's positive rate)
train_data, test_data = pd.read_csv('./covid2019/train.csv').values, pd.read_csv('./covid2019/test.csv').values
train_data, valid_data = train_valid_split(train_data, args.valid_ratio, args.seed)
""" 将数据划分为训练集和验证集 """
def train_valid_split(data_set, valid_ratio, seed):
"""
:param data_set: Dataset类的数据,传入的是 train_data 和 test_data
:param valid_ratio: 验证集的比例(默认0.2)
:param seed: 随机种子
:return: 划分好的numpy类型的训练集和验证集
"""
# 先计算验证集的大小
valid_set_size = int(valid_ratio * len(data_set))
# 再计算训练集的大小(总的数据集减去验证集)
train_set_size = len(data_set) - valid_set_size
"""
# 开始随机划分
random_split(dataset: Dataset[T], lengths: Sequence[int],
generator: Optional[Generator] = default_generator) -> List[Subset[T]]:
"""
train_set, valid_set = random_split(data_set, [train_set_size, valid_set_size],
generator=torch.Generator().manual_seed(seed))
return np.array(train_set), np.array(valid_set)
# Print out the data size.
print("训练集的尺寸是:{}".format(train_data.shape))
print("验证集的尺寸是:{}".format(valid_data.shape))
print("测试集的尺寸是:{}".format(test_data.shape))
输出结果:
训练集的尺寸是:(2160, 118)
验证集的尺寸是:(539, 118)
测试集的尺寸是:(1078, 117)
2.3 将本地数据加载到 Dataset & DataLoader 中
# 选择特征,获得相应特征的训练集,测试集
x_train, x_valid, x_test, y_train, y_valid = select_feat(train_data, valid_data, test_data, args.select_all)
"""
x_train.shape:(2160,117)
x_valid.shape:(539,117)
x_test.shape:(1078,117)
y_train.shape:(2160,)
y_valid.shape:(539,)
"""
# Print out the number of features.
print("number of features:{}".format(x_train.shape[1]))
# output:number of features:117
train_dataset, valid_dataset, test_dataset = Covid2019Data(x_train,y_train),
Covid2019Data(x_valid, y_valid),
Covid2019Data(x_test)
# Pytorch data loader loads pytorch dataset into batches.
train_loader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True, pin_memory=True)
valid_loader = DataLoader(valid_dataset, batch_size=args.batch_size, shuffle=True, pin_memory=True)
test_loader = DataLoader(test_dataset, batch_size=args.batch_size, shuffle=False, pin_memory=True)
3.模型的搭建(nn.model)
class MyModel(nn.Module):
def __init__(self, input_dim):
super().__init__()
# 模型可以修改
self.model = nn.Sequential(
nn.Linear(input_dim, 16),
nn.ReLU(),
nn.Linear(16, 8),
nn.ReLU(),
nn.Linear(8, 1)
)
def forward(self, x):
output = self.model(x)
# 注意此时的output是(N,1),N是batch_size,所以需要压缩维度
output = output.squeeze(1)
return output
4. 定义训练函数
def trainer():
my_model = MyModel(input_dim=x_train.shape[1])
my_module = my_model.to(device)
# 线性回归,采用MSE损失函数
criterion = nn.MSELoss(reduction='mean')
criterion = criterion.to(device) # 同样把损失函数放到device设备
# 定义优化器
optim = torch.optim.SGD(my_module.parameters(), args.lr, momentum=0.9)
# Create directory of saving models.
if not os.path.isdir('./model'):
os.mkdir('./model')
best_loss = math.inf # 定义一个best_loss(正无穷大),每一轮的mean_valid_loss与其进行比较
early_stop_count = 0 # 定义记录早停止的变量
for epoch in range(args.n_epochs):
# 将模型设置为训练模式
my_module.train()
print("第{}轮训练开始:".format(epoch + 1))
# 定义一个loss列表变量,可以记录每一步的train loss
train_loss_record = []
for train_step, (x, y) in enumerate(train_loader):
x = x.to(device)
y = y.to(device)
pred = my_module(x)
# 计算模型输出和实际标签的loss
loss = criterion(pred, y)
# 梯度手动清零
optim.zero_grad()
# 后向传播,计算梯度
loss.backward()
# 优化器优化参数
optim.step()
# 将每一次的loss入队列
train_loss_record.append(loss.detach().item())
# 计算本轮次训练集上的平均loss
mean_train_loss = sum(train_loss_record) / len(train_loss_record)
# 同样定义一个loss列表变量,可以记录每一步的valid loss
valid_loss_record = []
# 将模型设置为测试模式
my_module.eval()
with torch.no_grad():
for x, y in valid_loader:
x, y = x.to(device), y.to(device)
pred = my_module(x)
loss = criterion(pred, y)
# 测试集loss,loss.item()可以避免显存爆炸
valid_loss_record.append(loss.item())
# 计算本轮次验证集上的平均loss
mean_valid_loss = sum(valid_loss_record) / len(valid_loss_record)
# 输出本轮次的训练loss和验证loss
print("Epoch:{}/{},train loss:{},valid loss:{}".format(epoch, args.n_epochs, mean_train_loss, mean_valid_loss))
if mean_valid_loss < best_loss:
best_loss = mean_valid_loss
torch.save(my_model.state_dict(), args.save_path) # Save your best model
print('Saving model with loss {:.3f}...'.format(best_loss))
early_stop_count = 0
# 如果本次的loss比上一次大,那么让early_stop_count数量+1
else:
early_stop_count += 1
# 如果early_stop_count数量达到设定值,则停止训练
if early_stop_count >= args.early_stop:
print('\nModel is not improving, so we halt the training session.')
return
5.开始训练&预测
if __name__ == '__main__':
# 开始训练,获得模型
trainer()
# 开始预测
my_model = MyModel(input_dim=x_train.shape[1]).to(device)
my_model.load_state_dict(torch.load(args.save_path))
preds = predict(test_loader, my_model, device)
# 开始将预测值写入文件
with open('pred.csv', 'w') as fp:
writer = csv.writer(fp)
writer.writerow(['id', 'tested_positive'])
for i, p in enumerate(preds):
writer.writerow([i, p])
运行结果:
跑完baseline之后,就开始炼丹了……










