一、数据集介绍
本实验使用自动驾驶的公开数据集BDD100K。
数据格式:BDD100K 数据集包含10万段高清视频,每个视频约40秒\720p\30 fps,总时间超过1,100小时。视频序列还包括GPS位置、IMU数据和时间戳;视频带有由手机记录的GPS/IMU信息,以显示粗略的驾驶轨迹,这些视频分别是从美国不同的地方收集的,并涵盖了不同的天气状况,包含晴天、阴天和雨天以及在白天和夜天的不同时间。每个视频的第10秒对关键帧进行采样,主要有这些标记:图像标签、道路对象边界框、可驾驶区域、车道标记和全帧实例分割,最终得到10万张图片(图片尺寸:1280*720 ),并进行标注。7万张图片为训练集,1万张图片为验证集,2万张为测试集。
标签类别:数据集中的GT框标签共有13个类别,分别为:person , rider , car , bus ,truck , bike , motor , tl_green , tl_red , tl_yellow , tl_none , t_sign , train ,总共约有184万个标定框。
 "
"
二、模型介绍yolov5
 "
"
YOLO网络由三个主要组件组成:
1)Backbone -在不同图像细粒度上聚合并形成图像特征的卷积神经网络。
2)Neck:一系列混合和组合图像特征的网络层,并将图像特征传递到预测层。
3)Head: 对图像特征进行预测,生成边界框和并预测类别。
输入端-输入端表示输入的图片。该网络的输入图像大小为608*608,该阶段通常包含一个图像预处理阶段,即将输入图像缩放到网络的输入大小,并进行归一化等操作。在网络训练阶段,YOLOv5使用Mosaic数据增强操作提升模型的训练速度和网络的精度;并提出了一种自适应锚框计算与自适应图片缩放方法。
基准网络-基准网络通常是一些性能优异的分类器种的网络,该模块用来提取一些通用的特征表示。YOLOv5中不仅使用了CSPDarknet53结构,而且使用了Focus结构作为基准网络。
Neck网络-Neck网络通常位于基准网络和头网络的中间位置,利用它可以进一步提升特征的多样性及鲁棒性。虽然YOLOv5同样用到了SPP模块、FPN+PAN模块,但是实现的细节有些不同。
Head输出端-Head用来完成目标检测结果的输出。针对不同的检测算法,输出端的分支个数不尽相同,通常包含一个分类分支和一个回归分支。YOLOv4利用GIOU_Loss来代替Smooth L1 Loss函数,从而进一步提升算法的检测精度。
 "
"
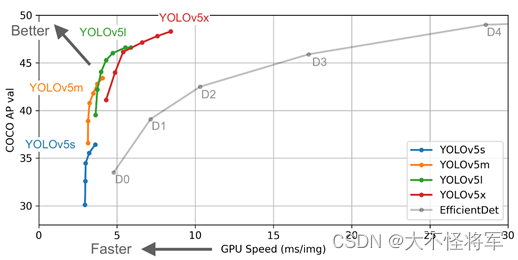
在yolov5目录下的model文件夹下是模型的配置文件,根据模型的规模不同设有4个模型:v5s、v5m、v5l、v5x,如上图所示是这些不同规模的模型与EfficientDet模型的性能对比图,性能逐渐增大(随着架构的增大,训练时间也是逐渐增大)。由于硬件设备有限,因此本文主要使用v5s的较小模型进行实验。
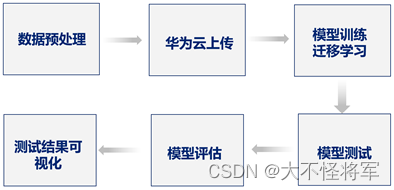
三、实现流程
 "
"
具体步骤:
- 下载bdd100k数据集,包括图片和标注文件。
- 安装yolov5,下载预训练模型。
- 将bdd100k数据集转换为yolov5可读取的格式。
- 上传华为云,对预训练后的模型进行训练和测试。
- 对训练和测试结果进行分析和评估,可以使用各种评估指标来评估模型的性能,例如精度、召回率、F1值等。
四、数据预处理
读取数据,只取需要的13个标签,去除不必要的数据(天气情况等),将数据转化为coco格式,该格式是一种常用的图像识别和物体检测数据集格式。再将得到的coco格式数据转化为yolo格式,以txt存储,其中包含五个数据。将每张图片中含有的标签合集作为一个txt保存。
 "
"
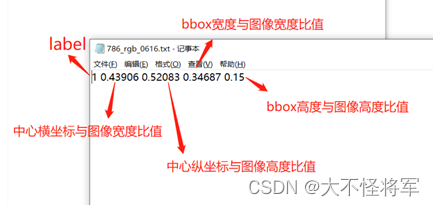
如上图所示,每个目标对应的bounding box包含信息:
- bounding box中心x坐标x_center,
- bounding box中心y坐标y_center,
- bounding box的宽width,
- bounding box的高height。
需要注意几点: - 这4个信息均要被归一化为0-1之间的值,
- 这4个信息前加上目标类别class总共5列信息即TXT文件中的标签信息,
- 类别的索引从0开始。
五、模型训练
1、定义yolov5检测器
img: 定义输入图像的大小
batch: 确定批次的大小
epochs: 定义训练周期的数量
data: 设置.yaml文件路径
cfg: 指定模型配置
weights: 指定权重的自定义路径
name: 结果名称
nosave: 仅保存最终检查点
cache: 缓存图像以加速训练速度
2、训练方式
(1)从头开始训练
 “
“
图6 预训练
该处使用yolov5s.pt预训练模型训练了300个epochs,其中设置的图片大小为640*640,batch(size)设为32。其性能评估结果如下图所示:

(2)迁移学习
 "
"
迁移学习是一种将一个训练模型学习到的表征或信息用于另一个需要针对不同数据和相似或不同任务进行训练的模型的方法。这里我们使用的是yolov5s.pt权重文件。训练时所使用的是华为云平台,将预处理完成后的yolo格式文件的数据包以zip导入并解压后,下载yolov5预处理权重后对数据进行训练。Epoch设定为230,运行时间总长约120h+。
①部分训练数据的可视化如下图:

"
②训练集ground truth(带标签):

"
③验证集预测结果(含置信度): 图为第一批验证集

"
六、模型测试
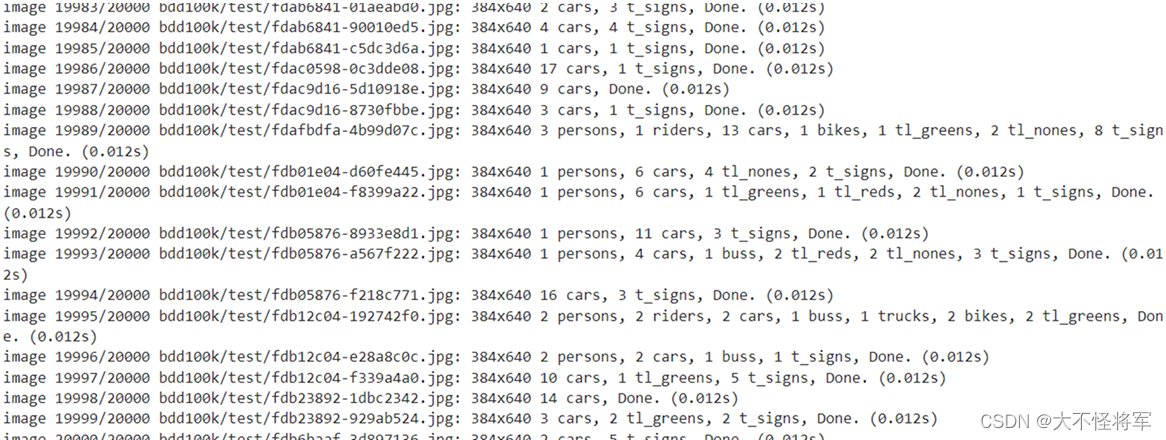
利用训练好的模型权重在验证集上进行测验,输出分类结果。20000张图片每张图像中含有的类别,及每个类别所含有的数量。
"
测试集上预测结果如下图所示:
 "
"
七、模型评价指标
1、评价指标定义
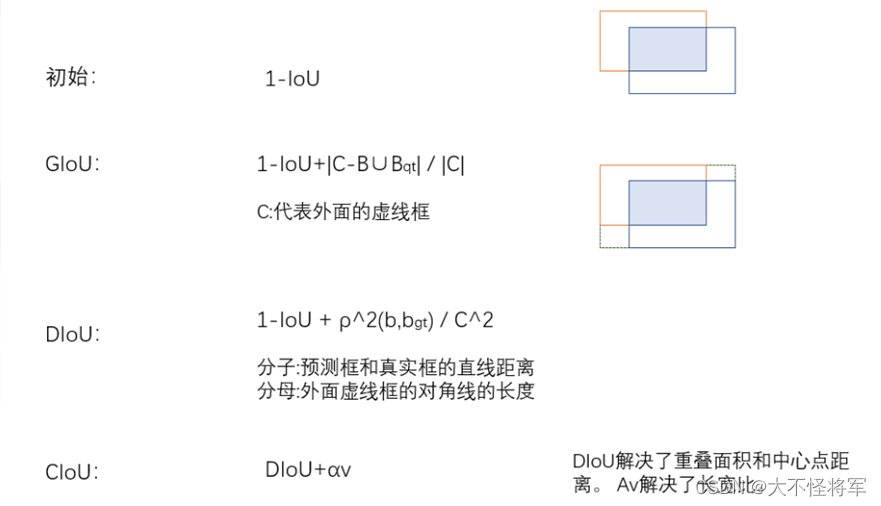
①GIoU Loss :目标检测损失函数
GIoU的目标相当于在损失函数中加入了一个ground truth和预测框构成的闭包的惩罚,它的惩罚项是闭包减去两个框的并集后的面积在闭包中的比例越小越好,如图3所示,闭包是红色虚线的矩形,我们要最小化阴影部分的面积除以闭包的面积。
②边框回归:采用了CIoU
③Objectness:置信度损失,采用了BCEWithLogitsLoss和CIoU,用于监督grid中是否存在物体,计算网络的置信度
④Classification:分类损失,采用了交叉熵损失函数BCEWithLogitsLoss
⑤Precision:精确度
⑥Recall:召回率
⑦MAP:全类平均正确率,对所有类别检测的平均正确率(AP)进行综合加权平均。
"
2、可视图对比
①官方结果:
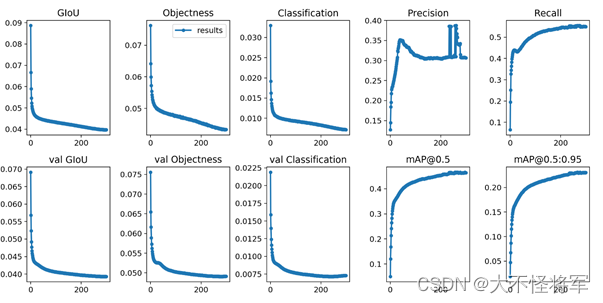 "
"
②自训练时epoch设定为230的结果:
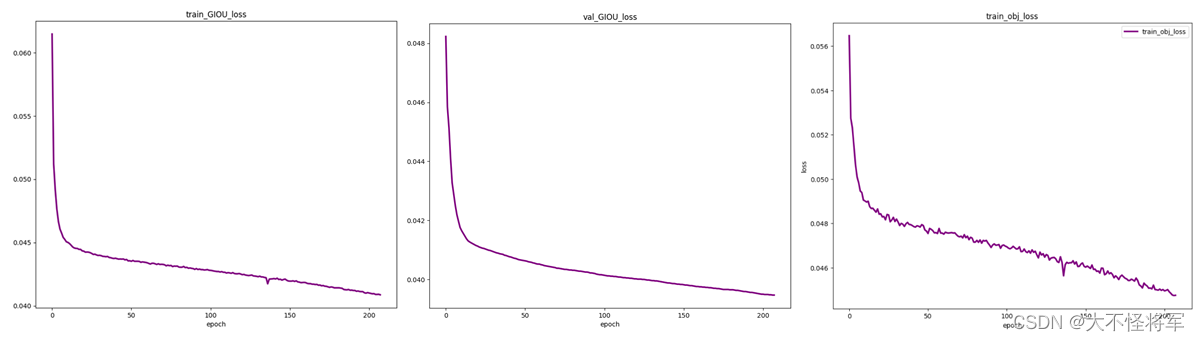 "
"
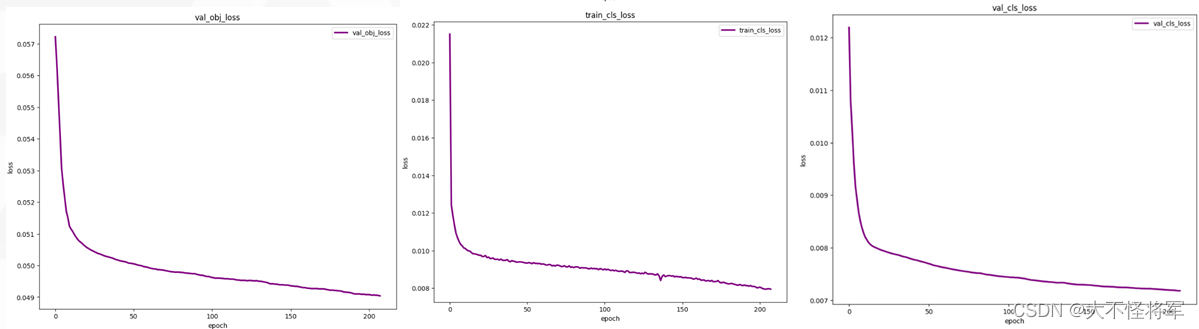 "
"
 "
"
由图可得,训练集和测试集的目标检测损失函数和置信度损失最终均下降至0.04左右,分类损失则下降到0.008左右,MAP近似于0.47,recall近似于0.55。
编写不易,求个点赞!!!!!!!
“你是谁?”
“一个看帖子的人。”
“看帖子不点赞啊?”
“你点赞吗?”
“当然点了。”
“我也会点。”
“谁会把经验写在帖子里。”
“写在帖子里的那能叫经验贴?”
“上流!”
cheer!!!









