
Nginx的事件驱动模型
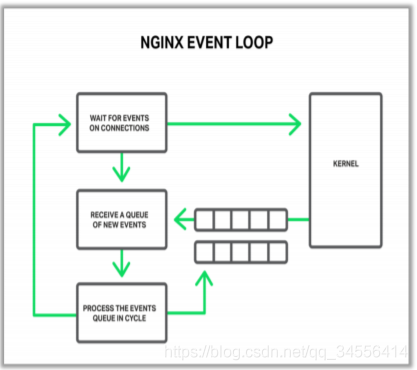
当 Nginx 刚刚启动时,在等待事件部分,也就是打开了 80 或 443 端口,这个时候在等待新的事件进来,比如新的客户端连上了 Nginx 向我们发起了连接,此步往往对应 epoll 的 epoll wait 方法,这个时候的 Nginx 其实是处于 sleep 这样一个进程状态的。当操作系统收到了一个建立 TCP 连接的握手报文时并且处理完握手流程以后,操作系统就会通知 epoll wait 这个阻塞方法,告诉它可以往下走了,同时唤醒 Nginx worker 进程。
接着往下走之后,会去找操作系统索要要事件,操作系统会把他准备好的事件,放在事件队列中,从这个事件队列中可以获取到需要处理的事件。比如建立连接或者收到一个 TCP 请求报文。
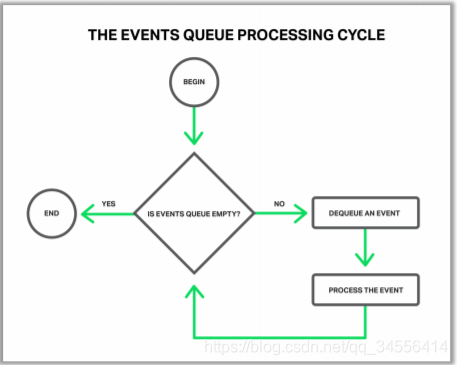
取出以后就会进行循环处理事件,如上就是处理事件的一个循环:当发现队列中不为空,就把事件取出来开始处理事件;在处理事件的过程中,可能又生成新的事件,比如说发现一个连接新建立了,可能要添加一个超时时间,比如默认的 60 秒,也就是说 60 秒之内如果浏览器不向 Nginx 发送请求的话,Nginx 就会把这个连接关掉;又比如说当 Nginx 发现已经收完了完整的 HTTP 请求以后,可以生成 HTTP 响应了,那么这个生成响应是需要 Nginx 可以向操作系统的写缓存中心里面去把响应写进去,要求操作系统尽快的把这样一段响应内容发到浏览器上,也就是说可能在处理过程中可能会产生新的事件,就是循环处理事件部分指向的事件队列部分,等待下一次来处理。
如果所有的事件都处理完成以后呢,又会返回到等待事件部分。
在学习了 Nginx 事件循环后,我们再去理解有时候使用一些第三方模块,这些第三方模块可能会做大量的 CPU 运算,这样的计算任务会导致处理一个事件的时间非常的长;在上面的一个流程图中,可以看到会导致队列中的大量事件会长时间得不到处理,从而引发恶性循环,所以 Nginx 不能容忍有些第三方模块长时间的消耗大量的 CPU 进行计算任务。我们可以看到像 GZIP 这样的模块,他们都不会在一次使用大量的 CPU 而是分段使用,这些都与 Nginx 的事件循环有关的。
上面主要描述了 Nginx 是如何处理事件的以及 Nginx 事件循环的流程是怎么样的,为下一步讲解 Nginx 事件循环流程中是如何从操作系统中获取等待处理的事件做铺垫,并且通过事件循环了解到为什么 Nginx 不期望第三方模块中出现大量 CPU 的计算任务。
Nginx事件循环带来的后果
- 第三方模块做大量的CPU计算,导致我处理一个事件会特别长,会导致后续队列中的大量事件长事件得不到处理
- 所以nginx无法容忍第三方模块长时间使用CPU执行计算任务
- 我们看到gzip模块不是一次计算而是分段计算
epoll的原理
场景描述
有100万用户同时与一个进程保持着TCP连接,而每一时刻只有几十个或几百个TCP连接是活跃的(接收到TCP包),也就是说,在每一时刻,进程只需要处理这100万连接中的一小部分连接。那么,如何才能高效地处理这种场景呢?进程是否在每次询问操作系统收集有事件发生的TCP连接时,把这100万个连接告诉操作系统,然后由操作系统找出其中有事件发生的几百个连接呢?
select和poll如何处理
select每次收集事件时,都把这100万连接的套接字传给操作系统(这首先就是用户态内存到内核态内存的大量复制),而由操作系统内核寻找这些连接上有没有未处理的事件,将会是巨大的资源浪费,这里有个非常明显的问题,即在某一时刻,进程收集有事件的连接时,其实这100万连接中的大部分都是没有事件发生的。
epoll如何处理
它在Linux内核中申请了一个简易的文件系统,把原先的一个select或者poll调用分成了3个部分:
- 调用 epoll_create建立1个epoll对象(在epoll文件系统中给这个句柄分配资源)
- 调用 epoll_ctl向epoll对象中添加这100万个连接的套接字
- 调用 epoll_wait收集发生事件的连接。
这样,只需要在进程启动时建立1个epoll对象,并在需要的时候向它添加或删除连接就可以了,因此,在实际收集事件时,epoll_wait的效率就会非常高,因为调用epoll_wait时并没有向它传递这100万个连接,内核也不需要去遍历全部的连接。
epoll是基于回调函数的,无轮询。如果当套接字比较多的时候,每次select()都要通过遍历FD_SETSIZE个Socket来完成调度,不管哪个Socket是活跃的,都遍历一遍。这会浪费很多CPU时间。如果能给套接字注册某个回调函数,当他们活跃时,自动完成相关操作,那就避免了轮询,这正是epoll(Linux)、kqueue(FreeBSD)、/dev/poll(soloris)做的。举个经典例子,假设你在大学读书,住的宿舍楼有很多间房间,你的朋友要来找你。select版宿管大妈就会带着你的朋友挨个房间去找,直到找到你为止。而epoll版宿管大妈会先记下每位同学的房间号,你的朋友来时,只需告诉你的朋友你住在哪个房间即可,不用亲自带着你的朋友满大楼找人。如果来了10000个人,都要找自己住这栋楼的同学时,select版和epoll版宿管大妈,谁的效率更高,不言自明。同理,在高并发服务器中,轮询I/O是最耗时间的操作之一,select、epoll、/dev/poll的性能谁的性能更高,同样十分明了。
关于epoll的实现原理,本文不会具体介绍,这里只是介绍epoll的工作流程,epoll的使用是三个函数:
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
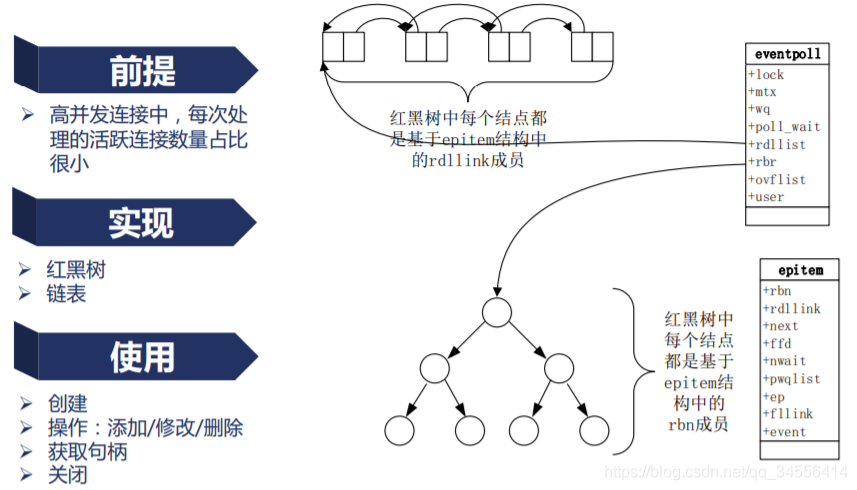
首先epoll_create函数会在内核中创建一块独立的内存存储一个eventpoll结构体,该结构体包括一颗红黑树和一个链表,如下图所示:

然后通过epoll_ctl函数,可以完成两件事。
- (1)将事件添加到红黑树中,这样可以防止重复添加事件;
- (2)将事件与网卡建立回调关系,当事件发生时,网卡驱动会回调ep_poll_callback函数,将事件添加到epoll_create创建的链表中。
最后,通过epoll_wait函数,检查并返回链表中是否有事件。该函数是阻塞函数,阻塞时间为timeout,当双向链表有事件或者超时的时候就会返回链表长度(发生事件的数量)。
这是如何实现的
维护了一个epitem的数据结构,他通过两种数据结构把这两件事件分开实现,也就是Nginx每次取活跃连接的时候,我们只需要去遍历一个链表,这个链表里仅仅只有活跃的的连接、这样我们速度效率就会很高
1、创建:Nginx收到80端口建立连接的请求,请求连接成功以后,这时候我要添加一个读事件,这个读事件是用来读取http消息的,这个时候我可能会添加一个新的事件、或者是写事件,这个添加我只会放到红黑树中,二叉平衡树能保证我的插入效率是logn的复杂度
2、添加:当操作系统接收到网卡中发送来一个报文的时候,这个链表就会增加一个链接
3、修改:读取一个事件的时候链表自然就没了
4、删除:如果我我不想再处理读事件和写事件,我只要从这个平衡二叉树移除一个节点
5、获取句柄:就是遍历活跃链接的链表,从内核态读取到用户态










