本文已收录github:https://github.com/BigDataScholar/TheKingOfBigData,里面有大数据高频考点,Java一线大厂面试题资源,上百本免费电子书籍,作者亲绘大数据生态圈思维导图…持续更新,欢迎star!
前言
之前开发过一个画像项目,并为大家介绍了项目过程中部分开发的细节,例如PSM,RFE,USG等模型的标签开发落地。但是后来考虑到对于没有画像开发经验,尤其是零基础的大数据小白而言不是很友好,理解起来也不是很容易。正好最近在看赵宏田老师的《用户画像|方法论与工程化解决方案》,所以,我又专门开了一个专题,打算重新为大家讲解关于用户画像的知识。感兴趣的小伙伴记得关注加星标,每天第一时间收获技术干货!
1. 用户画像是什么?
在互联网步入大数据时代后,用户行为给企业的产品和服务带来了一系列的改变和重塑,其中最大的变化在于,用户的一切行为在企业面前是可“追溯”“分析”的。企业内保存了大量的原始数据和各种业务数据,这是企业经营活动的真实记录,如何更加有效地利用这些数据进行分析和评估,成为企业基于更大数据量背景的问题所在。随着大数据技术的深入研究与应用,企业的关注点日益聚焦在如何利用大数据来为精细化运营和精准营销服务,而要做精细化运营,首先要建立本企业的用户画像。
1.1 画像简介
用户画像,即用户信息标签化,通过收集用户的社会属性、消费习惯、偏好特征等各个维度的数据,进而对用户或者产品特征属性进行刻画,并对这些特征进行分析、统计,挖掘潜在价值信息,从而抽象出用户的信息全貌,如图1-1所示。用户画像可看作企业应用大数据的根基,是定向广告投放与个性化推荐的前置条件,为数据驱动运营奠定了基础。由此看来,如何从海量数据中挖掘出有价值的信息越发重要。

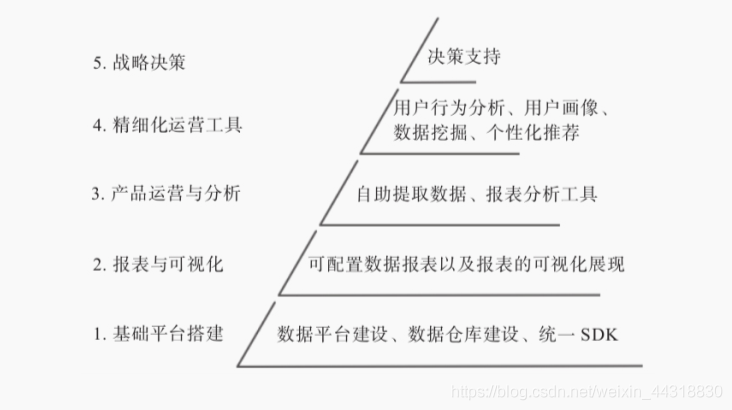
大数据已经兴起多年,其对于互联网公司的应用来说已经如水、电、空气对于人们的生活一样,成为不可或缺的重要组成部分。从基础设施建设到应用层面,主要有数据平台搭建及运维管理、数据仓库开发、上层应用的统计分析、报表生成及可视化、用户画像建模、个性化推荐与精准营销等应用方向。
很多公司在大数据基础建设上投入很多,也做了不少报表,但业务部门觉得大数据和传统报表没什么区别,也没能体会大数据对业务有什么帮助和价值,究其原因,其实是“数据静止在数据仓库,是死的”。
而用户画像可以帮助大数据“走出”数据仓库,针对用户进行个性化推荐、精准营销、个性化服务等多样化服务,是大数据落地应用的一个重要方向。数据应用体系的层级划分如图1-2所示。
1.2 标签类型
用户画像建模其实就是对用户“打标签”,从对用户打标签的方式来看,一般分为3种类型(如图1-3所示):①统计类标签;②规则类标签;③机器学习挖掘类标签。

下面我们介绍这3种类型的标签的区别:
1.统计类标签
这类标签是最为基础也最为常见的标签类型,例如,对于某个用户来说,其性别、年龄、城市、星座、近7日活跃时长、近7日活跃天数、近7日活跃次数等字段可以从用户注册数据、用户访问、消费数据中统计得出。该类标签构成了用户画像的基础。
2.规则类标签
该类标签基于用户行为及确定的规则产生。例如,对平台上“消费活跃”用户这一口径的定义为“近30天交易次数≥2”。在实际开发画像的过程中,由于运营人员对业务更为熟悉,而数据人员对数据的结构、分布、特征更为熟悉,因此规则类标签的规则由运营人员和数据人员共同协商确定;
3.机器学习挖掘类标签
该类标签通过机器学习挖掘产生,用于对用户的某些属性或某些行为进行预测判断。例如,根据一个用户的行为习惯判断该用户是男性还是女性、根据一个用户的消费习惯判断其对某商品的偏好程度。该类标签需要通过算法挖掘产生。
在项目工程实践中,一般统计类和规则类的标签即可以满足应用需求,在开发中占有较大比例。机器学习挖掘类标签多用于预测场景,如判断用户性别、用户购买商品偏好、用户流失意向等。一般地,机器学习标签开发周期较长,开发成本较高,因此其开发所占比例较小
2. 数据架构
在整个工程化方案中,系统依赖的基础设施包括Spark、Hive、HBase、Airflow、MySQL、Redis、Elasticsearch。除去基础设施外,系统主体还包括 Spark Streaming、ETL、产品端 3个重要组成部分。图 2-1 所示是用户画像数仓架构图,下面对其进行详细介绍。
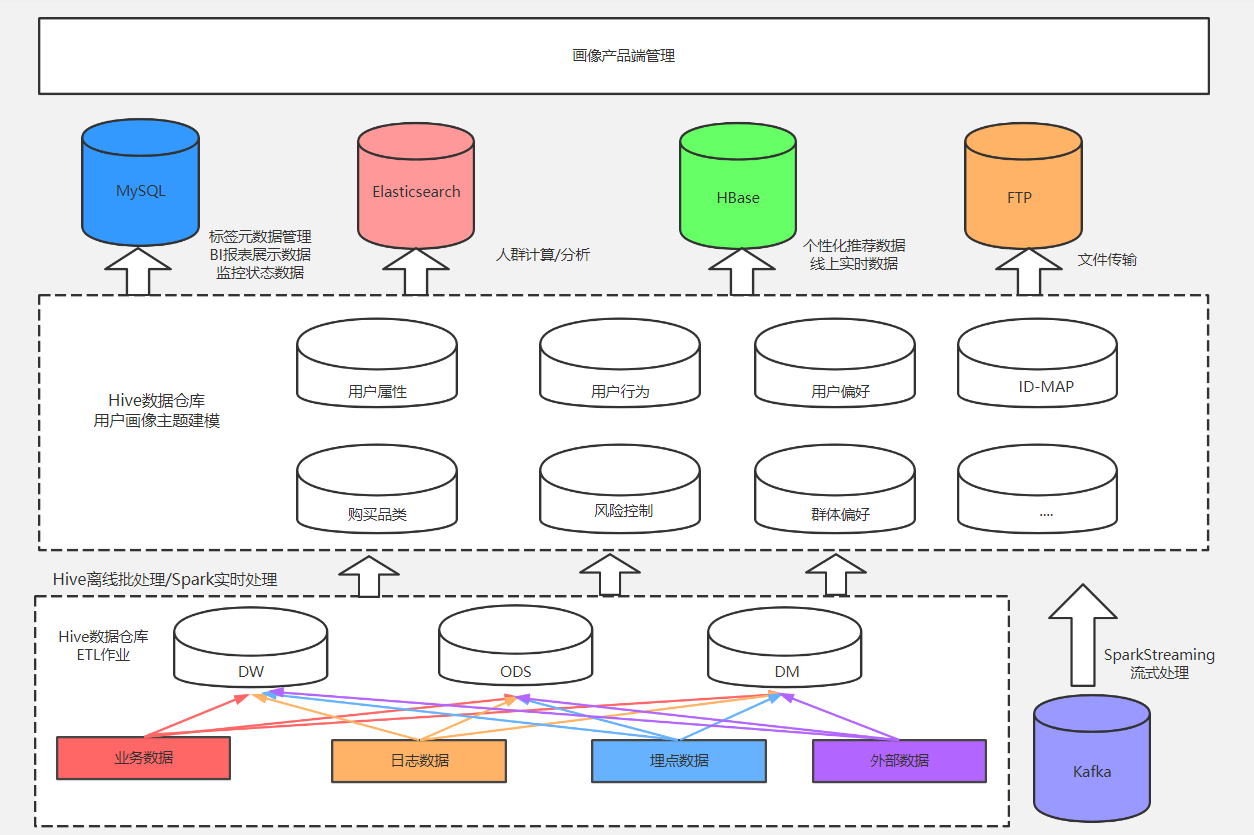
图1-4 下方虚线框中为常见的数据仓库ETL加工流程,也就是将每日的业务数据、日志数据、埋点数据等经过ETL过程,加工到数据仓库对应的ODS层、DW层、DM层中。
中间的虚线框即为用户画像建模的主要环节,用户画像不是产生数据的源头,而是对基于数据仓库ODS层、DW层、DM层中与用户相关数据的二次建模加工。在ETL过程中将用户标签计算结果写入Hive,由于不同数据库有不同的应用场景,后续需要进一步将数据同步到MySQL、HBase、Elasticsearch 等数据库中。
- Hive:存储用户标签计算结果、用户人群计算结果、用户特征库计算结果
- MySQL:存储标签元数据,监控相关数据,导出到业务系统的数据
- HBase:存储线上接口实时调用类数据
- Elasticserch:支持海量数据的实时查询分析,用于存储用户人群计算、用户群透视分析所需的用户标签数据(由于用户人群计算、用户群透视分析的条件转化成的SQL语句多条件嵌套较为复杂,使用 Impala 执行也需花费大量时间)
用户标签数据在Hive中加工完成后,部分标签通过Sqoop同步到MySQL数据库,提供用于BI报表展示的数据、多维透视分析数据、圈人服务数据;另一部分标签同步到HBase数据库用于产品的线上个性化推荐
3. 主要覆盖模块
搭建一套用户画像方案整体来说需要考虑8个模块的建设,如图3-1所示。
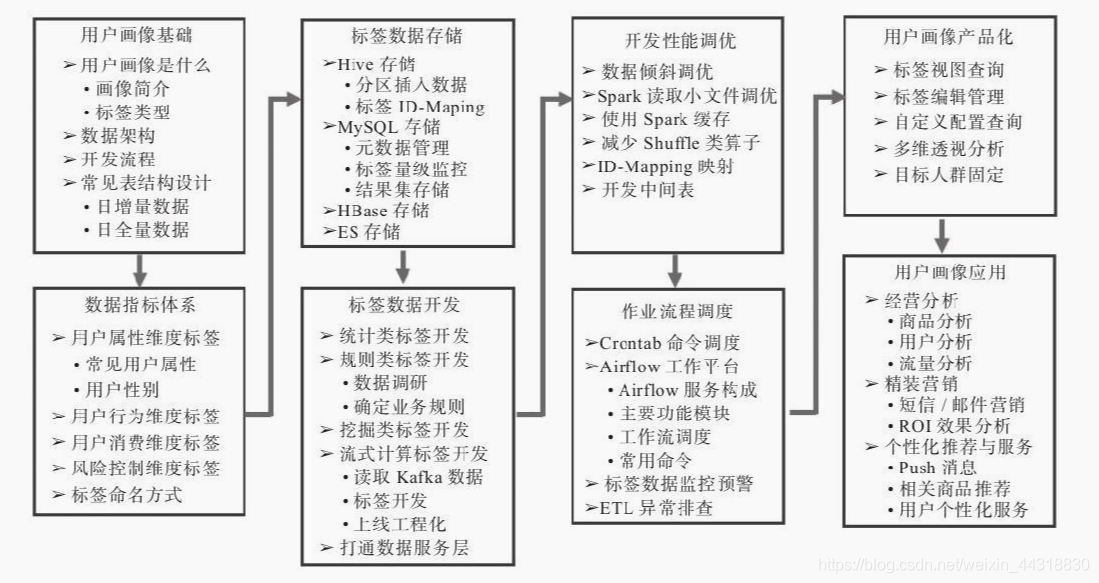
- 用户画像基础:需要了解、明确用户画像是什么,包含哪些模块,数据仓库架构是什么样子,开发流程,表结构设计,ETL设计等。这些都是框架,大方向的规划,只有明确了方向后续才能做好项目的排期和人员投入预算。这对于评估每个开发阶段重要指标和关键产出非常重要。
- 数据指标体系:根据业务线梳理,包括用户属性、用户行为、用户消费、风险控制等维度的指标体系。
- 标签数据存储:标签相关数据可存储在Hive、MySQL、HBase、Elasticsearch等数据库中,不同存储方式适用于不同的应用场景。
- 标签数据开发:用户画像工程化的重点模块,包含统计类、规则类、挖掘类、流式计算类标签的开发,以及人群计算功能的开发,打通画像数据和各业务系统之间的通路,提供接口服务等开发内容。
- 开发性能调优:标签加工、人群计算等脚本上线调度后,为了缩短调度时间、保障数据的稳定性等,需要对开发的脚本进行迭代重构、调优。
- 作业流程调度:标签加工、人群计算、同步数据到业务系统、数据监控预警等脚本开发完成后,需要调度工具把整套流程调度起来。
- 用户画像产品化:为了能让用户数据更好地服务于业务方,需要以产品化的形态应用在业务上。产品化的模块主要包括标签视图、用户标签查询、用户分群、透视分析等。
- 用户画像应用:画像的应用场景包括用户特征分析、短信、邮件、站内信、Push消息的精准推送、客服针对用户的不同话术、针对高价值用户的极速退货退款等VIP服务应用。
4. 开发阶段流程
下面主要介绍画像系统开发上线的流程以及各阶段的关键产出。
4.1 开发上线流程
用户画像建设项目流程,如图4-1

第一阶段:目标解读
在建立用户画像前,首先需要明确用户画像服务于企业的对象,再根据业务方需求,明确未来产品建设目标和用户画像分析之后的预期效果。
一般而言,用户画像的服务对象包括运营人员和数据分析人员。不同业务方对用户画像的需求有不同的侧重点,就运营人员来说,他们需要分析用户的特征、定位用户行为偏好,做商品或内容的个性化推送以提高点击转化率,所以画像的侧重点就落在了用户个人行为偏好上;就数据分析人员来说,他们需要分析用户行为特征,做好用户的流失预警工作,还可根据用户的消费偏好做更有针对性的精准营销。
第二阶段:任务分解与需求调研
经过第一阶段的需求调研和目标解读,我们已经明确了用户画像的服务对象与应用场景,接下来需要针对服务对象的需求侧重点,结合产品现有业务体系和“数据字典”规约实体和标签之间的关联关系,明确分析维度。
第三阶段:需求场景讨论与明确
在本阶段,数据运营人员需要根据与需求方的沟通结果,输出产品用户画像需求文档,在该文档中明确画像应用场景、最终开发出的标签内容与应用方式,并就该文档与需求方反复沟通并确认无误。
第四阶段:应用场景与数据口径确认
经过第三个阶段明确了需求场景与最终实现的标签维度、标签类型后,数据运营人员需要结合业务与数据仓库中已有的相关表,明确与各业务场景相关的数据口径。在该阶段中,数据运营方需要输出产品用户画像开发文档,该文档需要明确应用场景、标签开发的模型、涉及的数据库与表以及应用实施流程。该文档不需要再与运营方讨论,只需面向数据运营团队内部就开发实施流程达成一致意见即可。
第五阶段:特征选取与模型数据落表
本阶段中数据分析挖掘人员需要根据前面明确的需求场景进行业务建模,写好 HQL 逻辑,将相应的模型逻辑写入临时表中,并抽取数据校验是否符合业务场景需求。
第六阶段:线下模型数据验收与测试
数据仓库团队的人员将相关数据落表后,设置定时调度任务,定期增量更新数据。数据运营人员需要验收数仓加工的 HQL 逻辑是否符合需求,根据业务需求抽取表中数据查看其是否在合理范围内,如果发现问题要及时反馈给数据仓库人员调整代码逻辑和行为权重的数值。
第七阶段:线上模型发布与效果追踪
经过第六阶段,数据通过验收之后,会通过Git进行版本管理,部署上线。使用Git进行版本管理,上线后通过持续追踪标签应用效果及业务方反馈,调整优化模型及相关权重配置。
4.2 各阶段关键产出
为保证程序上线的准时性和稳定性,需要规划好各阶段的任务排期和关键产出。画像体系的开发分为几个主要阶段,包括前期指标体系梳理、用户标签开发、ETL调度开发、打通数据服务层、画像产品端开发、面向业务方推广应用、为业务方提供营销策略的解决方案等,如表4-2 所示。

- 标签开发:根据业务需求和应用场景梳理标签指标体系,调研业务上定义的数据口径,确认数据来源,开发相应的标签。标签开发在整个画像项目周期中占有较大比重。
- ETL调度开发:梳理需要调度的各任务之间的依赖关系,开发调度脚本及调度监控告警脚本,上线调度系统。
- 打通服务层接口:为了让画像数据走出数据仓库,应用到用户身上,需要打通数据仓库和各业务系统的接口。
- 画像产品化:需要产品经理与业务人员、技术开发人员一起对接业务需求点和产品功能实现形式,画产品原型,确定工作排期。Java Web端开发完成后,需要数据开发人员向对应的库表中灌入数据。
- 开发调优:在画像的数据和产品端搭建好架构、能提供稳定服务的基础上,为了让调度任务执行起来更加高效、提供服务更加稳健,需要对标签计算脚本、调度脚本、数据同步脚本等相关计算任务进行重构优化。
5. 画像应用的落地
用户画像最终的价值还是要落地运行,为业务带来实际价值。这里需要开发标签的数据工程师和需求方相互协作,将标签应用到业务中。否则开发完标签后,数据还是只停留在数据仓库中,没有为业务决策带来积极作用。
画像开发过程中,还需要开发人员组织数据分析、运营、客服等团队的人员进行画像应用上的推广。对于数据分析人员来说,可能会关注用户画像开发了哪些表、哪些字段以及字段的口径定义;对运营、客服等业务人员来说,可能更关注用户标签定义的口径,如何在Web端使用画像产品进行分析、圈定用户进行定向营销,以及应用在业务上数据的准确性和及时性。
只有业务人员在日常工作中真正应用画像数据、画像产品,才能更好地推动画像标签的迭代优化,带来流量提升和营收增长,产出业绩价值
小结
本期内容从用户画像的定义出发,依次为大家介绍了用户画像的数据架构,和主要的覆盖模块,最后简单介绍了一下用户画像的开发阶段流程,以及画像应用如何实际落地。总体来说,可谓干货满满,对于零基础小白而言我相信更是打开了新世界的大门(〃‘▽’〃)。之后我可能会更新一些关于用户画像其他开发方向的内容,例如数据存储,性能调优,任务流调度等内容,敬请期待!受益的朋友记得三连,我是Alice,我们下一期见!
你知道的越多,你不知道的也越多!
文章持续更新,可以微信搜一搜「 猿人菌 」第一时间阅读,思维导图,大数据书籍,大数据高频面试题,海量一线大厂面经…期待您的关注!










