©原创作者 | 疯狂的Max
01 背景及动机
Transformer是目前NLP预训练模型的基础模型框架,对Transformer模型结构的改进是当前NLP领域主流的研究方向。
Transformer模型结构中每层都包含着残差结构,而残差结构中最原始的结构设计是Post-LN结构,即把Layer Norm (LN) 放在每个子层处理之后,如下图Figure 1(a)所示;而其他的一些预训练模型如GPT-2,则将LN改到每个子层处理之前,被定义为Pre-LN,如下图Figure 1(b),有论文[5]结果表明“Pre-LN”对梯度下降更加友好,收敛更快,更易于超参优化,但其性能总差于“Post-LN”。
为解决这个问题,本文作者提出 RealFormer 模型(Residual Attention Layer Transformer),如下图Figure 1(c)所示,将残差结构运用到attention层,使得模型对训练超参更具鲁棒性的同时,保证模型性能的提升。
而残差结构来源于图像领域经典的Resnet模型[6],可以有效解决深层神经网络中的梯度弥散/扩散和网络退化的问题[7],NLP领域Transformer经典结构[2]同图像领域模型一样,也拥有“窄而深”的模型,因此也当然可以通过残差结构来达到优化网络的目的,这也是Transformer结构中本身就设计了残差结构的原因。
具体来说,RealFormer相较于前面提到的两种结构(“Pre-LN”和“Post-LN”)不同在于,模型在每层中计算所有头的attention score时,加上了残差结构,即本层的attention score加上之前层的attention score。
值得注意的是,直接在attention计算时增加跳连连接并不会增加指数级的运算量,因此其效率是相对可观的。

本文的主要贡献在于:
1)RealFormer是一种在原始Transformer结构上的简单改进,只需要修改几行代码并且不需要过多的超参调整;
2)RealFormer的表现在不同规模的模型上都优于Post-LN和Pre-LN结构的模型;
3)RealFormer在包括GLUE在内的各种下游任务中提升了原始BERT的表现,并且当训练轮数只有一半时也可以到达相应的最强基线模型标准;
4)作者通过量化分析的方式证明了RealFormer与基线BERT模型相比,每层的attention更为稀疏和强关联,这样的正则化效果也有利于模型的稳定训练,并使得模型对超参调节更具有鲁棒性。
02 模型方法
1.标准Transformer模型结构
Transformer由encoder和decoder组成,两者的结构相似,以其encoder中一层来进行说明。Transformer层由2个子层构成,第一个子层包含多头注意力模块和对应的残差连接,第二个子层包含一个全连接的前向网络模块和对应的残差链接。Post-LN和Pre-LN的区别在于,Layer Norm在残差连接之前或之后。
2.残差式Attention层的Transformer结构
RealFormer沿用了Post-LN的模型设计,只是在每个Transformer层计算多头注意力事,加入前一层的Attention Scores矩阵。即计算第n层的注意力矩阵时,从公式(1)变为了公式(2)。

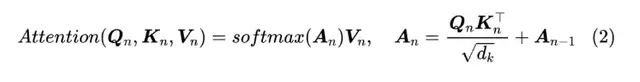
实现以上计算方式的改变只需要在Transformer的模型代码中做很少的代码改动,并且网络中不止一种类型的attention模块时也适用。
比如,在机器翻译模型中的encoder-encoder self-attention,encoder-decoder attention,decoder-decoder self-attention的模块都可以直接运用这样的计算改进方案。
03 实验结果
1.预训练任务实验结果
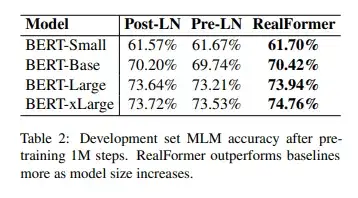
首先,从预训练任务的表现结果来看,在不同规模的模型之下,RealFormer模型表现都优于其他两种结构。而随着模型规模的扩大,RealFormer结构的优势表现的更为明显,如下表Table 2所示。
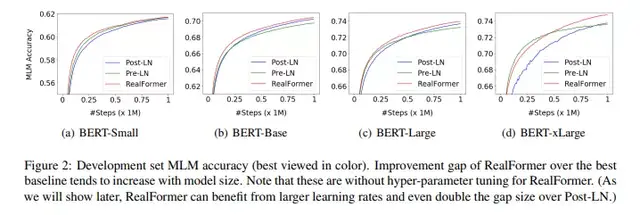
另外,作者推测越大的模型更难以训练,而Post-LN的结构存在不稳定性。并且在xLarge的规模之下甚至会不收敛。RealFormer结构有助于模型的正则化和使得训练更加稳定,如下图Figure 2所示。
2.下游任务实验结果
三种模型在下游任务实验结果如下表Table 4所示:

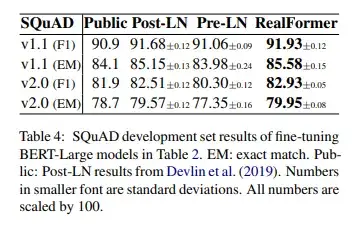
在GLUE的各项下游任务和SQuAD下游任务的实验结果来看,RealFormer的表现是最佳的。
3.研究问题
1)在只有一半预训练算力预算的基础下,RealFormer效果如何?
在1M训练步数的情况下,RealFormer的表现超越了Post-LN和Pre-LN。那么在训练算力限制更为严格的情况下,RealFormer表现是否也会更佳,因此作者进行了相关对比实验,结果如下图所示。
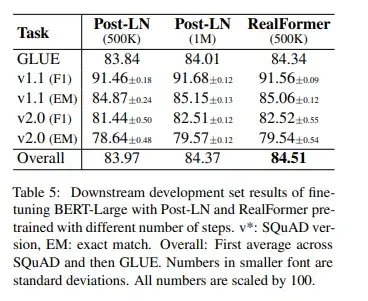
结果表明,在训练步数被限制为500K时,RealFormer在GLUE下游任务上的甚至优于训练1M的Post-LN模型,而SQuAD下游任务上的表现也相差不多。
2)使用更大的学习率,RealFormer表现如何?
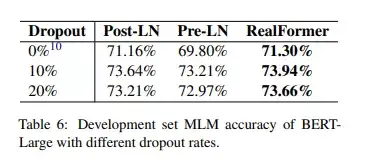
之前的一些论文表明Pre-LN相较Post-LN,更能从增加学习率中受益。受此启发,作者沿用之前预训练的步骤训练BERT-Large,只是将学习率增加到2e-4,并用3种模型结构进行实验。模型在MLM预训练任务上的准确率如下图所示:

可以看出:一方面,使用更大的学习率,Pre-LN和RealFormer表现都略有提升;另一方面,比起Pre-LN从73.21%提升到73.64%,RealFormer从73.94%提升到74.31%,提升获益更为明显。
3)如何量化RealFormer和基线Transformers的不同?
4)为正则化大模型,dropout是否会比RealFormer中的残差式注意力更为有效?
04 实验结果
RealFormer模型在预训练任务和GLUE和SQuAD两个下游任务上的表现都超越了Post-LN和Pre-LN两种模型结构。另外,在下游任务的表现上,RealFormer超越了训练轮数2倍预训练基线模型。通过量化分析,RealFormer无论是相比邻的层之间的attention还是不同头的attention,都更为稀疏。此外,RealFormer相对能从超参调整中更大程度提升模型效果。
参考文献
私信我领取目标检测与R-CNN/数据分析的应用/电商数据分析/数据分析在医疗领域的应用/NLP学员项目展示/中文NLP的介绍与实际应用/NLP系列直播课/NLP前沿模型训练营等干货学习资源。









