Flink 基础
Flink特性
流式计算是大数据计算的痛点,第1代实时计算引擎Storm对Exactly Once 语义和窗口支持较弱,使用的场景有限且无法支持高吞吐计算;Spark Streaming 采用“微批处理”模拟流计算,在窗口设置很小的场景中有性能瓶颈,Spark 本身也在尝试连续执行模式(Continuous Processing),但进展缓慢。
Flink是一个低延迟、高吞吐的实时计算引擎,其利用分布式一致性快照实现检查点容错机制,并实现了更好的状态管理,Flink可在毫秒级的延迟下处理上亿次/秒的消息或者事件,同时提供了一个Exactly-once的一致性语义,保证了数据的正确性,使得Flink可以提供金融级的数据处理能力,总结其高级特性包括CSTW(CheckPoint,Statue,Time,windows)
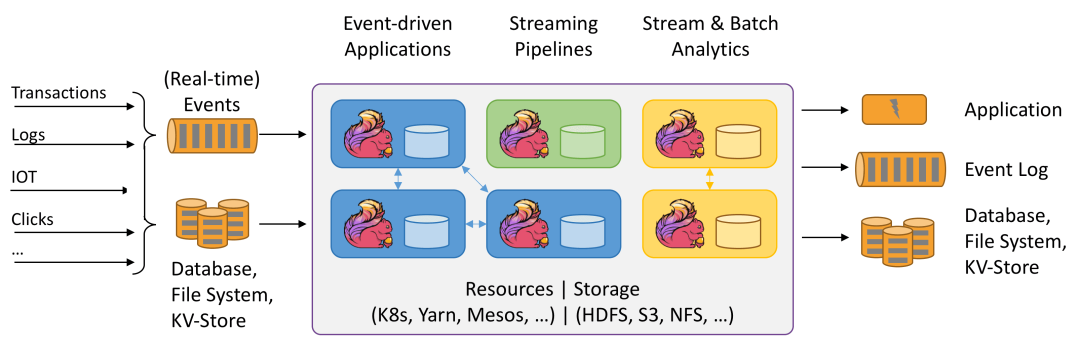
Flink和Spark对比
设计思路
Spark的技术理念是基于批来模拟流,微批处理的延时较高(无法优化到秒以下的数量级),且无法支持基于event_time的时间窗口做聚合逻辑。Flink和spark相反,它基于流计算来模拟批计算,更切合数据的生成方式,技术上有更好的扩展性。
状态管理
流处理任务要对数据进行统计,如Sum, Count, Min, Max,这些值是需要存储的,因为要不断更新,这些值或者变量就可以理解为一种状态,如果数据源是在读取Kafka, RocketMQ,可能要记录读取到什么位置,并记录Offset,这些Offset变量都是要计算的状态。
Flink提供了内置的状态管理,可以把这些状态存储在Flink内部,而不需要把它存储在外部系统,这样做的好处:
① 降低了计算引擎对外部系统的依赖以及部署,使运维更加简单;
② 对性能带来了极大的提升:如果通过外部去访问如Redis , HBase 需要网络及RPC资源,如果通过Flink内部去访问,只通过自身的进程去访问这些变量。
同时Flink会定期将这些状态做Checkpoint持久化,把Checkpoint存储到一个分布式的持久化系统中,比如HDFS,这样当Flink的任务出现任何故障时,它都会从最近的一次Checkpoint将整个流的状态进行恢复,然后继续运行它的流处理,对用户没有任何数据上的影响。
Flink 初探
设计架构
Flink是一个分层的架构系统,每一层所包含的组件都提供了特定的抽象,用来服务于上层组件,Flink的分层体现有四层,分别是Deploy层、core层、API层/Libraries层,其中Deploy层主要涉及的是Flink的部署模式及同资源调度组件的交互模式,Core层提供了支持Flink计算的全部核心实现,API层/Libraries层提供了Flink的API接口和基于API接口的特定应用的计算框架;
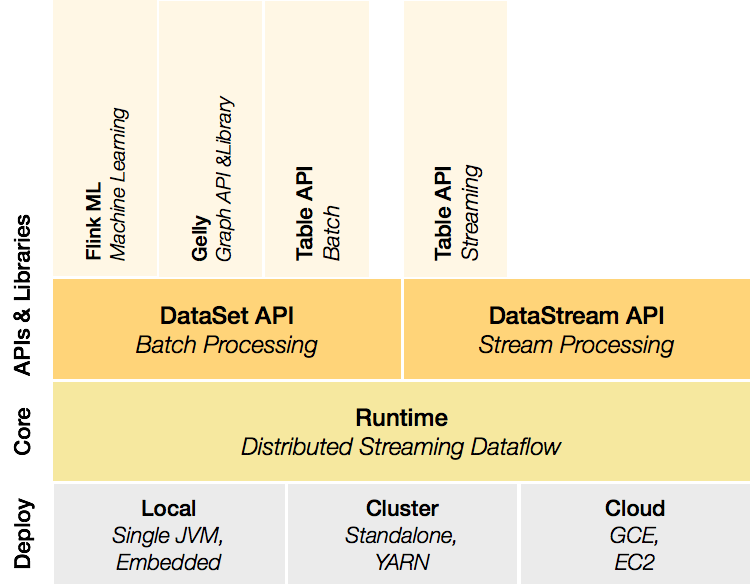
Deploy层:该层主要涉及了Flink的部署模式,Flink支持多种部署模式:本地、集群(Standalone/YARN)、云(GCE/EC2),Standalone 部署模式与Spark类似;
Runtime层:Runtime层提供了支持Flink计算的全部核心实现,比如:支持分布式Stream处理、Job Graph到Execution Graph的映射、调度 等,为上层API层提供基础服务。
API层:API层主要实现了面向无界Stream的流处理和面向Batch的批处理API,其中面向流处理对应DataStream API,面向批处理对应DataSet API。
Libraries层:该层也可以称为Flink应用框架层,根据API层的划分,在API层之上构建的满足特定应用的实时计算框架,也分别对应于面向流处理 和面向批处理两类。面向流处理支持:CEP(复杂事件处理)、SQL-like的操作(基于Table的关系操作);面向批处理支持:FlinkML(机器学习库)、Gelly(图处理)。
Flink on yarn
Flink支持增量迭代,具有对迭代自行优化的功能,因此在on yarn上提交的任务性能略好于 Spark,Flink提供2种方式在yarn上提交任务:启动1个一直运行的 Yarn session(分离模式)和在 Yarn 上运行1个 Flink 任务(客户端模式);
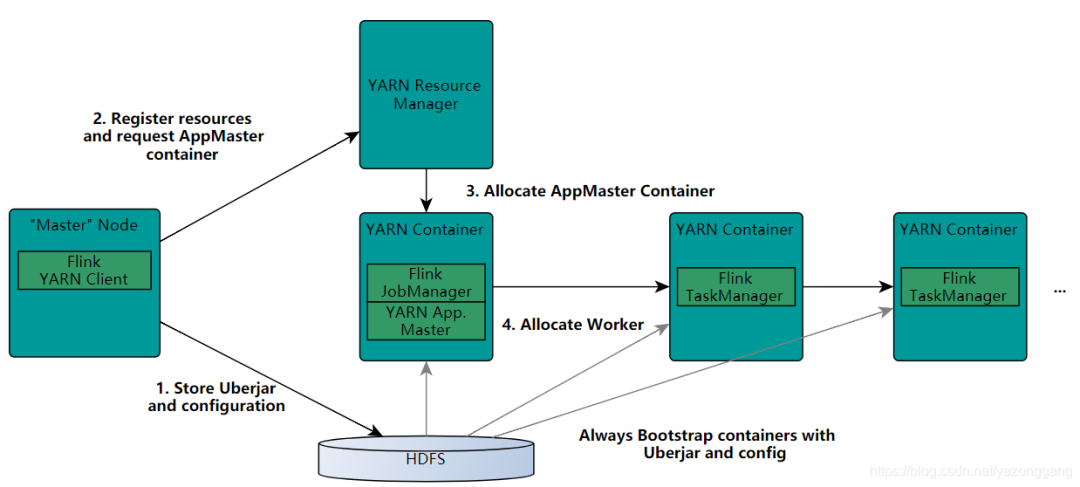
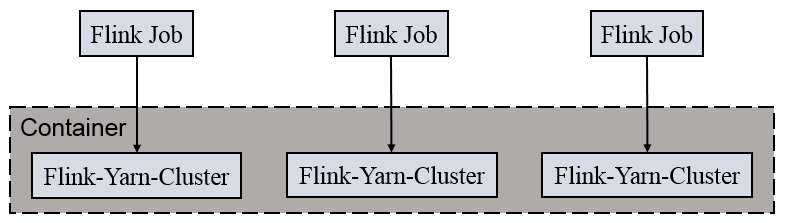
分离模式:通过命令yarn-session.sh的启动方式本质上是在yarn集群上启动一个flink集群,由yarn预先给flink集群分配若干个container,在yarn的界面上只能看到一个Flink session with X TaskManagers的任务,并且只有一个Flink界面,可以从Yarn的Application Master链接进入;
客户端模式:通过命令bin/flink run -m yarn-cluster启动,每次发布1个任务,本质上给每个Flink任务启动了1个集群,yarn在任务发布时启动JobManager(对应Yarn的AM)和TaskManager,如果一个任务指定了n个TaksManager(-yn n),则会启动n+1个Container,其中一个是JobManager,发布m个应用,则有m个Flink界面,不同的任务不可能在一个Container(JVM)中,实现了资源隔离。
进入Flink的bin目录下运行./yarn-session.sh –help 查看帮助验证yarn是否成功配置,使用./yarn-session.sh –q 显示yarn所有nodeManager节点资源;部署On yarn模式的Flink只需要修改配置conf/flink-conf.yaml ,详细参数请参考官网:通用配置:Configuration,HA配置:High Availability (HA)
采用分离模式来启动Flink Yarn Session,提交后提示该yarn application成功提交到yarn并返回id,使用yarn application –kill application_id 来停止yarn上提交的任务;
yarn-session.sh -n 3 -jm 700 -tm 700 -s 8 -nm FlinkOnYarnSession -d –st
可以直接提交自带的词频统计用例,验证on yarn模式是否配置成功:
~/bin/flink run -m yarn-cluster -yn 4 -yjm 2048 -ytm 2048 ~/flink/examples/batch/WordCount.jar流程分析
分离模式:通过命令yarn-session.sh先启动集群,然后再提交作业,接着会向yarn申请一块空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到yarn中的其中一个作业执行完成后,释放了资源,下个作业才会正常提交。所有作业共享Dispatcher和ResourceManager;共享资源;适合规模小执行时间短的作业。
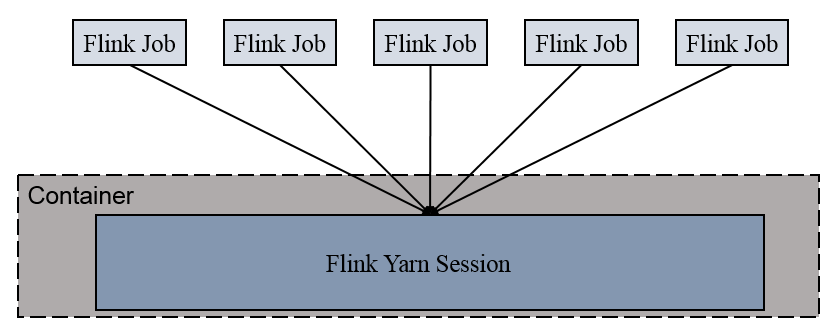
客户端模式:通过命令bin/flink run -m yarn-cluster提交任务,每提交一个作业会根据自身的情况,都会单独向yarn申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行,适合规模大长时间运行的作业;
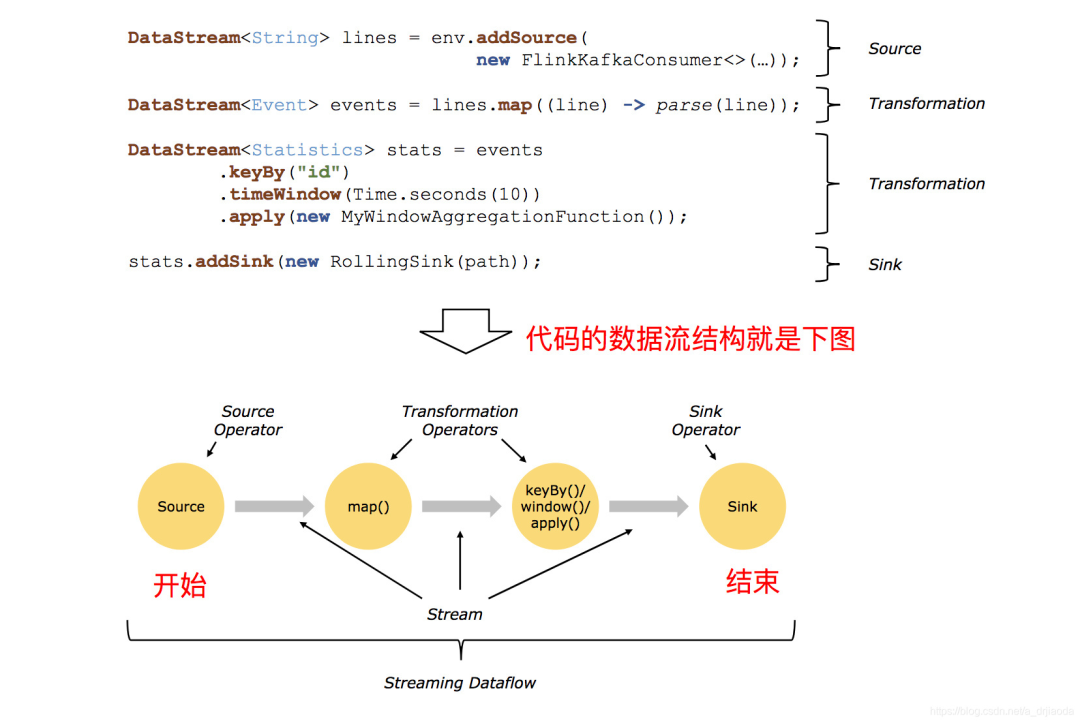
DataStream
DataStream是Flink的较低级API,用于进行数据的实时处理任务,可以将该编程模型分为DataSource、Transformation、Sink三个部分;
DataSource
源是程序读取输入数据的位置,可以使用 StreamExecutionEnvironment.addSource(sourceFunction) 将源添加到程序,Flink 有许多预先实现的源函数,也可以通过实现 SourceFunction 方法自定义非并行源 ,或通过实现 ParallelSourceFunction 或扩展 RichParallelSourceFunction 自定义并行源。
有几个预定义的流数据源可从 StreamExecutionEnvironment 访问:
基于文件:
readTextFile(path) #逐行读取文本文件(文件符合 TextInputFormat 格式),并作为字符串返回每一行。
readFile(fileInputFormat, path) #按指定的文件输入格式(fileInputFormat)读取指定路径的文件。
readFile(fileInputFormat, path, watchType, interval, pathFilter) #前两个方法的内部调用方法。根据给定文件格式(fileInputFormat)读取指定路径的文件。根据 watchType,定期监听路径下的新数据(FileProcessingMode.PROCESS_CONTINUOUSLY),或者处理当前在路径中的数据并退出(FileProcessingMode.PROCESS_ONCE),使用 pathFilter,可以进一步排除正在处理的文件。基于Socket:socketTextStream 从 Socket 读取,元素可以用分隔符分隔。
基于集合:
fromCollection(Seq) #用 Java.util.Collection 对象创建数据流,集合中的所有元素必须属于同一类型;
fromCollection(Iterator) #用迭代器创建数据流。指定迭代器返回的元素的数据类型;
fromElements(elements: _*) #从给定的对象序列创建数据流。所有对象必须属于同一类型;
fromParallelCollection(SplittableIterator) #并行地从迭代器创建数据流。指定迭代器返回的元素的数据类型;
generateSequence(from, to) #并行生成给定间隔的数字序列。自定义:addSource 附加新的源函数。例如从 Apache Kafka 中读取,可以使用 addSource(new FlinkKafkaConsumer08<>(...))。请详细查看 连接器。
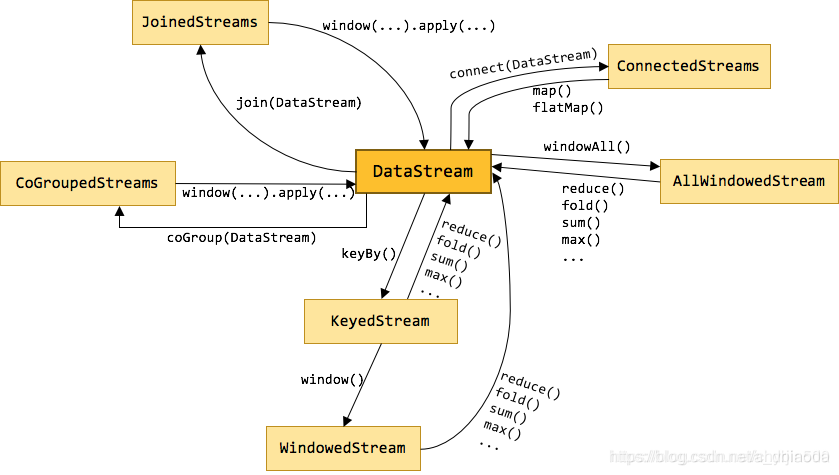
Transformation
Transformation操作将1个或多个DataStream转换为新的DataStream,多个转换组合成复杂的数据流拓扑,如下图所示,DataStream会由不同的Transformation操作、转换、过滤、聚合成其他不同的流,从而完成业务要求;
Map:DataStream -> DataStream,一个数据元生成一个新的数据元。将输入流的元素翻倍:dataStream.map { x => x * 2 }
FlatMap:DataStream -> DataStream,一个数据元生成多个数据元(可以为0)。将句子分割为单词:
dataStream.flatMap { str => str.split(" ") }Filter:DataStream -> DataStream,每个数据元执行布尔函数,只保存函数返回 true 的数据元。过滤掉零值的过滤器:
dataStream.filter { _ != 0 }KeyBy :DataStream -> KeyedStream,将流划分为不相交的分区。具有相同 Keys 的所有记录在同一分区。指定 key 的取值:
dataStream.keyBy("someKey") // Key by field "someKey"
dataStream.keyBy(0) // Key by the first element of a TupleReduce :KeyedStream -> DataStream,KeyedStream 元素滚动执行 Reduce。将当前数据元与最新的一个 Reduce 值组合作为新值发送。创建 key 的值求和:keyedStream.reduce { _ + _ }
Aggregations :KeyedStream -> DataStream,应用于 KeyedStream 上的滚动聚合。
Window:KeyedStream -> WindowedStream,Windows 可以在已经分区的 KeyedStream 上定义。Windows 根据某些特征(例如,在最近5秒内到达的数据)对每个Keys中的数据进行分组。更多说明参考 Windows 或 译版。
dataStream.keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(5)))WindowAll :DataStream -> AllWindowedStream,Windows 也可以在 DataStream 上定义。在许多情况下,这是非并行转换。所有记录将收集在 windowAll 算子的一个任务中。
dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)))Window Apply :WindowedStream -> DataStream 或 AllWindowedStream -> DataStream,将函数应用于整个窗口。一个对窗口数据求和:
windowedStream.apply { WindowFunction }
allWindowedStream.apply { AllWindowFunction }Window Reduce:WindowedStream -> DataStream,Reduce 函数应用于窗口并返回结果值。windowedStream.reduce { _ + _ }
Aggregations on windows:WindowedStream -> DataStream,聚合窗口内容;
Union :DataStream* -> DataStream,两个或多个数据流的合并,创建包含来自所有流的所有数据元的新流。如果将数据流与自身联合,则会在结果流中获取两次数据元。
dataStream.union(otherStream1, otherStream2, ...)Window Join :DataStream,DataStream -> DataStream,Join 连接两个流,指定 Key 和窗口。
dataStream.join(otherStream)
.where(<key selector>).equalTo(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply { ... }Window CoGroup :DataStream,DataStream -> DataStream,CoGroup 连接两个流,指定 Key 和窗口。
dataStream.coGroup(otherStream)
.where(0).equalTo(1)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply {}CoGroup 与 Join 的区别:CoGroup 会输出未匹配的数据,Join 只输出匹配的数据
Connect :DataStream,DataStream -> ConnectedStreams,连接两个有各自类型的数据流。允许两个流之间的状态共享。
someStream : DataStream[Int] = ...
otherStream : DataStream[String] = ...
val connectedStreams = someStream.connect(otherStream)可用于数据流关联配置流;
CoMap, CoFlatMap :ConnectedStreams -> DataStream,作用域连接数据流(connected data stream)上的 map 和 flatMap:
Split :DataStream -> SplitStream,将数据流拆分为两个或更多个流。
Select :SplitStream -> DataStream,从 SpliteStream 中选择一个流或多个流。
val even = split select "even"
val odd = split select "odd"
val all = split.select("even","odd")Iterate :DataStream -> IterativeStream -> DataStream,将一个算子的输出重定向到某个先前的算子,在流中创建 feedback 循环。这对于定义不断更新模型的算法特别有用。以下代码以流开头并连续应用迭代体。大于0的数据元将被发送回 feedback,其余数据元将向下游转发。
Project:DataStream -> DataStream,作用于元组的转换,从元组中选择字段的子集。
DataStream<Tuple3<Integer, Double, String>> in = // [...]
DataStream<Tuple2<String, Integer>> out = in.project(2,0);Sink
Data Sink 消费 DataStream 并转发到文件,套接字,外部系统或打印到页面。Flink 带有各种内置输出格式,封装在 DataStreams 上的算子操作后面:
writeAsText() / TextOutputFormat:按字符串顺序写入文件。通过调用每个元素的 toString() 方法获得字符串。
writeAsCsv(...) / CsvOutputFormat:将元组写为逗号分隔的形式写入文件。行和字段分隔符是可配置的。每个字段的值来自对象的 toString() 方法。
print() / printToErr():在标准输出/标准错误流上打印每个元素的 toString() 值。可以定义输出前缀,这有助于区分不同的打印调用。如果并行度大于1,输出也包含生成输出的任务的标识符。
writeUsingOutputFormat() / FileOutputFormat:自定义文件输出的方法和基类。支持自定义对象到字节的转换。
writeToSocket:将元素写入 Socket,使用 SerializationSchema 进行序列化。
addSink:调用自定义接收器函数。请详细查看 连接器。
DataStream 的 write*() 方法主要用于调试目的。他们没有参与 Flink checkpoint,这意味着这些函数通常具有至少一次的语义。刷新到目标系统的数据取决于 OutputFormat 的实现,并非所有发送到 OutputFormat 的数据都会立即显示在目标系统中。此外,在失败的情况下,这些记录可能会丢失。
要将流可靠、准确地传送到文件系统,请使用 flink-connector-filesystem。通过 .addSink(...) 方法的自定义实现,可以实现在 checkpoint 中精确一次的语义。
Time
流式数据处理最大的特点是数据具有时间属性特征,Flink根据时间产生的位置不同,将时间区分为三种概念:数据生成时间(Event_time)、事件接入时间(Ingestion_time)、事件处理时间(Processing_time),用户可以根据需要选择事件类型作为流式数据的时间属性,极大增强了数据处理的灵活性和准确性;
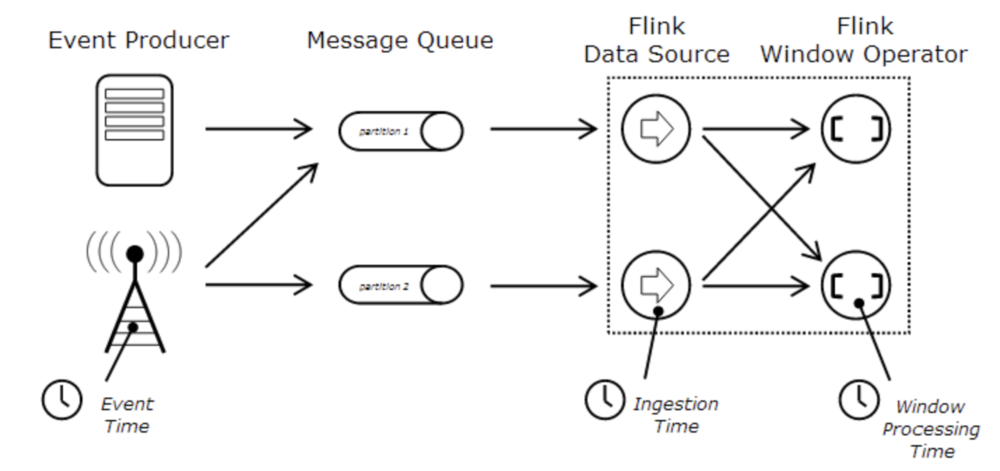
Event_time:独立事件在产生它的设备上的发生时间,这个时间通常在到达Flink之前已经嵌入到生产数据中,因此时间顺序取决于事件产生的地方,和下游的数据处理系统的事件无关,需要在Flink中指定事件的时间属性或者设定时间提取器提取事件时间;
Processing_time:指在操作算子计算过程中获取到的所在主机的时间,用户选择了Processing_time后,所有和时间相关的计算算子都直接使用其所在主机的系统时间,使用Processing_time的程序性能相对较高,延时相对较低,因为其所有操作不需要做任何时间上的对比和协调;
Ingestion_time:指数据接入Flink系统的时间,依赖于Source Operator所在主机的系统时钟;
一般场景中选择event_time作为事件时间戳是最贴近生产的,但大多数情况下由于数据的延迟和乱序使用processing_time;
Window窗口
Windows定义和分类
在流式计算中,数据持续不断的流入计算引擎,需要一个窗口限定计算范围,比如监控场景的近2分钟或者精准计算的每隔2分钟计算一次,窗口定义了该范围,辅助完成有界范围的数据处理;
Flink的DataStream API将窗口抽象成独立的Operator,且支持很多窗口算子,每个窗口算子包含Window Assigner 、Windows Function、触发器、剔除器、时延设定等部分属性,其中Window Assigner 和 Windows Function是必须要指定的属性;
Window Assigner用来决定某个元素被分配到哪个/哪些窗口中去;Trigger触发器决定了一个窗口何时能够被计算或清除,每个窗口都会拥有一个自己的Trigger;
Evictor驱逐者在Trigger触发之后,在窗口被处理之前,Evictor(如果有Evictor的话)会用来剔除窗口中不需要的元素,相当于一个filter。
Flink支持多种窗口类型,按照驱动类型分为:时间驱动的Time Window(如每30秒钟)和数据驱动的Count Window(如每100个事件),按照窗口的滚动方式又可以分成:翻滚窗口(Tumbling Window,无重叠),滚动窗口(Sliding Window,有重叠)和会话窗口(Session Window,活动间隙),下图可以看出分类区别:
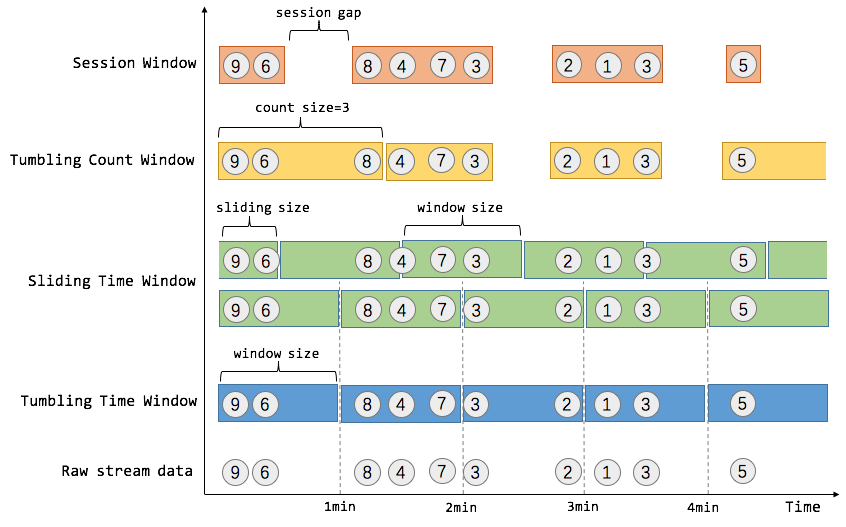 Time Window 是根据时间对数据流进行分组的,且窗口机制和时间类型是完全解耦的,也就是说当需要改变时间类型时(三种时间)不需要更改窗口逻辑相关的代码,Time Window 中常见的即为Tumbling Time Window和Sliding Time Window;
Time Window 是根据时间对数据流进行分组的,且窗口机制和时间类型是完全解耦的,也就是说当需要改变时间类型时(三种时间)不需要更改窗口逻辑相关的代码,Time Window 中常见的即为Tumbling Time Window和Sliding Time Window;
Count Window 是根据元素个数对数据流进行分组的,也包括Tumbling Count Window和Sliding Count Window;
Windows实现
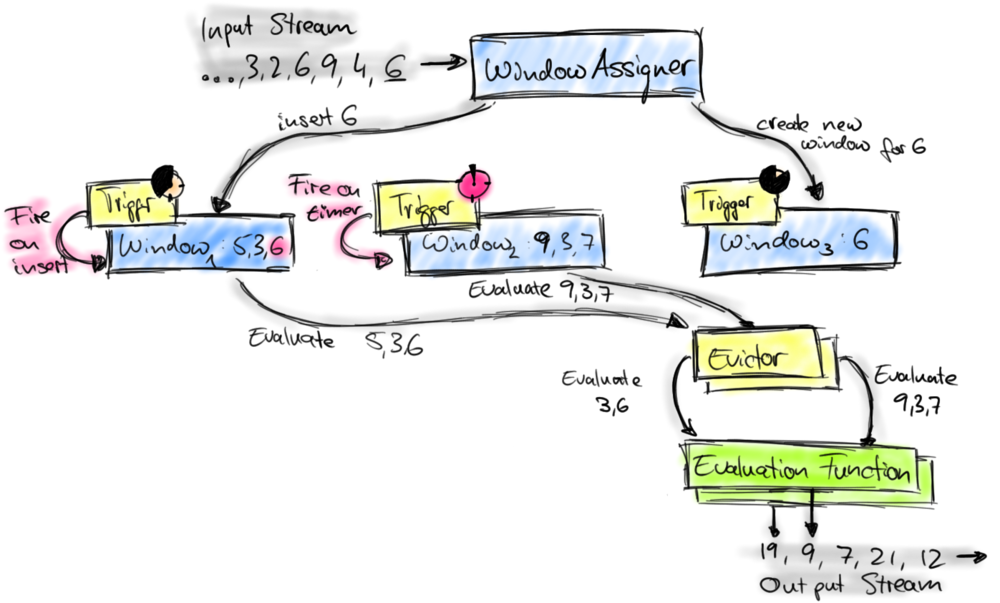
上图中的组件都位于一个算子(window operator)中,数据流源源不断地进入算子,每一个到达的元素都会被交给 WindowAssigner,WindowAssigner 会决定元素被放到哪个或哪些窗口(window),Window本身是一个ID标识符,其内部可能存储了一些元数据,如TimeWindow中有开始和结束时间,但是并不会存储窗口中的元素。窗口中的元素实际存储在 Key/Value State 中,key为Window,value为元素集合(或聚合值)。为了保证窗口的容错性,该实现依赖了 Flink 的 State 机制。
每一个窗口都拥有一个属于自己的 Trigger,Trigger上会有定时器,用来决定一个窗口何时能够被计算或清除,每当有元素加入到该窗口,或者之前注册的定时器超时了,那么Trigger都会被调用。Trigger的返回结果可以是 continue(不做任何操作),fire(处理窗口数据),purge(移除窗口和窗口中的数据),或者 fire + purge。一个Trigger的调用结果只是fire的话,那么会计算窗口并保留窗口原样,也就是说窗口中的数据仍然保留不变,等待下次Trigger fire的时候再次执行计算。一个窗口可以被重复计算多次知道它被 purge 了。在purge之前,窗口会一直占用着内存。
当Trigger fire了,窗口中的元素集合就会交给Evictor(如果指定了的话)。Evictor 主要用来遍历窗口中的元素列表,并决定最先进入窗口的多少个元素需要被移除。剩余的元素会交给用户指定的函数进行窗口的计算。如果没有 Evictor 的话,窗口中的所有元素会一起交给函数进行计算。
计算函数收到了窗口的元素(可能经过了 Evictor 的过滤),并计算出窗口的结果值,并发送给下游。窗口的结果值可以是一个也可以是多个。DataStream API 上可以接收不同类型的计算函数,包括预定义的sum(),min(),max(),还有 ReduceFunction,FoldFunction,还有WindowFunction。WindowFunction 是最通用的计算函数,其他的预定义的函数基本都是基于该函数实现的。
Flink 对于一些聚合类的窗口计算(如sum,min)做了优化,因为聚合类的计算不需要将窗口中的所有数据都保存下来,只需要保存一个result值就可以了。每个进入窗口的元素都会执行一次聚合函数并修改result值。这样可以大大降低内存的消耗并提升性能。但是如果用户定义了 Evictor,则不会启用对聚合窗口的优化,因为 Evictor 需要遍历窗口中的所有元素,必须要将窗口中所有元素都存下来。
Windows Function
在运用窗口计算时,Flink根据上有数据集是否是KeyedStream类型(数据是否按照Key分区),如果上游数据未分组则调用window()方法指定Windows Assigner,数据会根据Key在不同Task实例中并行计算,最后得出针对每个Key的统计结果,如果是Non-Keyed类型则调用WindowsAll()方法指定Windows Assigner,所有的数据都会在窗口算子中路由得到一个Task中计算,并得到全局统计结果;
定义完窗口分配器后,需要为每一个窗口指定计算逻辑,也就是Windows Function,Flink提供了四种类型Window Function,分别是ReduceFunction、AggreateFunction、FoldFunction、ProcessWindowFunction,其中FoldFunction将逐渐不再使用;四种类型有分为增量聚合操作(ReduceFunction、AggreateFunction、FoldFunction)和全量聚合操作(ProcessWindowFunction);
增量聚合函数计算性能高,占用存储空间少,因为其只需要维护窗口的中间结果状态值,不需要缓存原始数据;全量聚合函数使用代价相对高,性能较弱,因为算子需要缓存该窗口的接入数据,然后等窗口触发后对所有原始数据进行汇总计算,若接入数据量大或窗口时间长容易导致计算性能下降;
ReduceFunction和AggreateFunction相似,但前者的输出类型和输入类型一致(如使用tuple的某个字段聚合),后者更加灵活地提供3个复写方法,add()定义数据的添加逻辑,getResult()定义根据Accumulator计算结果的逻辑,merge()方法定义合并accumulator的逻辑;
ProcessWindowFunction可以支撑更复杂的算子,其支持基于窗口全部数据元素的结果计算,当算子需要窗口的元数据或状态数据,或者算子不支持运算交换律和结合律(统计所有元素的中位数和众数),需要该函数中的Context对象,Context类定义了Window的元数据及可以操作的Window的状态数据包括GlobalState和WindowState;
大部分情况下,需要增量计算和全量计算结合,因为增量计算虽然一定程度能够提升窗口性能,但灵活性不及ProcessWindowFunction,两者整合使用,既可以得到增量算子又可以得到窗口的元数据(窗口开始、终止时间等),比如在计算TOP N的场景中,分窗口计算完数据的计算后需要根据商品ID汇聚总的点击数;
Watermark
由于网络或系统等外部因素影响,事件数据不能及时传输到Flink系统中,导致数据乱序、延迟等问题,因此需要一种机制能够控制数据处理的过程和进度;基于event_time时间的Windows创建后,具体如何确定属于该Windows中的数据元素已经全部到达,如果确定全部到达就可以对所有数据进行窗口计算操作(汇总、分组),如果数据没有全部到达,则继续等待该窗口中的数据,但是又不能无限期的等下去,需要有机制来保证一个特定的时间后,必须触发window去进行计算了,此时watermark发挥作用了,它表示当达到watermark后,在watermark之前的数据已经全部达到(即使后面还有延迟的数据);Watermark是处理EventTime 窗口计算提出的机制,本质上是一种时间戳,可以在读取 Source时候指定或者在transformation操作之前,用自定义的Watermark生成器按照需求指定;
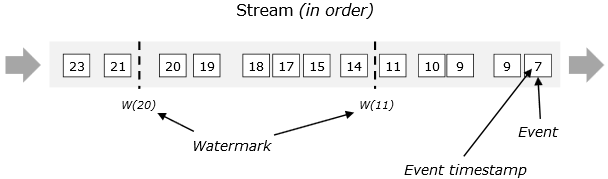
正常情况下,流式数据的到达时间是有序的,如下图:
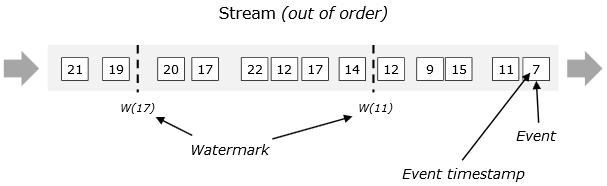
 一般情况存在数据的乱序(out-of-order)和延迟(late element),此时水位线机制能表明该时间戳之前到当前水位线时间戳的数据已经全部达到,没有比它(水位线)更早的数据了,并触发计算;
一般情况存在数据的乱序(out-of-order)和延迟(late element),此时水位线机制能表明该时间戳之前到当前水位线时间戳的数据已经全部达到,没有比它(水位线)更早的数据了,并触发计算;
Flink中生成水位线的方式有两种:Periodic Watermarks(周期性)和Punctuated Watermarks,前者假设当前时间戳减去固定时间,所有数据都能达到,后者要在特定事件指示后触发生成水位线;
举例说明Periodic Watermarks 工作方式:当前window为10s,设想理想情况下消息都没有延迟,那么eventTime等于系统当前时间,假如设置watermark等于eventTime的时候,当watermark = 00:00:10的时候,就会触发w1的计算,这个时后因为消息都没有延迟,watermark之前的消息(00:00:00~00:00:10)都已经落入到window中,所以会计算window中全量的数据。那么假如有一条消息eventTime是00:00:01 应该属于w1,在00:00:11才到达,因为假设消息没有延迟,那么watermark等于当前时间,00:00:11,这个时候w1已经计算完毕,那么这条消息就会被丢弃,没有加入计算,这样就会出现问题。这是已经可以理解,代码中为什么要减去一个常量作为watermark,假设每次提取eventTime的时减去2s,那么当data1在00:00:11到达的时候,watermark是00:00:09这个时候,w1还没有触发计算,那么data1会被加入w1,这个时候计算完全没有问题,所以减去一个常量是为了对延时的消息进行容错;
Punctuated Watermarks提供自定义条件生成水位,例如判断某个数据元素的当前状态或tuple类型的某个值,如果接入事件中状态为0则触发生成watermark,如果状态不为0则不触发,需要分别复写extractTimestamp和checkAndGetNextWatermark方法;
Flink允许提前预定义数据的提取器Timestamp Extractors,在读取source时候定义提取时间戳;
延迟数据
基于Event_time的窗口计算虽然可以使用warterMark机制容忍部分延迟,但只能一定程度的缓解该问题,无法应对某些延迟特别严重的场景。Flink默认丢失延迟数据,但用户可以自定义延迟数据的处理方式,此时需要Allowed Lateness机制近数据的额外处理;
DataStream API提供Allowed Lateness方法指定是否对迟到数据进行处理,参数是Time类型的时间间隔大小,代表允许的最大延迟时间,Flink的窗口计算中会将Window的Endtime加上该时间作为窗口最后释放的结束时间(P),当接入的数据中Event time未超过该时间(P),但WaterMark已经超过Window的Event_Time时直接触发窗口计算,若Event_Time超过了时间P,则做丢弃处理;
通常情况下可以使用sideOutputLateData 方法对迟到数据进行标记,然后使用getSideOutput()方法得到被标记的延迟数据,分析延迟原因;
多流合并/关联
合并
Connect:Flink 提供connect方法实现两个流或多个流的合并,合并后生成ConnectedStreams,会对两个流的数据应用不同的处理方法,并且双流之间可以共享状态(比如计数);ConnectedStream提供的map()和flatMap()需要定义CoMapFunction和CoFlatMapFunction分别处理输入的DataStream数据集;
Union:Union算子主要实现两个或者多个输入流合并成一个数据集,需要保证两个流的格式一致,输出的流与输入完全一致;
关联
Flink支持窗口的多流关联,即在一个窗口上按照相同条件对多个输入流进行join操作,需要保证输入的Stream构建在相同的Windows上,且有相同类型的Key做为关联条件;
数据集inputStream1通过join方法形成JoinedStreams类型数据集,调用where()方法指定inputStream1数据集的key,调用equalTo()方法指定inputStream2对应关联的key,通过window()方法指定Window Assigner,最后通过apply()方法中传入用户自定义的JoinFunction或者FlatJoinFunction对输入数据元素进行窗口计算;
Windows Join过程中所有的Join操作都是Inner Join类型,也就是必须满足相同窗口中,每个Stream都有Key,且key相同才能完成关联操作并输出结果;
状态和容错
有状态计算是Flink重要特性,其内部存储计算产生的中间结果并提供给后续的Function或算子使用,状态数据维系在本地存储中,可以是Flink的堆内存或者堆外内存中,也可以借助于第三方的存储介质,同storm+ redis / hbase模式相比,Flink完善的状态管理减少了对外部系统的依赖,减少维护成本;
State和类型
Flink根据数据集是否根据key分区将状态分为Keyed State和 Operator State两种类型,Keyed State只能用于KeyedStream类型数据集对应的Function和Operation上,它是Operator State的特例;
Operator State只和并行的算子实例绑定,和数据元素中的key无关,支持当算子实例并行度发生变化后自动重新分配状态数据;
Keyed State和 Operator State均有两种形式,一种是托管状态,一种是原始状态,前者有Flink Runtime控制和管理状态数据并将状态数据转换成内存Hash tables 或RocksDB的对象存储,后者由算子自己管理数据结构,当触发CheckPoint后,Flink并不知道状态数据内部的数据结构,只是将数据转换成bytes数据存储在CheckPoint中,当从Checkpoint恢复任务时,算子自己反序列化出状态的数据结构;
CheckPoint 和SavePoint
Flink基于轻量级分布式快照算法提供了CheckPoint机制,分布式快照可以将同一时间点的Task/Operator状态数据全局统一快照处理,包括Keyed State和Operator State
Savepoints是检查点的一种特殊实现,底层使用CheckPoint机制,Savepoint是用户以手工命令方式触发CheckPoint,并将结果持久化到指定的存储路径中,其主要目的是帮助用户在升级和维护集群过程中保存系统的状态数据,避免因停机运维或者升级到知道正常终止的应用数据状态无法恢复。
参考内容:
https://www.jianshu.com/p/9e92cefa9d4e
http://wuchong.me/blog/2018/11/18/flink-tips-watermarks-in-apache-flink-made-easy/

福利时刻
01. 后台回复「数据」,即可领取大数据经典资料。
02. 后台回复「转型」,即可传统数据仓库转型大数据必学资料。

!关注不迷路~ 各种福利、资源定期分享!








