Contents
Introduction
- 视频中的人体动作识别是一个具有挑战性的工作。与传统的图像分类相比,视频的时序部分为识别提供了额外信息,此外,视频还为单张视频帧提供了天然的数据增强。作者提出了双流网络用于视频动作识别,在 UCF-101 和 HMDB-51 数据集上达到了 SOTA
Two-stream architecture for video recognition
前置知识:光流
- 光流被用于描述视频中物体的运动特征。通过提取光流,我们可以将背景中不必要的噪声 (视频中静止的部分) 全部忽略,只提取动作特征
- 如下图所示,(a) (b) 为视频中的两张连续帧;(
c
c
c) 就显示了视频中拿箭右手 (蓝色矩形框) 的光流图,记录了图中每个像素点的运动方向 (这就是为什么文中一直在说 “dense” optical flow,因为每个像素点都会记录其运动信息),可以用
d
t
(
u
,
v
)
d_t(u,v)
dt(u,v) 表示第
t
t
t 帧时点
(
u
,
v
)
(u,v)
(u,v) 处的位移向量;而在实际表示中,一张光流图会被拆成两张图,分别表示水平分量
d
x
d^x
dx 和竖直分量
d
y
d^y
dy,如 (d) (e) 所示,这两张图可以看作一张光流图的两个通道。因此,每两张视频帧可以生成一张两通道的光流图 (水平分量和竖直分量)

双流网络
- 视频动作识别的难点就是综合利用静态帧的外观特征 (spatial info) 和帧之间的时序动作特征 (temporal info)。之前的利用神经网络进行视频动作识别的工作直接将连续的视频帧输入网络以期待网络同时学得这两种特征,但效果并不好。后续工作甚至发现将单个视频帧作为网络输入和输入连续帧作为网络输入的模型最终性能相似,这表明模型并不能很好地抽取出帧之间的时序动作特征
- 为此,作者提出了双流网络,通过 Spatial stream ConvNet 和 Temporal stream ConvNets 分别抽取视频的空间和时序特征,最后通过 late fusion 对两个网络进行融合,这里作者考虑了两种融合方法:(1) 直接对两个网络的 softmax 得分进行平均;(2) 将 stacked
L
2
L_2
L2-normalised softmax scores 作为特征训练一个多分类线性 SVM
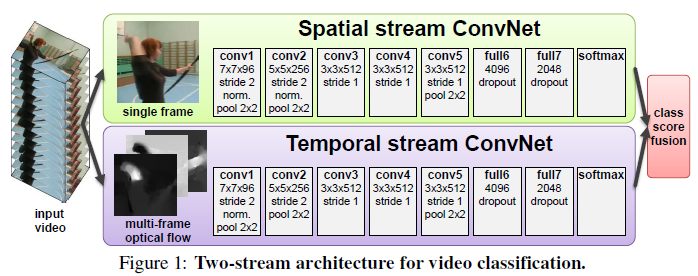
- Spatial stream ConvNet: 输入为单张视频帧 (因为数据集中的视频时长比较短,训练和测试时都是随机抽一张视频帧作为输入),负责提取静态帧的外观特征。同时,由于空间流网络只负责提取静态特征,与图像分类网络其实一样,因此我们完全可以在 ImageNet 上对其进行预训练,这个 trick 也可以提升最后的模型性能
- Temporal stream ConvNets / Optical flow ConvNets: 输入为多张光流帧,光流的加入弥补了神经网络难以捕捉时序运动信息的缺陷,直接提供给了模型帧之间的运动信息,使得识别任务更加容易
Multi-frame optical flow (作者实验了两种输入光流帧的方式)
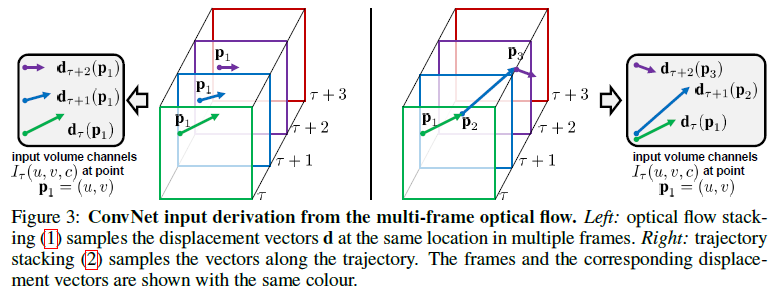
- Optical flow stacking: 对某一帧
τ
\tau
τ,采集它之后的
L
L
L 帧图像,由这
L
+
1
L+1
L+1 张视频帧可以生成
L
L
L 张光流帧,总共有
2
L
2L
2L 个输入通道,将这
L
L
L 张光流帧堆叠到一起就形成了最终的输入
I
τ
∈
R
w
×
h
×
2
L
I_\tau\in\R^{w\times h\times 2L}
Iτ∈Rw×h×2L,该输入表示了视频中每个像素点在
L
L
L 帧时间里的运动情况。其中
τ
\tau
τ 的选取也是采用随机选取的方式
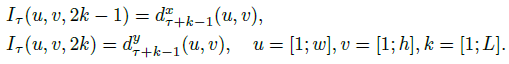
- Trajectory stacking: 这种方法用沿着运动轨迹采样得到的光流信息去替代在多个帧的相同位置采样得到的光流信息
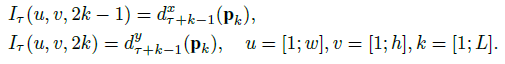 其中
p
k
p_k
pk 就是运动轨迹上的第
k
k
k 个点,通过下式进行计算:
其中
p
k
p_k
pk 就是运动轨迹上的第
k
k
k 个点,通过下式进行计算:
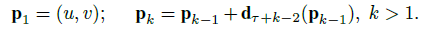
Bi-directional optical flow. + Mean flow subtraction.
- Bi-directional optical flow: 上面的两种光流信息都只利用了前向的光流信息,因此作者还尝试了加入反向的光流信息 (相当于倒放视频) 来得到双向的光流信息。同时为了方便与前向光流进行对比,输入张量 I τ I_\tau Iτ 的前 L L L 个通道为 τ \tau τ 和 τ + L / 2 \tau+L/2 τ+L/2 帧之间的前向光流信息,后 L L L 个通道为 τ − L / 2 \tau-L/2 τ−L/2 和 τ \tau τ 帧之间的反向光流信息
- Mean flow subtraction: 视频中的相机移动会使得光流帧叠加上无关的运动信息,因此作者对光流帧进行标准化,使其保持 0 均值
Multi-task learning
- 由于 temporal ConvNet 只能在视频数据集上预训练,而相对 ImageNet 而言视频数据集都比较小,因此作者在最后一个全连接层后加了两个 softmax 层,用于同时在 UCF-101 和 HMDB-51 数据集上做 multi-task learning
Implementation details
- Training: 提前将所有视频帧都 rescale 至最短边为 256,然后随机选取一张视频帧。从中随机裁剪得到 224 × 224 224 × 224 224×224 的 sub-image,在进行随机水平翻转和 RGB jittering 的数据增强后送入 spatial stream;最后同样随机选取一帧进行随机裁剪和翻转后计算出 224 × 224 × 2 L 224 × 224 × 2L 224×224×2L 的光流信息送入 temporal stream
- Testing: 由于视频帧数比较少,因此给定一个视频,我们在其中等间距地选取 25 帧,每帧都裁剪并翻转帧的四个角和中心,也就是每帧可以得到 5 个 sub-image,总共有 100 个输入分别送入双流网络,最后将 class scores 进行平均即可
- Optical flow: 光流信息的计算利用 OpenCV toolbox 使用 GPU 进行计算。虽然计算相邻帧的光流信息只需 0.06s,但如果在训练时动态计算光流信息仍会耗费大量时间,因此作者在训练前就提前计算好了所有光流信息。但数据集中的所有光流信息非常多,为了节省存储空间,作者将浮点光流信息的水平和竖直分量 rescale 到 [0,255] 后利用 JPEG 进行压缩,这可以将 UCF-101 数据集的光流信息大小从 1.5TB 减少的 27GB (计算光流信息需要耗费的大量时间以及存储空间仍是光流为人诟病的地方)
Evaluation

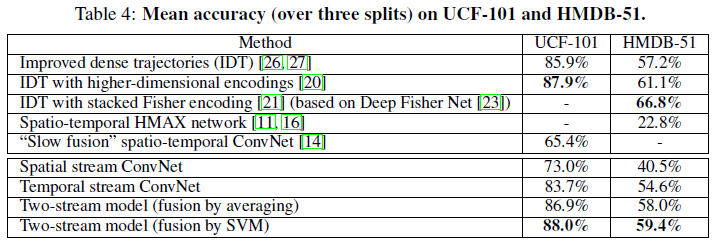
Enlightenment
- 双流网络的贡献不单单是使用了额外的时间流,它主要告诉了我们,当发现神经网络不能解决某个问题的时候,有可能仅仅靠魔改模型或目标函数是没办法很好地解决这个问题的,那我们不如给这个模型提供一些先验信息,模型学不到,那我们就帮它学。这样往往能大幅简化这个任务
References
- paper: Two-Stream Convolutional Networks for Action Recognition in Videos
- 双流网络论文逐段精读【论文精读】










