最近看到一些公众号上分享开源的FIFO实现代码,这里也分享一下自己常用的方法,就是改写的linux源码中的KFIFO。
FIFO是先进先出的队列,一般常用的都是环形FIFO。Linux源码中的KFIFO十分简洁,没有一行多余的代码,非常得高效。
首先说明一下,这套KFIFO是以linux内核2.26.30版本为基础,在其上改写而成的,去除了多CPU的内存保护处理,增加了几个常用的函数。
首先看一下KFIFO的数据结构定义:

就是一个结构体,内部包含缓冲区指针、队列大小、队列首地址、队列尾地址。
接下来介绍它的几个函数实现,下面是初始化函数:
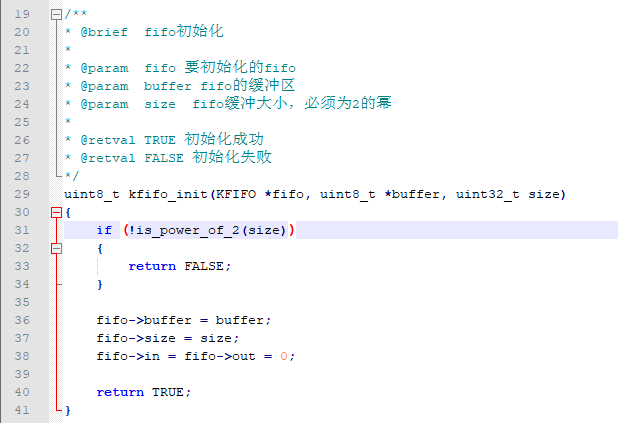
使用这个函数前,需要用户定义好fifo指针、缓冲区数组buffer、大小size。调用函数后,会对fifo进行初始化,之后就可以通过fifo指针来访问和操作队列了。
这里要注意的是,size大小必须为2的整数次幂。这是因为kfifo为了实现高效地进行队列的首、尾地址更新,使用了与(&)的方式去取余。
这个函数中判断是否是2的整数次幂的函数也实现得很巧妙:

接下来就是最重要的读取、写入队列的函数了,我们先看写入队列:

这个函数主要干了三件事:判断队列空间是否够用、将数据写入队列、更新队列首地址。
Len的更新,就是在判断队列空间是否够用;取了“输入数据长度”和“队列已有空间”较小的那个值,防止溢出;
接着,中间三句是将数据写入队列;这里先计算了个L,这个L的用处是,看从队首in到队列缓冲区buffer尾部的空间能不能放下len个数,如果放不下,则分两次,把L个数放到in至buffer尾,把len-L个数放到buffer开头。用图解释如下,数据写入前,in地址在in1处,写入L个数据后,到达buffer尾部,再从buffer头部开始写入,写入完成后,in地址在in2处:
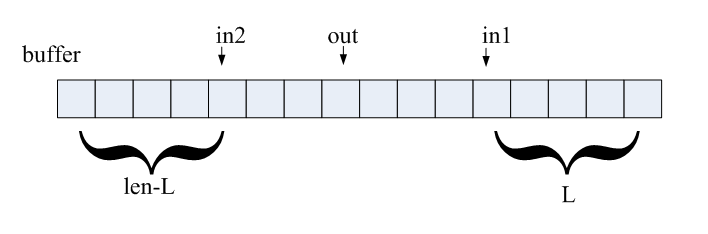
更新队列首地址时,代码中直接将in的值加上len就完成了(fifo->in += len;),这是因为队列的长度为2的整数次幂时,如果有进位,在后面使用时,进行一次与操作(fifo->in & (fifo->size - 1))就能将高位去掉,省去了取余的步骤。
读出数据的操作:

也是分为三步,先计算队列中是否有足够的数被取,再取数,更新队尾地址。
这里在取数时,也使用了与写入类似的方法,如果取的数据比out至buffer尾部的数据还要多,则分两步取走。与读取数据类似,就不赘述了。
最后是几个计算fifo长度、判断fifo空满及是否有可用空间的函数:

这里注意一点是,kfifo_len计算长度时,in的地址是始终会大于out的,因为in地址即使计到buffer末尾后再次回到buffer首部,in的值就会产生进位,而在写入函数kfifo_put更新in值时,并没有取余操作,所以in的值始终会比out大,计算len时就不会产生负值;即使在计满到32bit溢出时,也是能算出正确值的。细想一下真的是非常巧妙。
KFIFO用来拷贝数据的memcpy函数,它是c语言基本的库函数,包含头文件string.h后就可以使用。使用memcpy函数拷贝数据的好处在于,编译器会根据不同的硬件CPU架构进行优化,如果一次性拷贝比较多的数据,在32bit的CPU内,它会4字节、4字节地拷贝,这样拷贝的效率会比较高。而如果自己编写函数实现,则可能需要1字节、1字节地拷贝,效率会比较低。
使用KFIFO要注意FIFO的长度必须为2的整数幂次,这个前面分析过,如果不是则无法实现内存地址的回环。而恰恰是长度为2的幂次这个特性,使得更新队列首、尾地址,计算长度等操作时变得非常快捷。
Linux的源码中,KFIFO里还加入了防止多CPU访问时的内存冲突,因为在单片机中一般不会遇到,所以这里将这部分内容都简化掉了;简化后的代码,如果只是单线程的读、写,是不会出现读、写冲突的,也就是不用考虑特别的临界区保护。
一个简单的使用KFIFO的示例如下:
需要先定义KFIFO结构体、缓冲区、长度等变量,调用kfifo_init初始化后,就可以进行写入、读取操作了:

好了,KFIFO的一些知识就分享到这了。
欢迎大家关注我的公众号“小白白学电子”,可下载电路、源码,更多学习资源分享:











