数据结构知识点回顾:
二叉树的遍历主要有三种:
(1)先(根)序遍历(根左右)
(2)中(根)序遍历(左根右)
(3)后(根)序遍历(左右根)
举个例子:

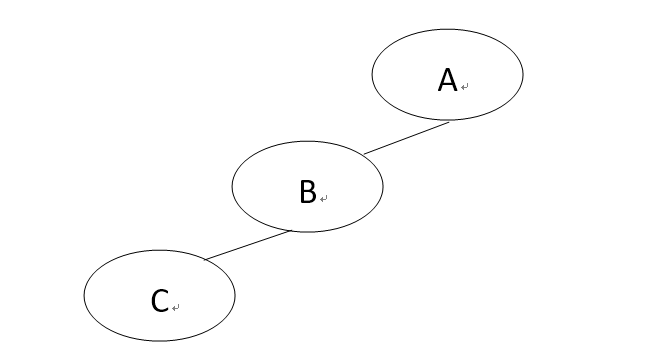
先(根)序遍历(根左右):A B D H E I C F J K G
中(根)序遍历(左根右) : D H B E I A J F K C G
后(根)序遍历(左右根) : H D I E B J K F G C A
以后(根)序遍历为例,每次都是先遍历树的左子树,然后再遍历树的右子树,最后再遍历根节点,以此类推,直至遍历完整个树。
命题:给定了二叉树的任何一种遍历序列,都无法唯一确定相应的二叉树。但是如果知道了二叉树的中序遍历序列和任意的另一种遍历序列,就可以唯一地确定二叉树。
个人总结:先由先序遍历或后序遍历找到根再由中序遍历分左右,下面继续再找根再找左右。
1、
答:CBA
二叉树图形如下:
2、
答:ABC


答:A



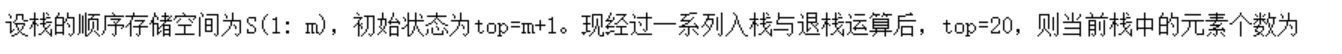

栈的顺序存储空间为S(1:50),初始状态为top=0。现经过一系列入栈与退栈运算后,top=20,则栈顶-栈底=20-0=20个元素。
栈是向上增长的,每次压入一个元素,栈的TOP指针向上移动一位。当压入第一个元素时,TOP指针指向m+1-1 = m当压入第二个元素时,TOP指针指向m+1-2 = m-1。
以此类推,当压入第N个元素时,TOP指针指向m+1-N = 20则N = m+1-20 = m-19。栈的顺序存储空间为S(1:50),初始状态为top=0。现经过一系列入栈与退栈运算后,top=20,则栈顶-栈底=20-0=20个元素。
一般平时是从栈底向栈顶压,这道题目中是倒过来的,这个栈是从栈顶向栈底压的,所以结果是m-19。top是指向最后一个元素上面的那个,所以是m+1 。
也就是说,栈是向上增长的,每次压入一个元素,栈的TOP指针向上移动一位。
当压入第一个元素时,TOP指针指向m+1-1 = m
当压入第二个元素时,TOP指针指向m+1-2 = m-1
......
以此类推,
当压入第N个元素时,TOP指针指向m+1-N = 20
则N = m+1-20 = m-19。
- 为了进行对分查找,要求满足两个条件:(1)必须迅速存储及使用数组存储链表是不能进行对分查找的,(2)数据由小到大或由大到小排序(即有序)。
- 算法时间复杂度是指执行算法所需要的计算工作量,是基本运算次数。与算法程序的长短和算法执行所需要的时间无关
- 希尔排序最坏的情况比较次数为n的r次方(1小于r小于二)。在最坏情况下,希尔排序的时间复杂度比直接插入排序的时间复杂度要小。
- 入栈的顺序规律是排在前面的先进,排在后面的后进。
- ①若TOP≥n时,则给出溢出信息,作出错处理(进栈前首先检查栈是否已满,满则溢出;不满则作②);
- ②置TOP=TOP+1(栈指针加1,指向进栈地址);
- ③S(TOP)=X,结束(X为新进栈的元素);
- 出栈的顺序规律是排在前面的先出,排在后面的后出。
- ①若TOP≤0,则给出下溢信息,作出错处理(退栈前先检查是否已为空栈, 空则下溢;不空则作②);
- ②X=S(TOP),(退栈后的元素赋给X):
- ③TOP=TOP-1,结束(栈指针减1,指向栈顶)。
- 栈允许在同一端进行插入和删除操作。允许进行插入和删除操作的一端称为栈顶(top),另一端为栈底(bottom);栈底固定,而栈顶浮动;栈中元素个数为零时称为空栈。插入一般称为进栈(PUSH),删除则称为退栈(POP)。
未完待续……










