@TOC
1 获取短视频页面信息
本次爬取的短视频网站是梨视频生活区,网址为https://www.pearvideo.com/category_5打开之后的页面是: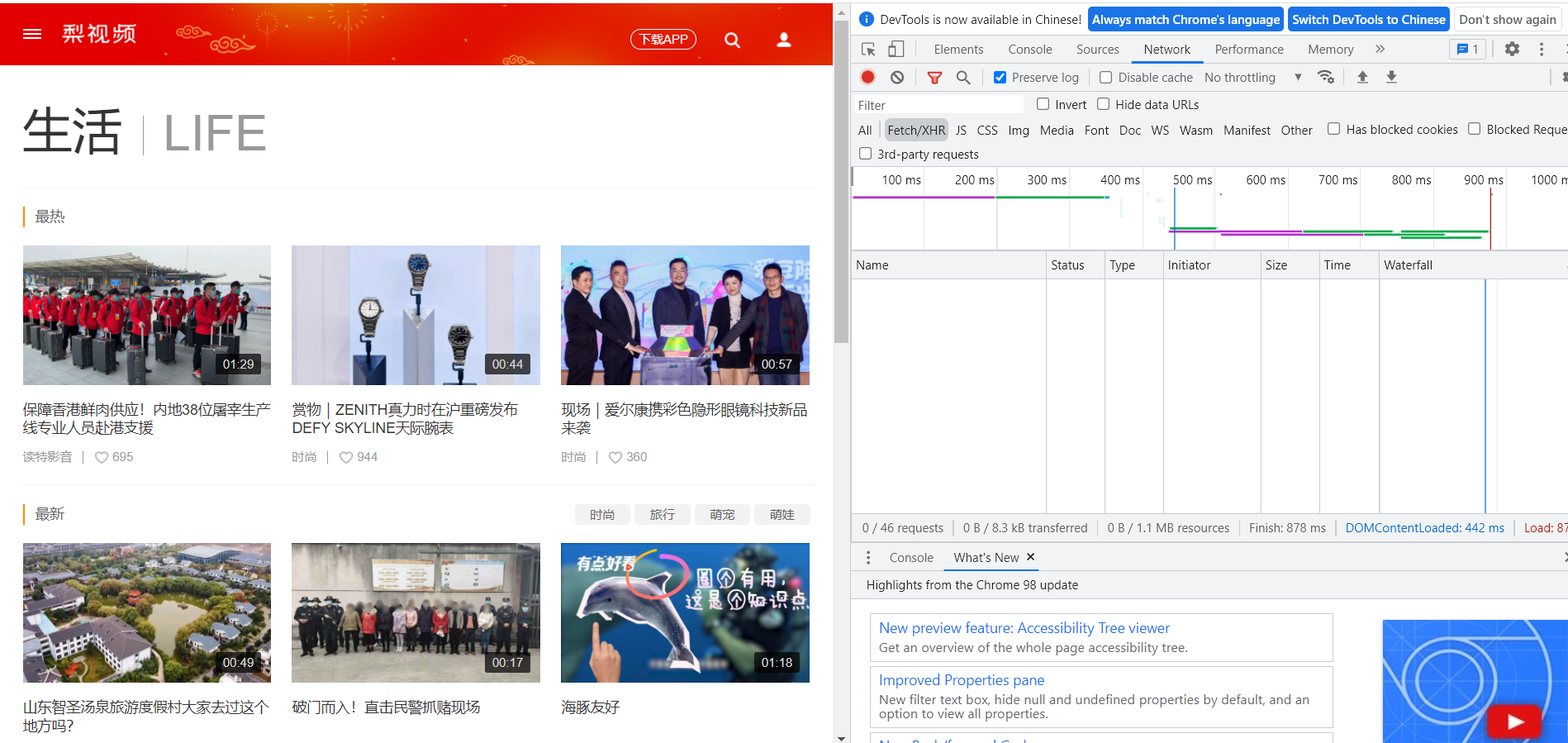 我是使用xpath数据解析工具,用这个原始页面初始化一个etree对象。要注意的是爬取梨视频的时候要使用session对象进行爬取。
我是使用xpath数据解析工具,用这个原始页面初始化一个etree对象。要注意的是爬取梨视频的时候要使用session对象进行爬取。
url = 'https://www.pearvideo.com/category_5'
session = requests.Session()
page_text = session.get(url = url, headers = headers).text
tree = etree.HTML(page_text)之后就可以根据xpath路径获取每个视频的网址,就可以对视频详情页进行请求发送,这里以最热的视频为例: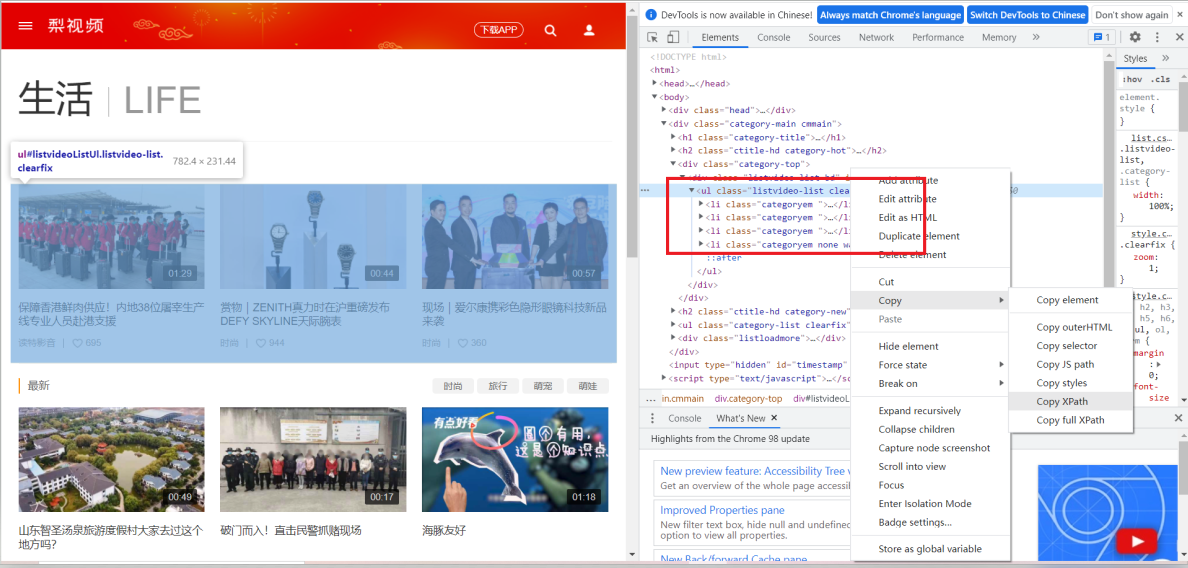 可以发现每个视频均在li标签下,那就可以获取ul标签下的所有li标签:
可以发现每个视频均在li标签下,那就可以获取ul标签下的所有li标签:
li_list = tree.xpath('//*[@id="listvideoListUl"]/li')找li标签下的a标签得到视频详情页的网址,但要注意的是那个网址并不完整,所以要自行补充完整。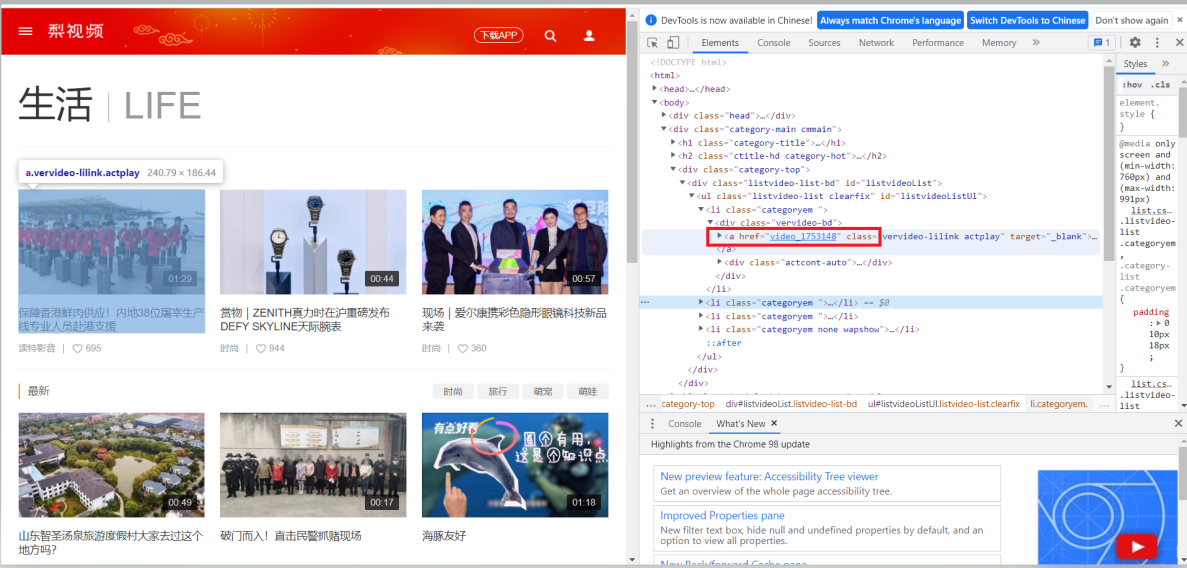
detail_url = 'https://www.pearvideo.com/' + li.xpath('.//a/@href')[0]
name = li.xpath('.//a/div[2]/text()')[0] + '.mp4'
#对详情页发起请求
detail_page_text = session.get(url = detail_url, headers = headers).text至此短视频的页面数据获取完成。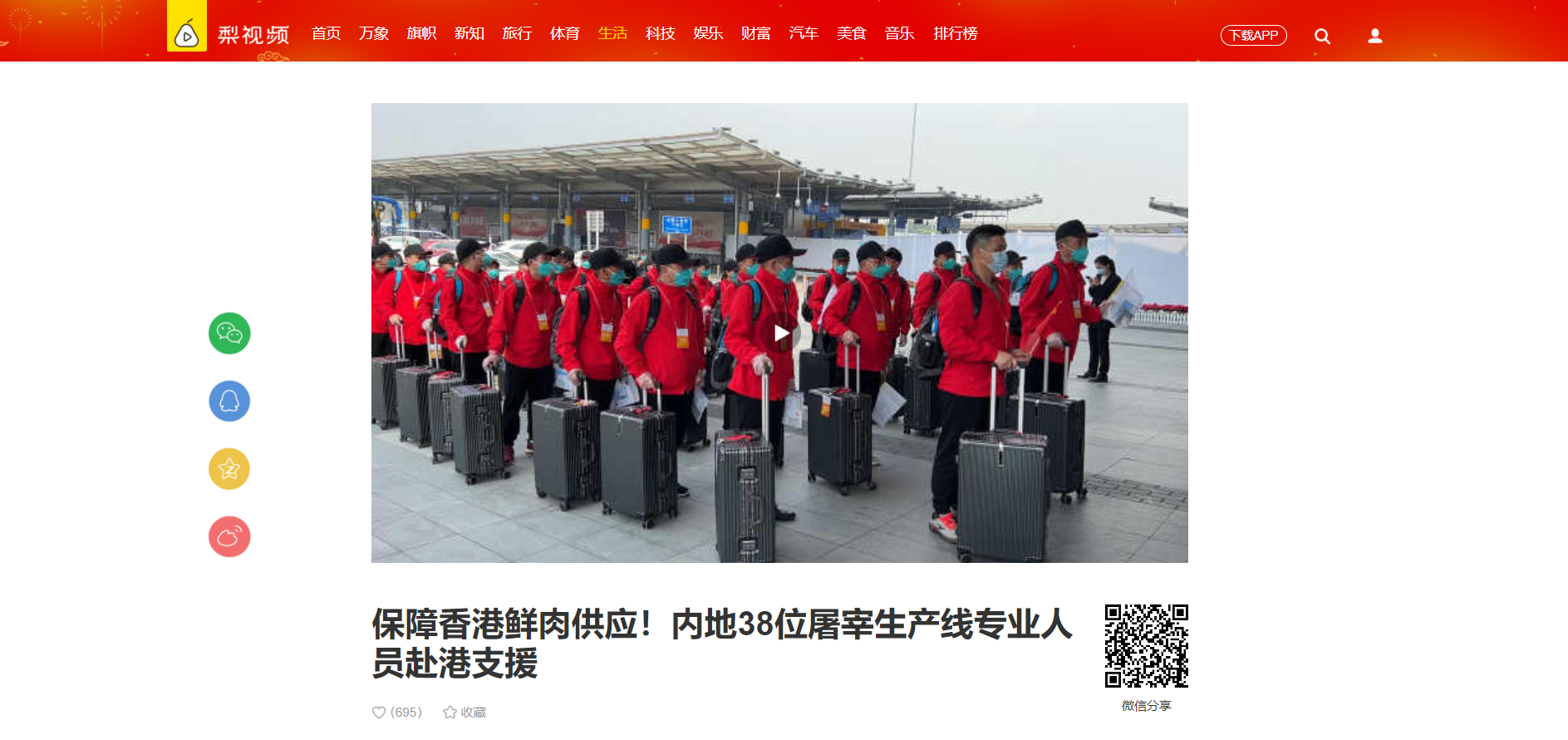
2 获取视频地址
获得短视频页面数据之后,按照常规的步骤,接下来应该从具体标签中获取视频的地址。
但是我们会发现得到的列表是空的,这是因为该网站的视频是动态加载出来的,我们可以进一步检验,打开详情页源码中的network下的Fetch/XHR选项然后对网址进行重新加载,就会看到抓包工具所抓取的数据。 对于动态加载的数据我们对请求方法进行传参,所需要传的参数在Payload栏进行获取。
对于动态加载的数据我们对请求方法进行传参,所需要传的参数在Payload栏进行获取。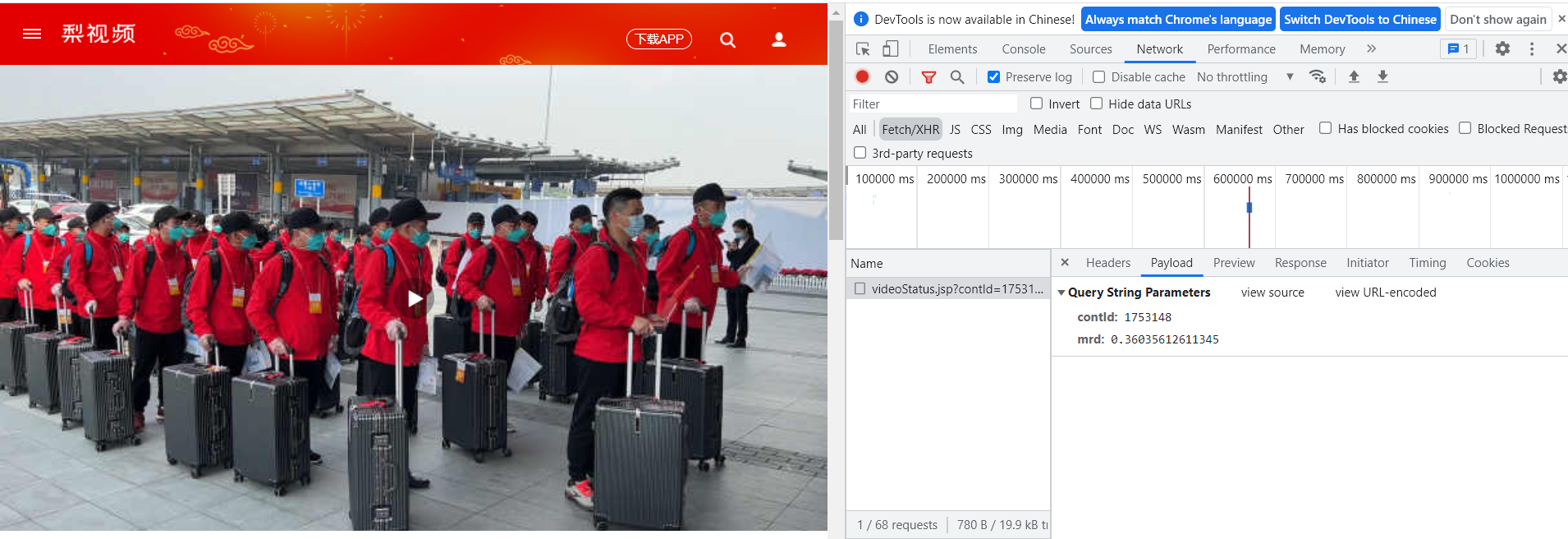 其中第一个参数是详情页网址后面的数字字符串,第二个参数是一个随机数。然后就可以对动态数据发送请求,要注意的是此时的url是动态数据的url,且得到的数据是json类型数据。
其中第一个参数是详情页网址后面的数字字符串,第二个参数是一个随机数。然后就可以对动态数据发送请求,要注意的是此时的url是动态数据的url,且得到的数据是json类型数据。
ajax_url = "https://www.pearvideo.com/videoStatus.jsp?"
params = {
'contId': detail_url.split('_')[-1],
'mrd': random.random()
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36',
'Referer' : detail_url #表示一个来源
}
json_data = session.get(url = ajax_url, headers = headers, params = params).json()因为返回json类型数据是一个字典,所以我们可以以字典的方式来获取视频地址。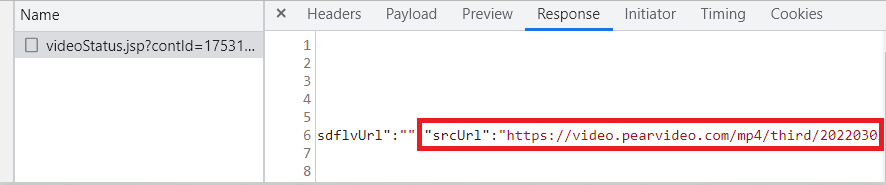 至此,我们都认为得到了视频地址,但其不然,梨视频网站还对视频的地址进行了加密,也就是我们从json响应数据得到的视频地址和在详情页标签中得到的地址不一样。但是两者之间的差距是有规律的。例如下面:
至此,我们都认为得到了视频地址,但其不然,梨视频网站还对视频的地址进行了加密,也就是我们从json响应数据得到的视频地址和在详情页标签中得到的地址不一样。但是两者之间的差距是有规律的。例如下面:
#正确的网址
src = 'https://video.pearvideo.com/mp4/third/20220223/cont-1752582-13293812-085442-hd.mp4'
#加密后的网址
src = 'https://video.pearvideo.com/mp4/third/20220223/1645596094850-13293812-085442-hd.mp4'可以分析知道只有后面的部分有差异,我们就可以利用字符串的拆分拼接和正则表达式进行破解。
rel = 'cont-' + params['contId']
lst = json_data['videoInfo']['videos']['srcUrl'].split("/")
false_src_part = lst[-1].split("-")[0]
real_vedio_src = re.sub(false_src_part, rel, json_data['videoInfo']['videos']['srcUrl'])以字典形式保存所有视频的名称和url。
vedio_info = {'Name' : name, 'Url' : real_vedio_src}
urls.append(vedio_info)3 使用线程池对视频进行爬取
初始化线程池,因为最热板块只有四个视频,所以传参为4.
pool = Pool(4)利用map()方法进行线程池抓取操作,然后对数据进行持久化存储。
#对视频链接发起请求获取视频的二进制数据,然后将数据进行返回
def get_vedio_data(vedio_info) :
url = vedio_info['Url']
data = requests.get(url = url, headers = headers).content
#持久化存储
with open('Vedio/' + vedio_info['Name'], 'wb') as fp :
fp.write(data)
print(vedio_info['Name'],'下载成功!')
pool.map(get_vedio_data, urls)关闭线程池。
pool.close()
pool.join()4 完整代码
import requests
import random
import re
import os
from multiprocessing.dummy import Pool
from lxml import etree
def get_vedio_info(headers) :
url = 'https://www.pearvideo.com/category_5'
session = requests.Session()
page_text = session.get(url = url, headers = headers).text
tree = etree.HTML(page_text)
li_list = tree.xpath('//*[@id="listvideoListUl"]/li')
urls = [] #存储视频的网址
for li in li_list :
detail_url = 'https://www.pearvideo.com/' + li.xpath('.//a/@href')[0]
name = li.xpath('.//a/div[2]/text()')[0] + '.mp4'
#对详情页发起请求
detail_page_text = session.get(url = detail_url, headers = headers).text
#注意这里,url要使用动态url
ajax_url = "https://www.pearvideo.com/videoStatus.jsp?"
params = {
'contId': detail_url.split('_')[-1],
'mrd': random.random()
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36',
'Referer' : detail_url #表示一个来源
}
json_data = session.get(url = ajax_url, headers = headers, params = params).json()
#寻找规则,将伪装网址替换成真视频网址
# src = 'https://video.pearvideo.com/mp4/third/20220223/cont-1752582-13293812-085442-hd.mp4'
# src = 'https://video.pearvideo.com/mp4/third/20220223/1645596094850-13293812-085442-hd.mp4'
rel = 'cont-' + params['contId']
lst = json_data['videoInfo']['videos']['srcUrl'].split("/")
false_src_part = lst[-1].split("-")[0]
real_vedio_src = re.sub(false_src_part, rel, json_data['videoInfo']['videos']['srcUrl'])
vedio_info = {'Name' : name, 'Url' : real_vedio_src}
urls.append(vedio_info)
return urls
#对视频链接发起请求获取视频的二进制数据,然后将数据进行返回
def get_vedio_data(vedio_info) :
url = vedio_info['Url']
data = requests.get(url = url, headers = headers).content
#持久化存储
with open('Vedio/' + vedio_info['Name'], 'wb') as fp :
fp.write(data)
print(vedio_info['Name'],'下载成功!')
if __name__ == "__main__" :
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
if not os.path.exists('Vedio') :
os.mkdir('Vedio')
urls = get_vedio_info(headers)
#使用线程池对视频数据进行请求(较为耗时的阻塞数据)
pool = Pool(4)
pool.map(get_vedio_data, urls)
pool.close()
pool.join()









