作者: 渐意
在上篇文章《解密函数计算异步任务能力之「任务的状态及生命周期管理」》中,我们介绍了任务系统的状态管理,并介绍了用户应如何根据需求,对任务状态信息进行实时的查询等操作。在本篇中我们将会进一步走进函数计算异步任务,介绍异步任务的调度方案以及系统在可观测性方面所支持的各项功能。
任务调度
任务调度多指系统根据当前负载情况,将不同任务放到合适的计算资源中去执行的相关操作。一个完善的调度系统往往需要平衡不同特点的任务间的隔离以及效率最优这两个需求。函数计算异步任务采用了独立队列模型及自动负载均衡策略,具备在不影响处理性能的前提下进行多租隔离的能力。
Serverless Task 任务调度模型
当用户提交一次任务后,系统会将该任务转换为一条消息,并通过异步下发的方式放入到内部队列中。一条消息的处理流程如下图所示:
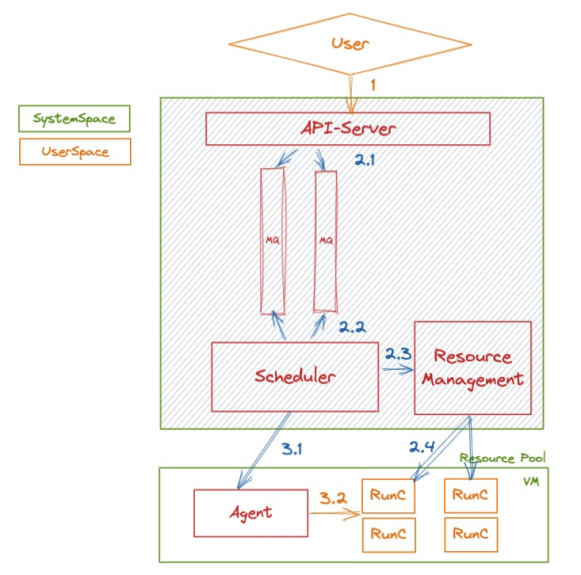
图 1
整个系统在任务调度方面的多租隔离及消息积压控制方面主要依赖的是 Scheduler 对于队列的消费及控制。我们事先会为每一位用户划分一个账号级别的队列,该用户的所有函数的异步调用(包括任务调用)会共享该队列。
这样的模型结构会保证每个用户的异步执行请求(包括任务调用)均不会受到其他用户的调用情况的影响。但是在一些大规模应用场景,如一个用户的函数很多,并且每个函数的调用量都很大的情况下,所有的异步消息共用一个队列难免造成调用间的相互影响。部分长尾调用可能会过多的消耗队列的资源,导致其他函数的执行出现饥饿的现象。
为了避免这种情况影响重要函数的执行,函数计算提供了更细力度的队列 - 函数级别的队列。可以通过对每个不同函数设置单独的队列,确保高优先级函数的消费情况不会受同账号下的其他函数执行的影响。队列间的关系如下图所示:
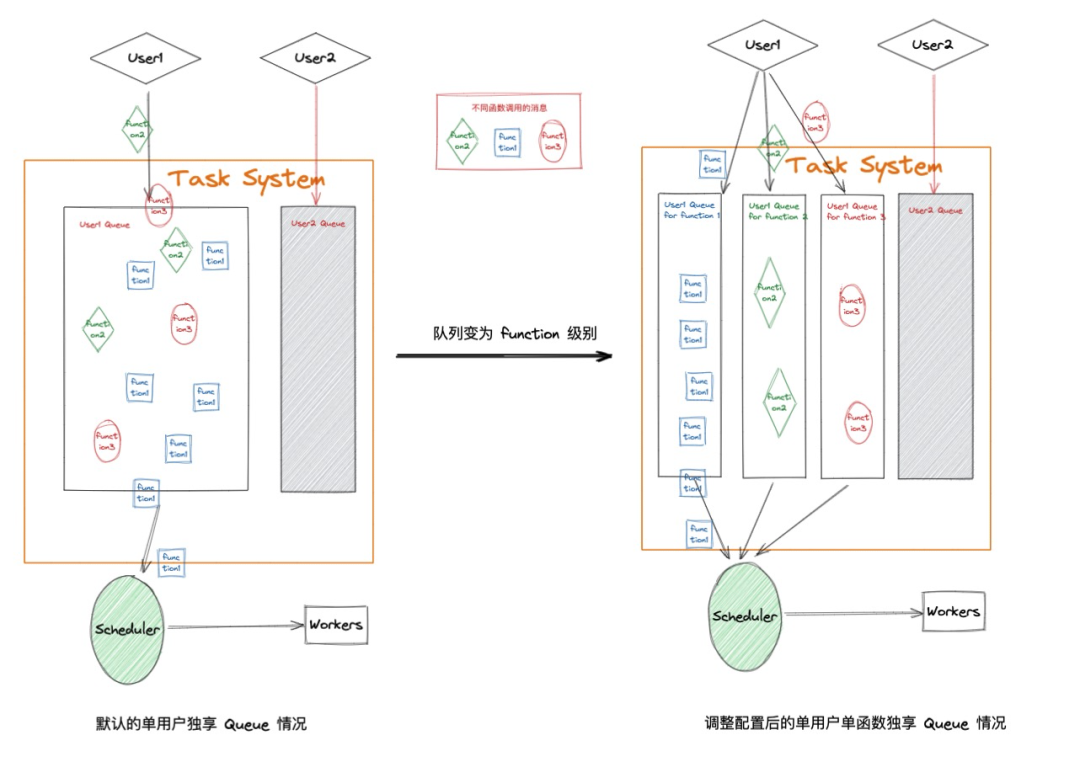
图 2
典型的应用场景
假设某用户 A 具有 2 个不同的任务函数。其中一个任务 A 由于下游服务的限制,需要一个消息一个消息的执行;而另外一个任务 B 是大并发任务,并且希望尽快执行完。在默认模式下,任务 A 和 B 共享同一个用户队列;这时会出现如下场景:任务 A 由于具有并发度限制,函数计算侧会对整个任务队列进行出队速率控制。这就导致了任务 B 的任务迟迟无法出队。而当任务 A 执行完后,任务 B 得到了出队机会,此时并发度升高,任务 B 的消息抢占了资源池进行执行,任务 A 又变得难以出队,很长时间也无法开始一次执行。这样的结果就是无论 A 还是 B 都受到了对方业务的严重干扰。
当进行队列调整后,任务 A 和 B 分别独占队列。在这种情况下任务 A 和 B 的消费速度不受对方影响,都可以达到自身的诉求。
目前 Serverless Task 提供了任务积压大盘,您可以在任务界面获取目前已经积压的任务数,综合分析是否需要开启函数的独占队列。
Serverless Task 任务队列负载均衡模型
上面介绍了如何通过函数级别队列来避免出现 “Noisy Neighbour” 问题。但是在一些场景下,如果任务的并发量级过大,即便对该任务划分了单队列,也会导致任务的积压。这个问题的解决需要引入 Serverless Task 的负载均衡策略。
函数计算的任务处理模块具有 Partition 的概念。每个用户默认属于一个 Partition,负责该 Partition 的 Scheduler 会监听用户对应的任务队列。当出现严重积压时,我们会为用户按照负载情况分配多个 Partition,并交由不同的 Scheduler 负责消费,来提升任务整体的消费速度。
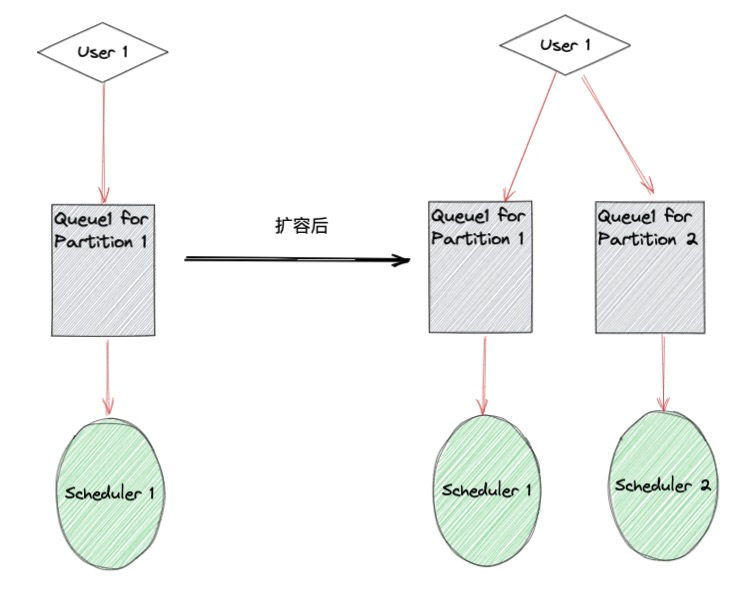
图 3
可以看到,阿里云函数计算在任务队列管理方面默认做到了多租及隔离的能力,可以适用于绝大多数场景。针对一些重负载、长执行、并发量大的场景,函数计算还支持横向扩容,加快消费速度。在任务隔离方面,函数计算支持针对不同优先级的函数进行单独隔离,避免出现 Noisy Neighbour 的问题。
可观测性
任务的可观测能力是任务系统必不可少的能力之一。强大的可观测性将有助于业务方减少在任务运行的各个阶段所需要额外进行的工作量。
- 开发阶段:任务的在线调试能力、运行结果的 Debug 能力将直接影响业务上线进度;
- 业务常规运行阶段:各种监控、流量情况的统计以及运行时日志将协助用户快速了解业务的发展、变化,以及出现故障时的快速定位 & 处理;
- 阶段性审计:任务的历史记录存储及保留将为用户提供良好的可追溯能力,可以根据历史信息进行后续的业务规划。
ServerlessTask 可观测性支持 - 开发测试阶段
业务的开发阶段最主要的诉求就是快速调试并定位问题。在对该阶段的支持中,ServerlessTask 提供了登录实例及实时日志的能力。当代码开发并上传后,测试 - debug - 修改代码 - 再次测试的流程可以全部在控制台完成,极大的提高了研发效率。如果有需要性能调试、第三方 Binary 调试(如音视频处理领域的 FFmpeg 调试)等可以借助登录实例功能完成。操作流程如下所示:
选择想登录实例的任务,点击实例链接。

会进入到实例监控页面,点击右上角的登录实例功能,即可登录到对应的实例上。
ServerlessTask 可观测性支持 - 业务上线后运行阶段
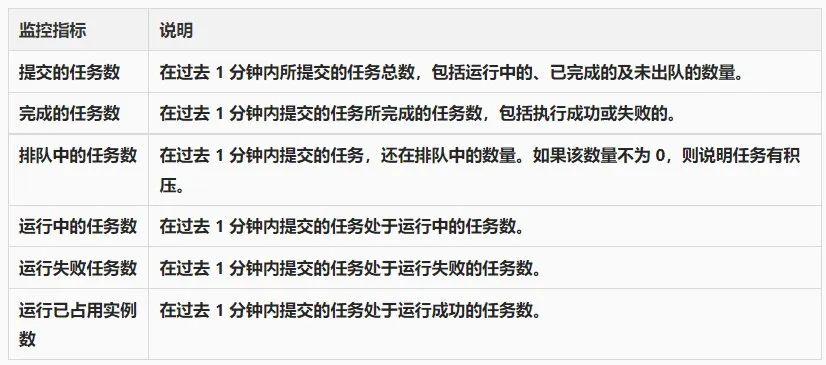
当业务上线后,经常容易出现因容量预估不足导致下游系统无法承载压力,导致故障。因此 ServerlessTask 提供了运行时指标,即一段时间内的任务提交数、完成数及执行情况。用户可以根据这张指标图快速了解当前业务的负载情况。当用户任务的下游消费较慢,可能造成任务积压,这种情况也很容易在指标图中反映出,进而快速做出相应的反应。目前 ServerlessTask 所提供的相关指标如下:
任务监控大盘提供以下任务监控数据:
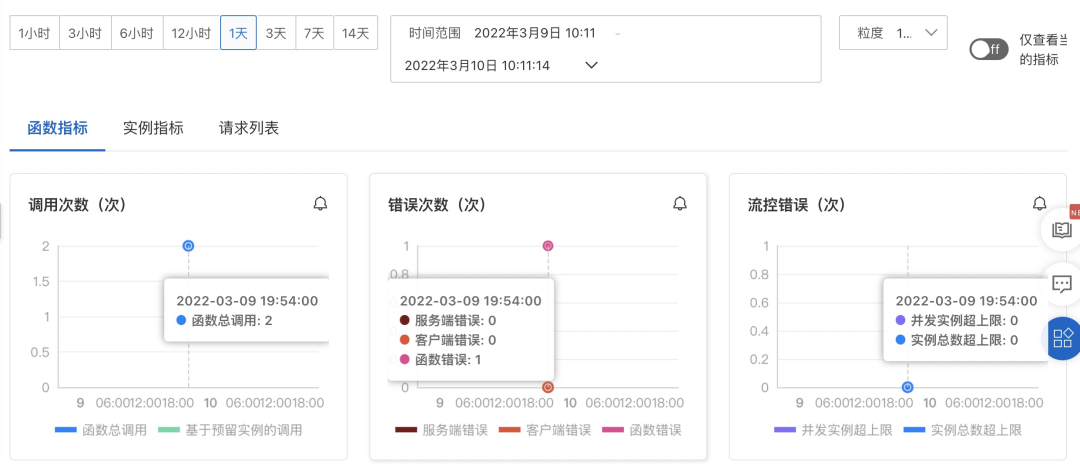
在快速定位问题方面,函数计算支持实时查看函数日志及实例指标。您可以进入到任务的列表页面,找到实际执行失败的任务,进入日志页面及实例页面进行问题定位:
ServerlessTask 可观测性支持 - 阶段性审计
当线上任务运行一段时间后,往往需要进行一系列的阶段性审计工作,比如上一周的执行总任务数,执行失败的任务数及执行失败的时间。目前除了控制台以外,函数计算提供了丰富的 API 能力来进行任务的审计工作。主要包括以下几方面能力:
- 根据状态进行过滤,只查询某一个状态的执行;
- 根据触发时间进行过滤,如查询过去某一段时间内发起的任务;
- 根据任务名称查询。如果您的任务具有业务上下游的 TraceID,您可以在触发任务时指定一个有意义的任务ID。后续可以根据 ID 前缀进行范围查询;
上面的几个过滤方式可以组合,达到更便捷的需求。控制台所支持的过滤条件如下图所示:

更多参数内容可参考:
https://help.aliyun.com/document_detail/256588.html
ServerlessTask 可观测性支持 - 死信队列及业务补偿
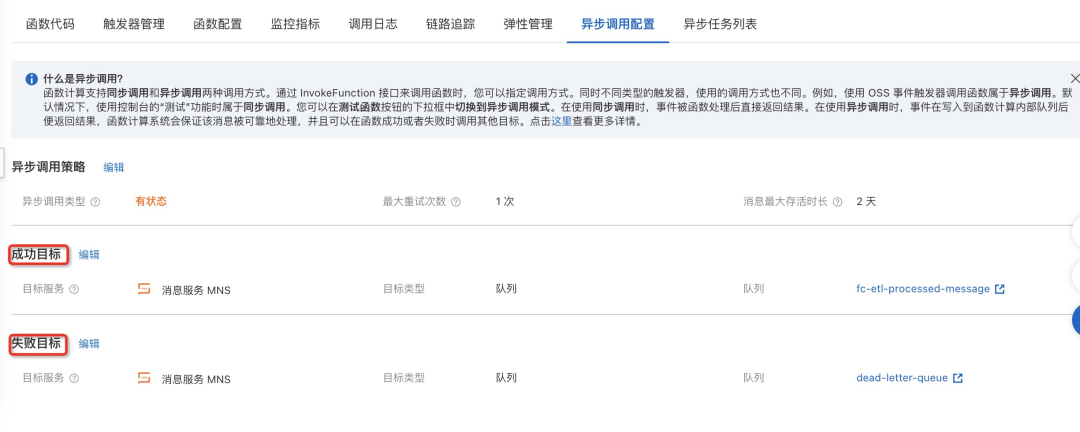
在消息领域,有一个非常重要的概念 - 死信队列。当一些消息无法被消费时,这些消息往往需要存储到一个地方,以便后续人为的介入处理,避免因未进行处理而造成业务损失。Serverless Task 也支持了这样一类功能。您可以对 Serverless Task 设置目标功能;当任务执行失败后,函数计算支持自动将执行失败的上下文信息推送到消息队列等消息服务中,以便后续处理。如果您的处理逻辑支持自动化,函数计算还支持将失败任务的上下文信息推送回函数计算,执行一段您的自定义业务逻辑来实现业务补偿。
您可以在异步调用配置页面配置成功及失败目标。
更多配置内容请参考:
https://help.aliyun.com/document_detail/415755.htm。
综上所述,Serverless Task 所提供的可观测能力可以有效支持任务全生命周期的监测需求。所有控制台能力均可以使用开放 API 进行定制化开发,来满足更多的需求。Serverless Task 的目标功能除了可以做到任务失败补偿以外,还可以作为 Event-Driven 模式的数据源,自动的将处理后的事件投递到下游服务中。










