前言
工作以来一直在做运维平台相关的研发工作,最近计划总结下对运维体系建设的思考,总结出一个通用模型,后续持续迭代,欢迎一起探讨交流。运维的工作主要有三个方向,稳定性、效率、成本,本篇是第一篇,稳定性篇。
下面开始正文
概述
运维工作的核心目标是保障线上业务可以稳定的运行,降低故障发生次数,缩短故障发生时间。因此稳定性方向的建设工作,我们可以从故障的整个生命周期角度入手,来展开保障稳定性的工作。故障的生命周期有预防、发现、定位、止损、复盘五个阶段。下面我们就从这几个阶段逐个介绍我们可以做哪些工作。
首先我们可以对故障进行分类,有哪些原因会导致故障,从本质上看,所有的故障都是因为变化引起的,有一个不可避免的变化因素“时间”,从变化的角度分析,有计划内变化和计划外变化两大类,由此可以梳理出故障分类的脑图。
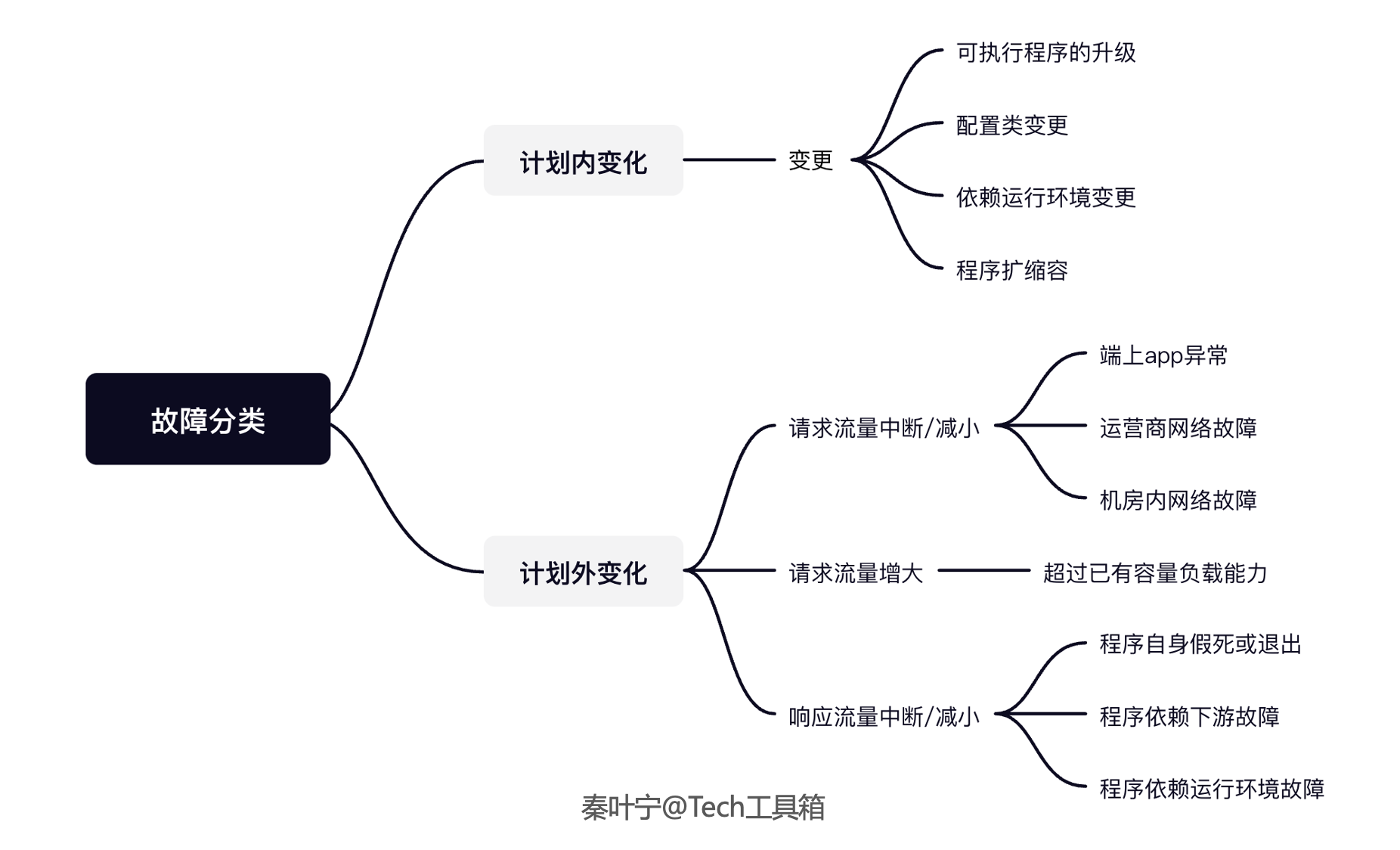
预防
预防阶段我们需要做的工作是降低故障的发生次数,可以从计划内变化和计划外变化两个方面考虑。
计划内变化
从每年对故障记录的总结分析上看,引起故障最多的就是主动变化类的变更,大部分都是因为操作不规范导致的。所以故障预防阶段,我们可以重点从规范变更流程入手。首先需要建立规范制度,之后将规范集成到平台中,最后还需要有评价体系,将变更操作规范程度通过分数量化出来。高分的表扬,低分的督促改进。
规范制度方面
全公司拉齐规范流程,对于因为违反规范流程而导致的故障,事后要进行重点总结复盘。变更规范可以有下面几条,仅供参考
- 变更之前 业务高峰期要禁止变更操作
- 变更之前 所有线上变更操作都要进行通告,包括运营人员操作的变更
- 变更之前 找相关人一起 double check
- 变更之前 要求所有的变更都要有回滚机制,回滚操作一定要提前进行演练
- 变更过程中 要进行灰度发布
- 灰度过程中 要及时查看相关的监控指标
平台建设方面
变更平台一方面可以提高我们的软件功能交付效率,另一方面,也可以起到规范变更流程的作用,上一小节介绍的流程规范内置到变更平台中,可以保证不了解规范的新人,也会遵循变更规范,减少由于变更不规范而引发故障的次数。
评价体系方面
待变更平台建设完成后,我们可以从变更平台拿到每个业务线的操作数据,根据变更规范要求,对操作进行打分,起始分数是满分,哪点没遵守就扣一些分,扣分规则可以和业务通过协商达成一致。最后以业务线的维度对分数排名定期通晒,从上到下推动变更规范落地。
计划外变化
对于计划外的变化,我们可以在容量和程序健壮性两个方面做一些工作
程序健壮性
- 设计阶段,运维的同学从这个阶段就需要开始介入,评估架构是否有单点风险,程序是否有过载保护,等达到性能瓶颈之后,是否有降级能力,是否有限流能力,是否可以水平扩展
- 编码阶段,推动研发团队建立 code review 机制
- 测试阶段,建立和线上完全一致的测试环境,在上线之前,做好充分的测试,避免遗漏场景,提高自动化测试的覆盖度
- 维护阶段,引入混沌工程,定期对整个服务链路进行盲测,提前发现薄弱环节
容量
我们可以建立完善的压测机制,定期对服务进行压测,提前发现服务的性能瓶颈,及时扩容优化,保障服务稳定运行。
发现
故障发生时及时发现,是降低故障时长的重要一环,要想及时发现故障,就需要对线上业务做全方位的监控。在监控领域有三个支柱,Logging、Metrics、Tracing,其中 Logging 和 Tracing 都是比较细粒度的数据,Metrics 是一种聚合类的时序数据,可以观察服务的状态和趋势,很合适作为判断服务是否异常的依据。所以在故障发现这个层面,我们可以重点在 Metrics 方向做建设。
首先我们对常见的线上业务的数据流模型进行分析,以此来总结一套监控数据体系。
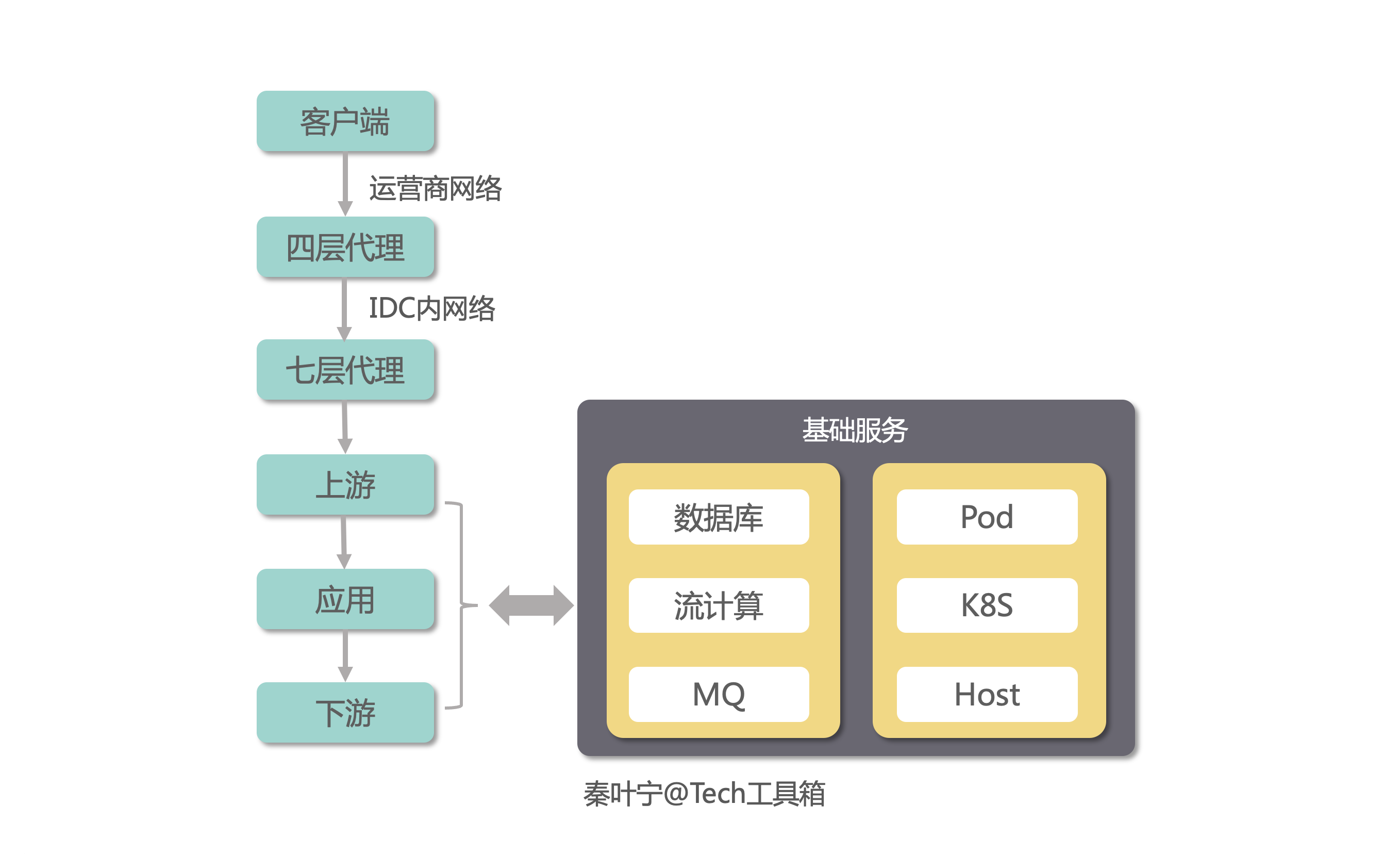
上图是一个线上业务常见的数据流模型,要想做到及时发现线上问题,每一个节点都需要进行数据采集和监控
数据采集
根据上面的数据流模型我们可以梳理出下面的监控采集场景。

我们把采集数据的场景分为五层,不同的层面由不同角色的人来推动监控数据的采集建设。
- 客户端数据可以基于 trace 平台采集端上的数据
- 业务层数据可以使用 canal 从 mysql 的 binlog 中提取业务数据,也可以通过约定日志规范从日志中提取
- 模块层数据可以通过 sdk 埋点,解析日志的方式获取 QPS、错误率和响应时间,如果公司有统一的接入层,也可以从接入层来获取
- 基础组件层数据通过编写采集插件或者使用 telegraf 这样的开源工具采集对应组件的监控数据
- 硬件层数据可以通过部署监控 agent,使用 snmp 协议等方式来采集数据
- 网络链路数据可以基于 trace 平台收集用户访问质量数据,基于内部 agent 互相探测采集机房内和机房间的连通数据
数据异常检测
监控数据采集完成后,就可以对数据做异常检测了,所有时序数据的异常从本质上可以总结为下面五类
- 数据中断
- 上涨超过某个数值
- 下降低于某个数值
- 一段时间内上涨过快
- 一段时间内下降过快
我们可以针对这五种情况,开发我们自己的异常检测引擎,异常检测引擎的建设可以分为两个阶段
第一个阶段,可以实现基于固定阈值的异常检测函数,根据历史经验配置一个固定的阈值,固定阈值检测的优点是易于落地,缺点是需要依赖人的经验,有时候需要不断调试才可以找到一个合适的值,不同的业务需要不同的配置,同一个业务隔一段时间可能还要对阈值进行调整,这样带来了一定的人力成本消耗。
第二个阶段,在人力充足的情况下,我们可以引入基于机器学习的异常检测算法,动态的计算出一个阈值。我们只需要关注对这些指标进行监控,而无需关心它的上下限阈值。一方面可以节省配置告警策略的人力成本,另一方面也降低了对人的经验的依赖。引入智能异常检测算法的工作主要是将已经成熟的算法,工程化落地到我们自己的监控平台。
告警事件通知
告警通知我们需要关注下面几点
- 不能误报,误报太多容易造成狼来了效应
- 通知不能太多,海量的消息等于没有消息,因此需要在告警事件的聚合方面做一些工作
- 要确保信息可以触达到 oncall 的人员
评价体系
从数据驱动的思路入手,我们可以统计下面几个指标,一方面体现我们的工作成果,另一个方面也可以推动故障发现机制落地。
平台侧可以统计
- 告警漏报次数,每次复盘都记录下是否漏报
- 告警误报次数,每次误报都进行记录
- 告警通知次数,通过降低通知次数,来推动告警通知在抑制和聚合方面的优化
业务侧可以用下面的指标给业务打分
- 采集覆盖度
- 告警策略覆盖度
- 接收告警通知的数量
定位
首先我们要对故障进行定义,只有影响到线上业务稳定运行的,才算是故障。故障定位的目标不是要找到故障的根因,只要定位到可以做止损动作的决策点就可以了。为了更高效的定位,我们可以从下面两个方面入手
- 流程建设,建立明确的故障定位处理流程
- 体系建设,建立完善的故障定位平台体系
流程建设方面
- 建立值班制度,每个业务需要有值班人,重大故障需要有值班长的角色负责整体的协调。
- 建立故障定位处理流程,故障通报、信息同步、协调人力、决策机制、执行机制等。
平台建设方面
建设平台的目的是可以将信息聚合到一起,辅助大家快速发现到可以止损的决策点,故障定位的目的是确认故障影响范围,以及故障属于哪种类型,之后根据故障类型执行相应的预案。我们可以从空间和时间维度去思考如何加速故障定位的过程。
从空间层面
我们要快速了解故障的边界,确定到底影响了哪些服务,影响范围越明确,越容易找到问题。基于这个目标。我们可以从模块、场景再到业务三个层次去建设每个层次的成功率。要做这件事情的前提是我们已经把每个模块的核心接口的请求数,错误数都采集到了,之后每个模块可以计算出一个整体的成功率,再由多个模块计算出所属场景的成功率,最后计算出整个业务的成功率。如下图所示
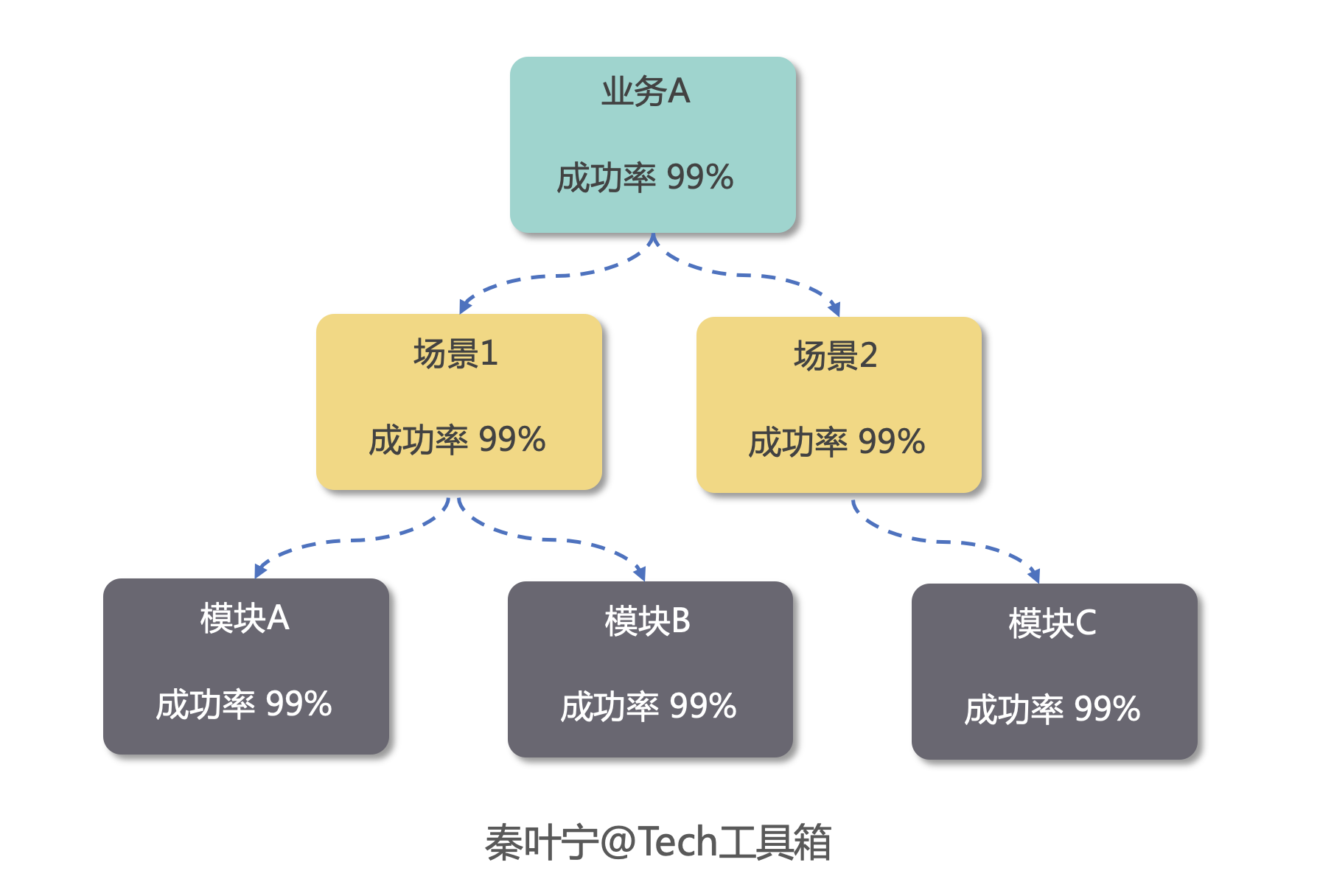
通过这样一个整体的成功率大盘,可以快速将问题收敛到一个或几个模块中。滴滴内部把这样的产品叫做灭火图。当定位到模块级别之后,下面要分析出问题的模块是由于什么原因出问题了根据上文中的故障原因分类可知,如果是成功率下跌,要么是自身出问题了,要么是下游出问题了。如果是自身出问题,直接查看模块自身监控大盘。
如果是依赖的下游出问题,要想知道是哪个下游,我们需要提前梳理和下游的依赖关系,首先看一下出问题的模块会有哪些依赖,关于模块依赖关系的梳理,可以通过构建 trace 平台,自动生成依赖关系。如果公司没有 trace 平台的话,那看到这篇文章的你可以考虑搭建一套 trace 平台了,现在比较流行的有 jaeger、skywalking、tempo。但 trace 平台的落地需要一段时间,这个时候,可以推动运维同学和模块负责人一起手动梳理模块的依赖,将模块自身的容量、每个依赖调用的请求量,成功率,分位值延迟都配置成图表,配置到一个监控大盘,从模块成功率图表可以直接跳转到模块的监控大盘中。这样模块依赖的哪个下游出问题了,也就一眼能看到了,如下图所示。
从空间层面,通过灭火图+监控大盘,可以从 业务-》场景-》模块-》依赖 定位到某个模块的某个功能故障点。
当 trace 平台搭建完成之后,我们还可以继续向下追踪,以时间和模块为依据,继续下钻到报错接口的请求链路
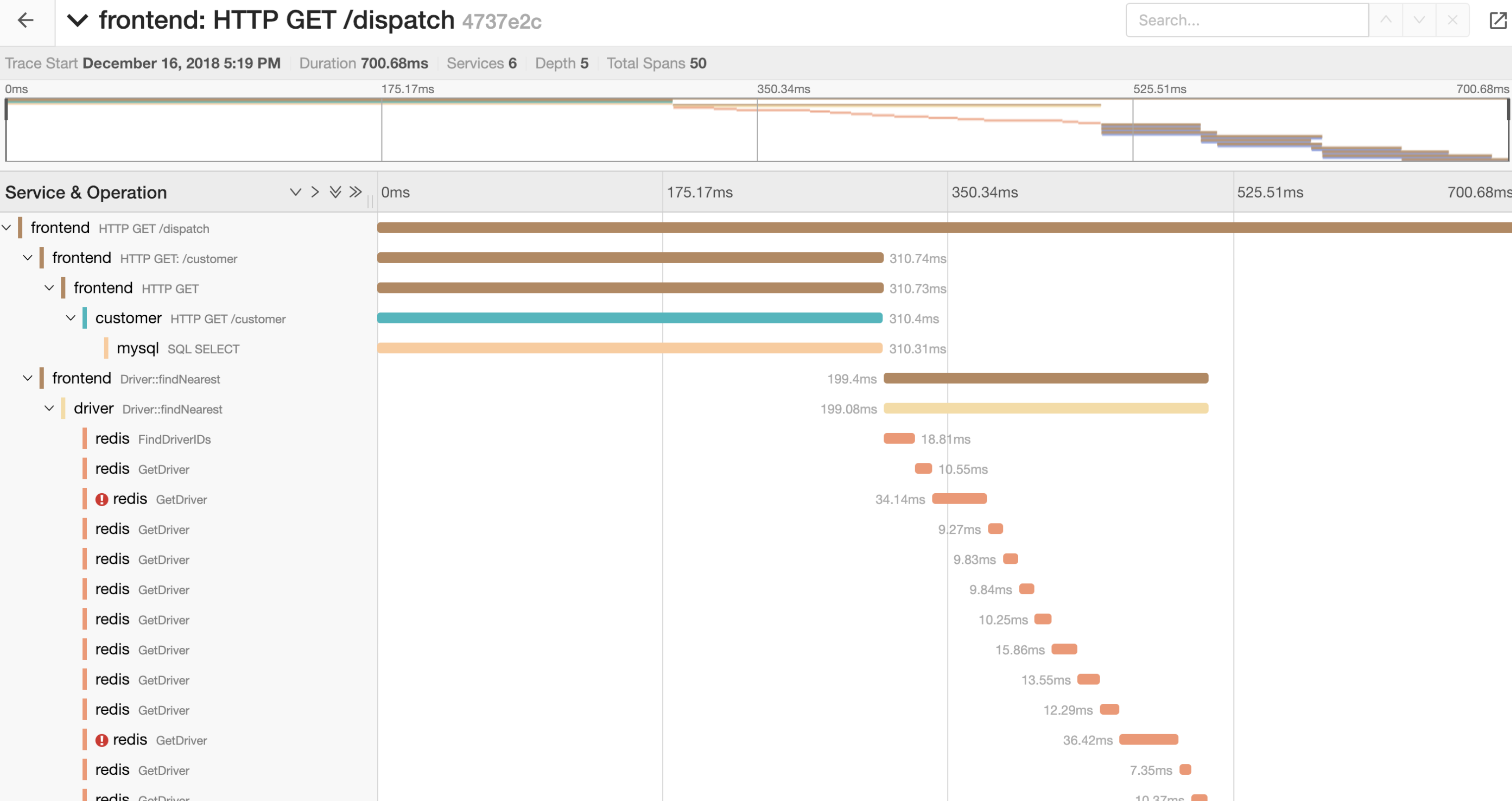
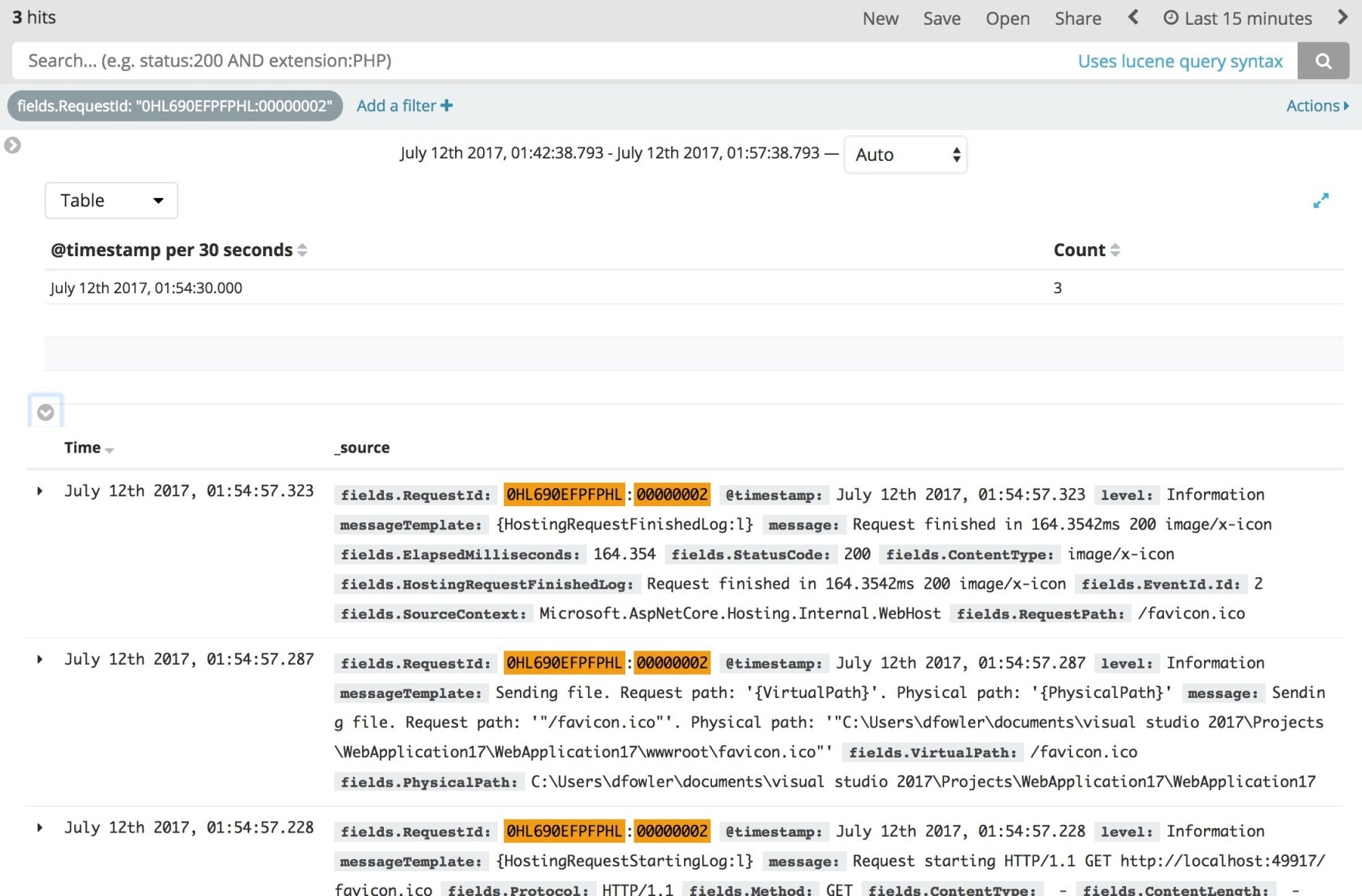
再根据 traceid,联动日志平台,继续追踪到详细的日志
从时间层面
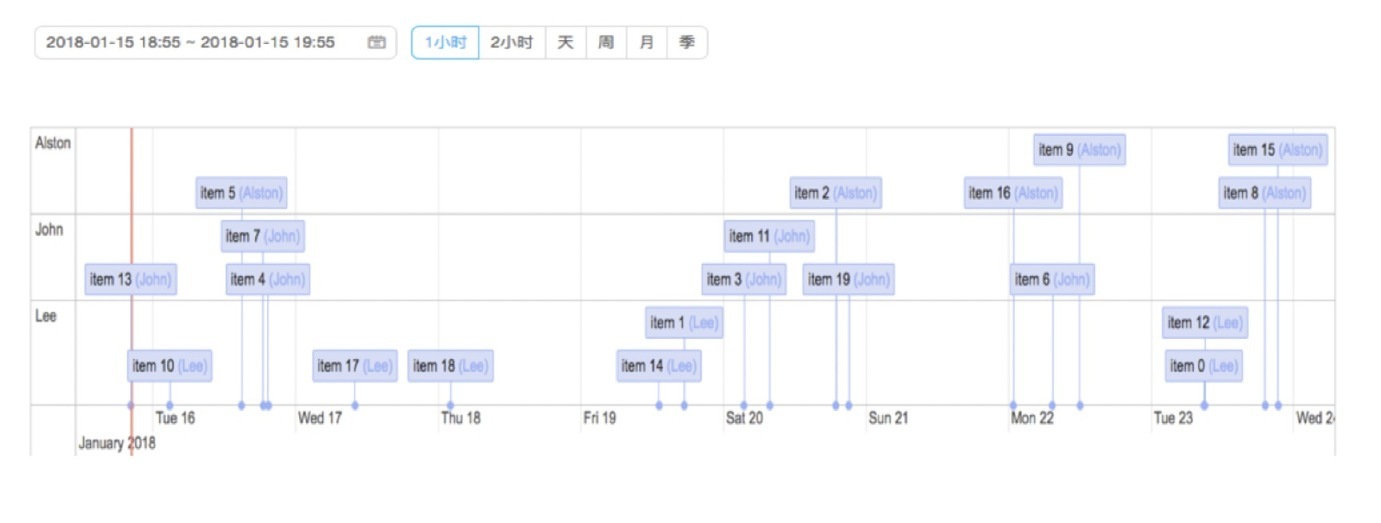
我们可以观察下故障发生时刻最近一段时间,都发生了哪些事件,包括告警事件,变更事件,运营事件。离故障发生时刻比较近的事件,很可能是导致故障发生的原因。通过将事件以时间线的方式展示出来,可以辅助我们判断是否是网络故障、变更操作导致的故障。
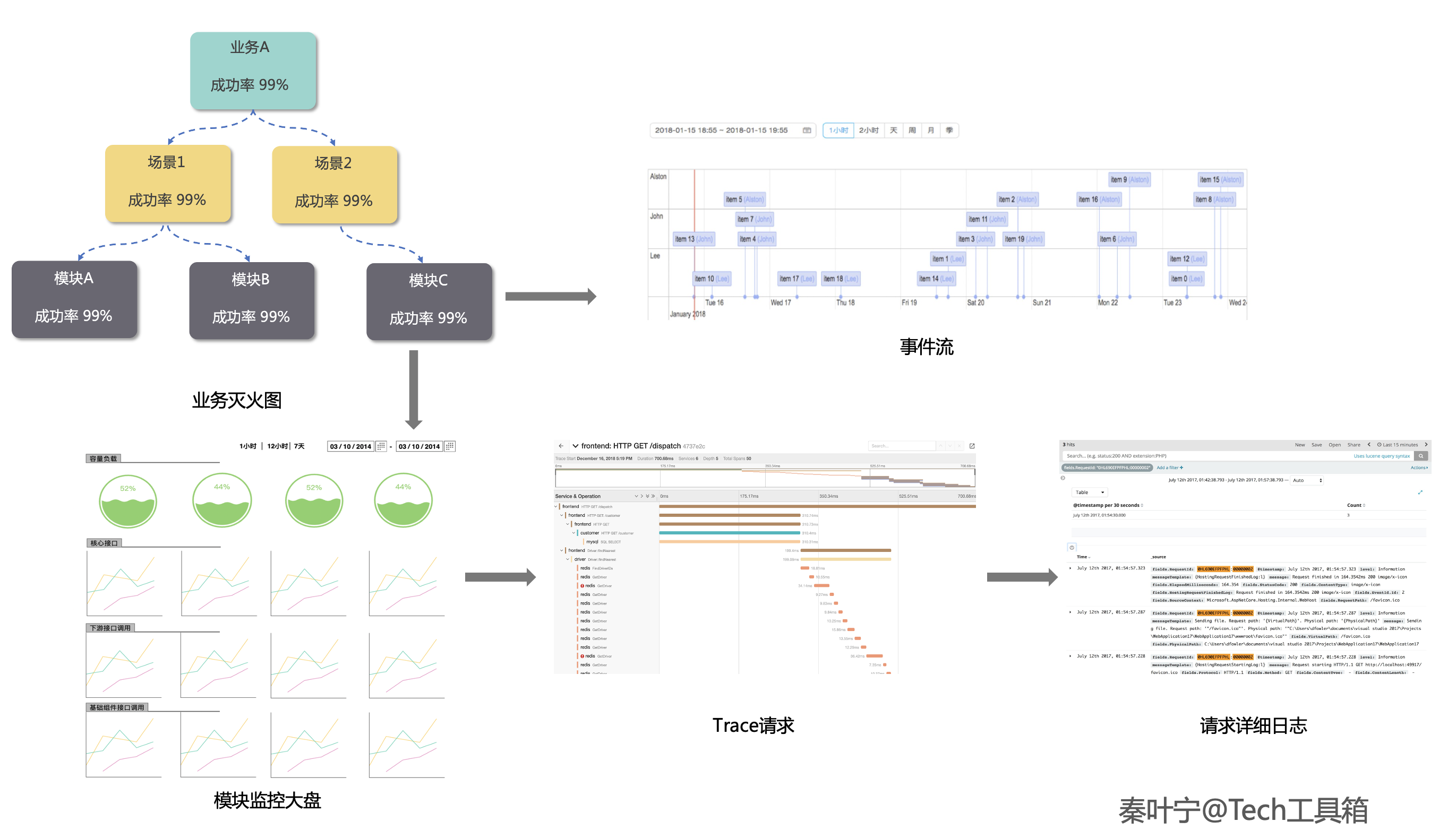
最后整个定位流程可以总结为下面一张图
评价体系
平台侧可以统计每个故障从故障发现到故障定位之间消耗的时间,看长期的变化趋势,可以量化我们在故障定位方面的工作成果。
业务侧可以用下面的指标给业务打分
- 灭火图模块接入覆盖度
- 告警大盘配置覆盖度
- trace 接入覆盖度
- log 接入覆盖度
止损
上文中,我们已经梳理出了线上服务出现故障的分类,那针对每一类故障原因,我们可以梳理出对应的预案执行流程,之后再建设预案自动化平台,将预案流程自动化,梳理内容见下图。
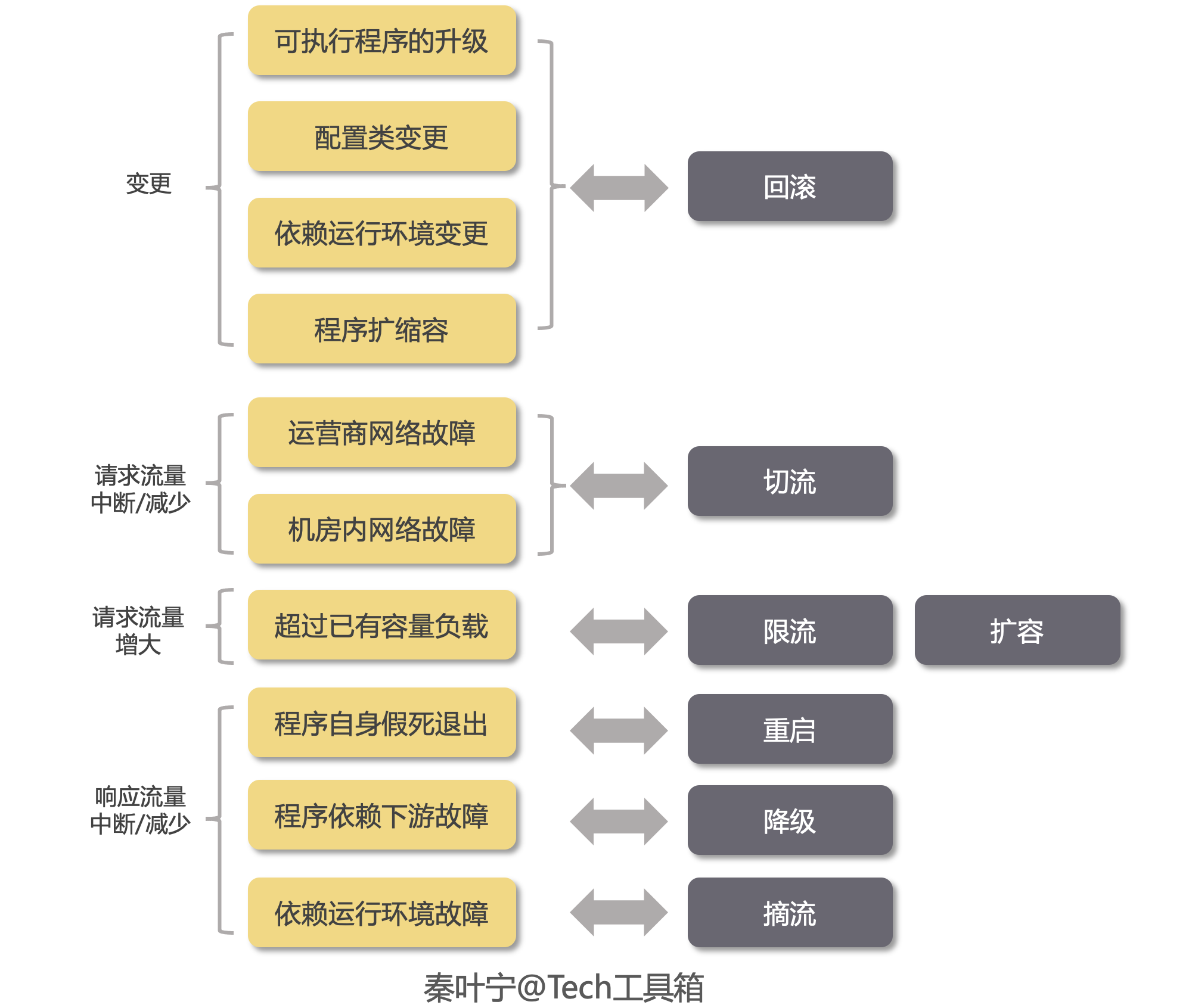
所以对于每一个业务,负责该业务运维的同学可以和业务研发一起建立下面七种预案流程。
- 回滚
- 切流
- 限流
- 扩容
- 重启
- 降级
- 摘流
建设步骤
- 第一阶段,我们要和业务一起梳理出每个业务关于上面的七种标准操作流程。
- 第二阶段,我们逐个将标准操作流程集成到预案平台,达到半自动化执行的能力。
- 第三阶段,我们可以配合故障定位平台,定位到故障种类,自动执行对应的预案,达到全自动化执行的水平,实现故障自愈。
评价体系
为了推动预案机制的落地,我们可以建立止损预案健康分体系,从预案建设覆盖度和定期演练次数,进行打分,列出排名,推动预案落地及演练。
复盘
关于复盘我们要想清楚为什么要复盘,之后再根据我们复盘的目标,总结出一个复盘模板,并持续优化迭代。
首先我们思考下,为什么要复盘,我理解主要有以下几点
- 提升业务程序的健壮性
- 优化应急响应流程
- 发挥警示作用,记录为知识库,定期回顾
- 以复盘为契机,提高业务对稳定性的重视程度
基于上面复盘的目的,我们可以整理出下面的复盘模板
- 整理故障发生到结束的整个时间线上发生的事情
- 记录从故障发生到发现、从发现到定位、从定位到止损花费的时间,思考如何减少这些时间
- 记录导致故障的原因是什么,根因是什么
- 思考后续如何避免类似的问题
- 思考处理流程有哪些优化的地方
- 思考辅助平台有哪些可以优化的地方
- 输出后续整改计划,记录到公司内部的 todo 管理平台,跟踪完成情况
最后
除了从故障的整个生命周期入手来开展稳定性工作之外,我们还需要在大目标上和业务达成一致,可以推动把稳定性写到业务的 KPI 或者 OKR 中,约定好年度的不可用时长,这样后面的稳定性工作才可以更好的开展。










