目录
1 概述
(1)无监督学习
(2)聚类
(3)K-Mean均值算法
2 K-Mean均值算法
2.1 引入
2.2 针对大样本集的改进算法:Mini Batch K-Means
2.3 图像
3 案例1
3.1 代码
3.2 结果
4 案例2
4.1 案例——数据
4.2 代码
4.3 结果
4.4 拓展&&改进
5 参考
1 概述
(1)无监督学习
在一个典型的监督学习中,我们有一个有标签的训练集,我们的目标是找到能够区分正
样本和负样本的决策边界,在这里的监督学习中,我们有一系列标签,我们需要据此拟合一
个假设函数。与此不同的是,在非监督学习中,我们的数据没有附带任何标签,我们拿到的
数据就是这样的:
(2)聚类
(3)K-Mean均值算法
2 K-Mean均值算法
2.1 引入
K- 均值 是最普及的聚类算法,算法接受一个未标记的数据集,然后将数据聚类成不同的
组
步骤:
- 设定 K 个类别的中心的初值;
- 计算每个样本到 K个中心的距离,按最近距离进行分类;
- 以每个类别中样本的均值,更新该类别的中心;
- 重复迭代以上步骤,直到达到终止条件(迭代次数、最小平方误差、簇中心点变化率)。
- 下面是一个聚类示例:
K-means聚类算法
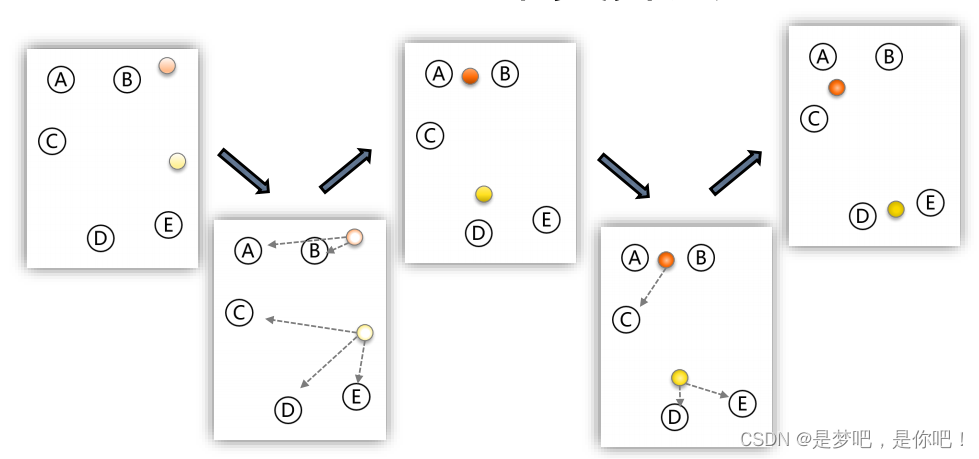
K-均值算法的伪代码如下:
Repeat {
for i = 1 to m
c(i) := index (form 1 to K) of cluster centroid closest to x(i)
for k = 1 to K
μk := average (mean) of points assigned to cluster k
}
算法分为两个步骤,第一个 for 循环是赋值步骤,即:对于每一个样例 i ,计算其应该属
于的类。第二个 for 循环是聚类中心的移动,即:对于每一个类K ,重新计算该类的质心。
from sklearn.cluster import KMeans # 导入 sklearn.cluster.KMeans 类
import numpy as np
X = np.array([[1,2], [1,4], [1,0], [10,2], [10,4], [10,0]])
kmCluster = KMeans(n_clusters=2).fit(X) # 建立模型并进行聚类,设定 K=2
print("聚类中心坐标:",kmCluster.cluster_centers_) # 返回每个聚类中心的坐标
print("分类结果:",kmCluster.labels_) # 返回样本集的分类结果
print("显示预测判断:",kmCluster.predict([[0, 0], [12, 3]])) # 根据模型聚类结果进行预测判断
聚类中心坐标: [[10. 2.]
[ 1. 2.]]
分类结果: [1 1 1 0 0 0]
显示预测判断: [1 0]
Process finished with exit code 0
2.2 针对大样本集的改进算法:Mini Batch K-Means
对于样本集巨大的问题,例如样本量大于 10万、特征变量大于100,K-Means算法耗费的速度和内存很大。SKlearn 提供了针对大样本集的改进算法 Mini Batch K-Means,并不使用全部样本数据,而是每次抽样选取小样本集进行 K-Means聚类,进行循环迭代。Mini Batch K-Means 虽然性能略有降低,但极大的提高了运行速度和内存占用。
from sklearn.cluster import MiniBatchKMeans # 导入 .MiniBatchKMeans 类
import numpy as np
X = np.array([[1,2], [1,4], [1,0], [4,2], [4,0], [4,4],
[4,5], [0,1], [2,2],[3,2], [5,5], [1,-1]])
# fit on the whole data
mbkmCluster = MiniBatchKMeans(n_clusters=3,batch_size=6,max_iter=10).fit(X)
print("聚类中心的坐标:",mbkmCluster.cluster_centers_) # 返回每个聚类中心的坐标
print("样本集的分类结果:",mbkmCluster.labels_) # 返回样本集的分类结果
print("显示判断结果:样本属于哪个类别:",mbkmCluster.predict([[0,0], [4,5]])) # 根据模型聚类结果进行预测判断
聚类中心的坐标: [[ 2.55932203 1.76271186]
[ 0.75862069 -0.20689655]
[ 4.20588235 4.5 ]]
样本集的分类结果: [0 0 1 0 0 2 2 1 0 0 2 1]
显示判断结果:样本属于哪个类别: [1 2]
Process finished with exit code 0
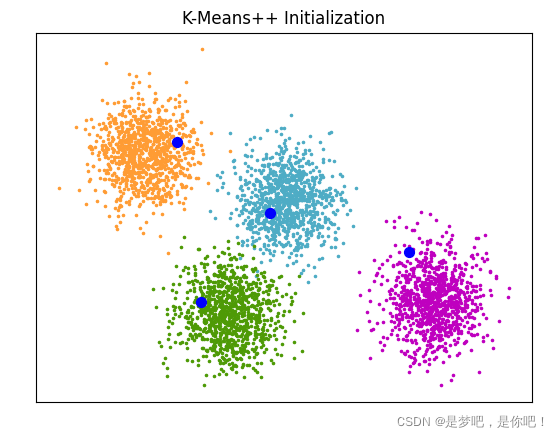
2.3 图像
from sklearn.cluster import kmeans_plusplus
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# Generate sample data
n_samples = 4000
n_components = 4
X, y_true = make_blobs(
n_samples=n_samples, centers=n_components, cluster_std=0.60, random_state=0
)
X = X[:, ::-1]
# Calculate seeds from kmeans++
centers_init, indices = kmeans_plusplus(X, n_clusters=4, random_state=0)
# Plot init seeds along side sample data
plt.figure(1)
colors = ["#4EACC5", "#FF9C34", "#4E9A06", "m"]
for k, col in enumerate(colors):
cluster_data = y_true == k
plt.scatter(X[cluster_data, 0], X[cluster_data, 1], c=col, marker=".", s=10)
plt.scatter(centers_init[:, 0], centers_init[:, 1], c="b", s=50)
plt.title("K-Means++ Initialization")
plt.xticks([])
plt.yticks([])
plt.show()
sklearn中的make_blobs的用法
3 案例1
3.1 代码
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans, MiniBatchKMeans
def main():
# 读取数据文件
file = pd.read_excel('K-Means.xlsx', header=0) # 首行为标题行
file = file.dropna() # 删除含有缺失值的数据
# print(file.dtypes) # 查看 df 各列的数据类型
# print(file.shape) # 查看 df 的行数和列数
print(file.head())
# 数据准备
z_scaler = lambda x:(x-np.mean(x))/np.std(x) # 定义数据标准化函数
dfScaler = file[['D1','D2','D3','D4','D5','D6','D7','D8','D9','D10']].apply(z_scaler) # 数据归一化
dfData = pd.concat([file[['地区']], dfScaler], axis=1) # 列级别合并
df = dfData.loc[:,['D1','D2','D3','D4','D5','D6','D7','D8','D9','D10']] # 基于全部 10个特征聚类分析
# df = dfData.loc[:,['D1','D2','D7','D8','D9','D10']] # 降维后选取 6个特征聚类分析
X = np.array(df) # 准备 sklearn.cluster.KMeans 模型数据
print("Shape of cluster data:", X.shape)
# KMeans 聚类分析(sklearn.cluster.KMeans)
nCluster = 4
kmCluster = KMeans(n_clusters=nCluster).fit(X) # 建立模型并进行聚类,设定 K=4
print("Cluster centers:\n", kmCluster.cluster_centers_) # 返回每个聚类中心的坐标
print("Cluster results:\n", kmCluster.labels_) # 返回样本集的分类结果
# 整理聚类结果(太棒啦!)
listName = dfData['地区'].tolist() # 将 dfData 的首列 '地区' 转换为 list
dictCluster = dict(zip(listName,kmCluster.labels_)) # 将 listName 与聚类结果关联,组成字典
listCluster = [[] for k in range(nCluster)]
for v in range(0, len(dictCluster)):
k = list(dictCluster.values())[v] # 第v个城市的分类是 k
listCluster[k].append(list(dictCluster.keys())[v]) # 将第v个城市添加到 第k类
print("\n聚类分析结果(分为{}类):".format(nCluster)) # 返回样本集的分类结果
for k in range(nCluster):
print("第 {} 类:{}".format(k, listCluster[k])) # 显示第 k 类的结果
return
if __name__ == '__main__':
main()
(1)python中apply函数
(2)Pandas中DataFrame数据合并、连接(concat、merge、join)
(3)Python pandas 中loc函数的意思及用法,及跟iloc的区别
(4)tolist函数 其他形式(数组或者矩阵等)转为列表形式
(5)利用zip函数将两个列表(list)组成字典(dict)
3.2 结果
地区 D1 D2 D3 D4 D5 D6 D7 D8 D9 D10
0 北京 5.96 310 461 1557 931 319 44.36 2615 2.20 13631
1 上海 3.39 234 308 1035 498 161 35.02 3052 0.90 12665
2 天津 2.35 157 229 713 295 109 38.40 3031 0.86 9385
3 陕西 1.35 81 111 364 150 58 30.45 2699 1.22 7881
4 辽宁 1.50 88 128 421 144 58 34.30 2808 0.54 7733
Shape of cluster data: (30, 10)
Cluster centers:
[[-3.04626787e-01 -2.89307971e-01 -2.90845727e-01 -2.88480032e-01
-2.85445404e-01 -2.85283077e-01 -6.22770669e-02 1.12938023e-03
-2.71308432e-01 -3.03408599e-01]
[ 4.44318512e+00 3.97251590e+00 4.16079449e+00 4.20994153e+00
4.61768098e+00 4.65296699e+00 2.45321197e+00 4.02147595e-01
4.22779099e+00 2.44672575e+00]
[ 1.52987871e+00 2.10479182e+00 1.97836141e+00 1.92037518e+00
1.54974999e+00 1.50344182e+00 1.13526879e+00 1.13595799e+00
8.39397483e-01 1.38149832e+00]
[ 4.17353928e-01 -6.60092295e-01 -5.55528420e-01 -5.50211065e-01
-2.95600461e-01 -2.42490616e-01 -3.10454580e+00 -2.70342746e+00
1.14743326e+00 2.67890118e+00]]
Cluster results:
[1 2 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 0 0 0 0 0]
聚类分析结果(分为4类):
第 0 类:['陕西', '辽宁', '吉林', '黑龙江', '湖北', '江苏', '广东', '四川', '山东', '甘肃', '湖南', '浙江', '新疆', '福建', '山西', '河北', '安徽', '云南', '江西', '海南', '内蒙古', '河南', '广西', '宁夏', '贵州', '青海']
第 1 类:['北京']
第 2 类:['上海', '天津']
第 3 类:['西藏']
Process finished with exit code 0
4 案例2
4.1 案例——数据
(1)数据介绍:
现有1999年全国31个省份城镇居民家庭平均每人全年消费性支出的八个主要变量数据,这八个变量分别是:食品、衣着、家庭设备用品及服务、医疗保健、交通和通讯、娱乐教育文化服务、居住以及杂项商品和服务。利用已有数据,对31个省份进行聚类。
(2)实验目的:
通过聚类,了解 1999 年各个省份的消费水平在国内的情况
1999年全国31个省份城镇居民家庭平均每人全年消费性支出数据
4.4 拓展&&改进
计算两条数据相似性时,Sklearn 的K-Means默认用的是欧式距离。虽然还有余弦相似度,马氏距离等多种方法,但没有设定计算距离方法的参数。
5 参考










